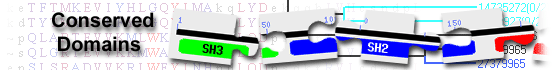|
Name |
Accession |
Description |
Interval |
E-value |
| LRRFIP |
pfam09738 |
LRRFIP family; LRRFIP1 is a transcriptional repressor which preferentially binds to the ... |
275-629 |
6.28e-102 |
|
LRRFIP family; LRRFIP1 is a transcriptional repressor which preferentially binds to the GC-rich consensus sequence (5'- AGCCCCCGGCG-3') and may regulate expression of TNF, EGFR and PDGFA. LRRFIP2 may function as activator of the canonical Wnt signalling pathway, in association with DVL3, upstream of CTNNB1/beta-catenin.
Pssm-ID: 462869 [Multi-domain] Cd Length: 303 Bit Score: 314.33 E-value: 6.28e-102
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 275 LDEKSDKQYAENYT---------RPSSRNSASATTPLSGNSSRRGSGDTSSLIDPDTSLSELRDiydlkdqiqdvegrym 345
Cdd:pfam09738 30 VEENADRVFDMSSSsgadtasgsPTASTTSAGTLNSLGGTSSRRSSEDSSISLEDEGSLRDIKH---------------- 93
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 346 qglkelkeSLSEVEEKYKKAMVSNAQLDNEKNNLIYQVDTLKDVIEEQEEQMAEFYRENEEKSKELERQKHMCSVLQHKM 425
Cdd:pfam09738 94 --------ELKEVEEKYRKAMISNAQLDNEKSNLMYQVDLLKDKLEEMEESLAELQRELREKNKELERLKRNLRRLQFQL 165
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 426 EELKEGLRQRDELIeekqrmqqkidtmtkevfdlqetllwkdkkigalekqkeyiaclrnerdmlreeladlqetvktgE 505
Cdd:pfam09738 166 AELKEQLKQRDELI-----------------------------------------------------------------E 180
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 506 KHGLVIIPDGTPNGDVSHEPVAGAITVVSQEAAQVLESAGEGPLDVRLRKLAGEKEELLSQIRKLKLQLEEERQ-KCSRN 584
Cdd:pfam09738 181 KHGLVIVPDENTNGEEENSPADAKRALVSVEAAEVLESAGEGSLDVRLKKLADEKEELLDEVRKLKLQLEEEKSkRNSTR 260
|
330 340 350 360
....*....|....*....|....*....|....*....|....*
gi 1370485581 585 DGTVGDLAGLQNGSDLqfIEMQRDANRQISEYKFKLSKAEQDITT 629
Cdd:pfam09738 261 SSQSPDGFGLENGSHV--IEVQREANKQISDYKFKLQKAEQEITT 303
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
302-680 |
2.00e-11 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 67.79 E-value: 2.00e-11
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 302 LSGNSSRRGSGDTSSLIDPDTSLSELRDIYDLKDQ---IQDVEGRYMQGLKELKESLSEVEEKYKKAMVSNAQLDNEKNN 378
Cdd:TIGR02169 655 MTGGSRAPRGGILFSRSEPAELQRLRERLEGLKRElssLQSELRRIENRLDELSQELSDASRKIGEIEKEIEQLEQEEEK 734
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 379 LIYQVDTLKDVIEEQEEQMAEFYRENEEKSKELERQKHMCSVLQHKMEELKEGLRQrdELIEEKQRMQQKIDtmtKEVFD 458
Cdd:TIGR02169 735 LKERLEELEEDLSSLEQEIENVKSELKELEARIEELEEDLHKLEEALNDLEARLSH--SRIPEIQAELSKLE---EEVSR 809
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 459 LQETLLWKDKKIGALEKQKEYiacLRNERDMLREELADLQETVKTGEKhglviipdgtpNGDVSHEPVAGAITVVSQEAA 538
Cdd:TIGR02169 810 IEARLREIEQKLNRLTLEKEY---LEKEIQELQEQRIDLKEQIKSIEK-----------EIENLNGKKEELEEELEELEA 875
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 539 QVLEsagegpLDVRLRKLAGEKEELLSQIRKLKL---QLEEERQKCSRNDGTVGDLAGLQNGsDLQFIEMQRDANRQISE 615
Cdd:TIGR02169 876 ALRD------LESRLGDLKKERDELEAQLRELERkieELEAQIEKKRKRLSELKAKLEALEE-ELSEIEDPKGEDEEIPE 948
|
330 340 350 360 370 380
....*....|....*....|....*....|....*....|....*....|....*....|....*
gi 1370485581 616 YKFKLSKAEQDITTLEQSISRLEGQVLRYKTAAENAEKVEDELKAEKRKLQRELRTALDKIEEME 680
Cdd:TIGR02169 949 EELSLEDVQAELQRVEEEIRALEPVNMLAIQEYEEVLKRLDELKEKRAKLEEERKAILERIEEYE 1013
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
348-679 |
8.83e-10 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 62.38 E-value: 8.83e-10
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 348 LKELKESLSEVEEKYKKAMVSNAQLDNEKNNLIYQVDTLKDVIEEQEEQMAEFYRENEEKSKELERQKHMCSVLQHKMEE 427
Cdd:TIGR02168 679 IEELEEKIEELEEKIAELEKALAELRKELEELEEELEQLRKELEELSRQISALRKDLARLEAEVEQLEERIAQLSKELTE 758
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 428 LKEglrQRDELIEEKQRMQQKIDTMTKEVFDLQETLlwkDKKIGALEKQKEYIACLRNERDMLREELADLQETVKTGEKh 507
Cdd:TIGR02168 759 LEA---EIEELEERLEEAEEELAEAEAEIEELEAQI---EQLKEELKALREALDELRAELTLLNEEAANLRERLESLER- 831
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 508 glviipdgtpngdvSHEPVAGAITVVSQEAAQVLEsagegpldvRLRKLAGEKEELLSQIRKLKLQLEE-ERQKCSRNDG 586
Cdd:TIGR02168 832 --------------RIAATERRLEDLEEQIEELSE---------DIESLAAEIEELEELIEELESELEAlLNERASLEEA 888
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 587 TVGDLAGLQN-GSDLQFIEMQR-DANRQISEYKFKLSKAEQDITTLEQSISRLEGQVL-RYKTAAENAEKVEDELKAEKR 663
Cdd:TIGR02168 889 LALLRSELEElSEELRELESKRsELRRELEELREKLAQLELRLEGLEVRIDNLQERLSeEYSLTLEEAEALENKIEDDEE 968
|
330
....*....|....*.
gi 1370485581 664 KLQRELRTALDKIEEM 679
Cdd:TIGR02168 969 EARRRLKRLENKIKEL 984
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
309-679 |
1.02e-08 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 58.91 E-value: 1.02e-08
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 309 RGSGDTSSLIdpdtsLSELRDIYDLKDQIQDVEGRYMQGLKELKESLSEVEEkYKKAMVSNAQLDNEKNNLIYQVDTLKD 388
Cdd:TIGR02168 663 GGSAKTNSSI-----LERRREIEELEEKIEELEEKIAELEKALAELRKELEE-LEEELEQLRKELEELSRQISALRKDLA 736
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 389 VIEEQEEQMAEFYRENEEKSKELERQKhmcSVLQHKMEELKEGLrqrDELIEEKQRMQQKIDTMTKEVFDLQETLLWKDK 468
Cdd:TIGR02168 737 RLEAEVEQLEERIAQLSKELTELEAEI---EELEERLEEAEEEL---AEAEAEIEELEAQIEQLKEELKALREALDELRA 810
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 469 KIGALE----KQKEYIACLRNERDMLREELADLQETVKTGEKHGLVI---IPDGTPNGDVSHEPVAGAITVV-SQEAAQV 540
Cdd:TIGR02168 811 ELTLLNeeaaNLRERLESLERRIAATERRLEDLEEQIEELSEDIESLaaeIEELEELIEELESELEALLNERaSLEEALA 890
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 541 LESAGEGPLDVRLRKLAGEKEELLSQIRKLKLQLEEERQKCSRNDGTVGDLagLQNGSDLQFIEMQrDANRQISEYKFKL 620
Cdd:TIGR02168 891 LLRSELEELSEELRELESKRSELRRELEELREKLAQLELRLEGLEVRIDNL--QERLSEEYSLTLE-EAEALENKIEDDE 967
|
330 340 350 360 370 380
....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 621 SKAEQDITTLEQSISRLeGQV-LRYKTAAENAEKVEDELKAEKRKLQRELRTALDKIEEM 679
Cdd:TIGR02168 968 EEARRRLKRLENKIKEL-GPVnLAAIEEYEELKERYDFLTAQKEDLTEAKETLEEAIEEI 1026
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
348-680 |
4.11e-08 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 56.99 E-value: 4.11e-08
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 348 LKELKESL------SEVEEKYKkamvsnaQLDNEKNNLiyQVDTLKDVIEEQEEQMAEF---YRENEEKSKELERQKHMc 418
Cdd:TIGR02168 195 LNELERQLkslerqAEKAERYK-------ELKAELREL--ELALLVLRLEELREELEELqeeLKEAEEELEELTAELQE- 264
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 419 svLQHKMEELKEGLRQRDELIEEKQR----MQQKIDTMTKEVFDLQETLLWKDKKIGALEkqkEYIACLRNERDMLREEL 494
Cdd:TIGR02168 265 --LEEKLEELRLEVSELEEEIEELQKelyaLANEISRLEQQKQILRERLANLERQLEELE---AQLEELESKLDELAEEL 339
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 495 ADLQETVKTGEKhglviipdgtpngdvSHEPVAGAITvVSQEAAQVLESAGEGpLDVRLRKLAGEKEELLSQIRKLKLQL 574
Cdd:TIGR02168 340 AELEEKLEELKE---------------ELESLEAELE-ELEAELEELESRLEE-LEEQLETLRSKVAQLELQIASLNNEI 402
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 575 EEERQKCSRNDGTVGdlaglqngsdlQFIEMQRDANRQISEYKFKLSKAEqdITTLEQSISRLEGQVLRYKTAAENAEKV 654
Cdd:TIGR02168 403 ERLEARLERLEDRRE-----------RLQQEIEELLKKLEEAELKELQAE--LEELEEELEELQEELERLEEALEELREE 469
|
330 340
....*....|....*....|....*.
gi 1370485581 655 EDELKAEKRKLQRELRTALDKIEEME 680
Cdd:TIGR02168 470 LEEAEQALDAAERELAQLQARLDSLE 495
|
|
| EnvC |
COG4942 |
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
402-651 |
1.13e-06 |
|
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 51.30 E-value: 1.13e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 402 RENEEKSKELERQkhmcsvLQHKMEELKEGLRQRDELIEEKQRMQQKIDTMTKEVFDLQETLLWKDKKIGALEKQkeyIA 481
Cdd:COG4942 23 AEAEAELEQLQQE------IAELEKELAALKKEEKALLKQLAALERRIAALARRIRALEQELAALEAELAELEKE---IA 93
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 482 CLRNERDMLREELAD-LQETVKTGEKHGL-VIIPDGTPNGDVSHEPVAGAITVVSQEAAQVLESAGEgpldvRLRKLAGE 559
Cdd:COG4942 94 ELRAELEAQKEELAElLRALYRLGRQPPLaLLLSPEDFLDAVRRLQYLKYLAPARREQAEELRADLA-----ELAALRAE 168
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 560 KEELLSQIRKLKLQLEEERQKcsrndgtvgdLAGLQNGSDlqfiEMQRDANRQISEYKFKLSKAEQDITTLEQSISRLEG 639
Cdd:COG4942 169 LEAERAELEALLAELEEERAA----------LEALKAERQ----KLLARLEKELAELAAELAELQQEAEELEALIARLEA 234
|
250
....*....|..
gi 1370485581 640 QVLRYKTAAENA 651
Cdd:COG4942 235 EAAAAAERTPAA 246
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
331-506 |
5.43e-06 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 50.06 E-value: 5.43e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 331 YDLKDQIQDVEGRymqgLKELKESLSEVEEKYKKAMVSNAQLDNEKNNLIYQVDTLKDVIEEQEEQMAEFYRENEEKSKE 410
Cdd:TIGR02168 291 YALANEISRLEQQ----KQILRERLANLERQLEELEAQLEELESKLDELAEELAELEEKLEELKEELESLEAELEELEAE 366
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 411 LErqkhmcsVLQHKMEELKEGL-RQRDELIEEKQRMQQ---KIDTMTKEVFDLQETL---------LWKDKKIGALEKQK 477
Cdd:TIGR02168 367 LE-------ELESRLEELEEQLeTLRSKVAQLELQIASlnnEIERLEARLERLEDRRerlqqeieeLLKKLEEAELKELQ 439
|
170 180
....*....|....*....|....*....
gi 1370485581 478 EYIACLRNERDMLREELADLQETVKTGEK 506
Cdd:TIGR02168 440 AELEELEEELEELQEELERLEEALEELRE 468
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
382-695 |
7.55e-06 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 49.68 E-value: 7.55e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 382 QVDTLKDVIEEQEEQMAEFYRENEEKSKELErqkhmcsvLQHKMEELK--EGLRQRDELIEEKQRMQQKIDTMTKEVFDL 459
Cdd:TIGR02169 185 NIERLDLIIDEKRQQLERLRREREKAERYQA--------LLKEKREYEgyELLKEKEALERQKEAIERQLASLEEELEKL 256
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 460 QETLLWKDKKIGALEKQKEYIAclRNERDMLREELADLQETVktGEKHGLViipdgtpngdvshEPVAGAITVVSQEAAQ 539
Cdd:TIGR02169 257 TEEISELEKRLEEIEQLLEELN--KKIKDLGEEEQLRVKEKI--GELEAEI-------------ASLERSIAEKERELED 319
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 540 vlesagegpLDVRLRKLAGEKEELLSQIRKLKLQLEEERQKCSRNDGTVGDLAGLQNG--SDLQFIEMQRDANRQ-ISEY 616
Cdd:TIGR02169 320 ---------AEERLAKLEAEIDKLLAEIEELEREIEEERKRRDKLTEEYAELKEELEDlrAELEEVDKEFAETRDeLKDY 390
|
250 260 270 280 290 300 310
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....
gi 1370485581 617 KFKLSKAEQDITTLEQSISRLEGQVLRYKTAAENAEKVEDELKAEKRKLQRELRTALDKIEEMEMTNSHLAKRLEKMKA 695
Cdd:TIGR02169 391 REKLEKLKREINELKRELDRLQEELQRLSEELADLNAAIAGIEAKINELEEEKEDKALEIKKQEWKLEQLAADLSKYEQ 469
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
334-597 |
7.89e-06 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 49.28 E-value: 7.89e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 334 KDQIQDVEGRYMQGLKELKESLSEVEEKYKKAMVSNAQLDNEKN-------NLIYQVDTLKDVIEEQEEQMAEFYRENEE 406
Cdd:TIGR02168 241 LEELQEELKEAEEELEELTAELQELEEKLEELRLEVSELEEEIEelqkelyALANEISRLEQQKQILRERLANLERQLEE 320
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 407 KSKELERQKhmcSVLQHKMEELKEGLRQRDELIEEKQRMQQKIDTMTKEVFDLQETLLWKDKKIGALEKQ----KEYIAC 482
Cdd:TIGR02168 321 LEAQLEELE---SKLDELAEELAELEEKLEELKEELESLEAELEELEAELEELESRLEELEEQLETLRSKvaqlELQIAS 397
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 483 LRNERDMLREELADLQETVktgEKHGLVIIPDGTPNGDVSHEPVAGAITVVSQEAAQVLESAGEgpLDVRLRKLAGEKEE 562
Cdd:TIGR02168 398 LNNEIERLEARLERLEDRR---ERLQQEIEELLKKLEEAELKELQAELEELEEELEELQEELER--LEEALEELREELEE 472
|
250 260 270
....*....|....*....|....*....|....*
gi 1370485581 563 LLSQIRKLKLQLEEERQKCSRNDGTVGDLAGLQNG 597
Cdd:TIGR02168 473 AEQALDAAERELAQLQARLDSLERLQENLEGFSEG 507
|
|
| PRK03918 |
PRK03918 |
DNA double-strand break repair ATPase Rad50; |
332-695 |
9.48e-06 |
|
DNA double-strand break repair ATPase Rad50;
Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 48.91 E-value: 9.48e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 332 DLKDQIQDVEGRYMQGLKELKESLSEVE---------EKYKKAMVSNAQLDNEKNNLIYQVDTLKDVIEEQEEQMAEFYR 402
Cdd:PRK03918 190 NIEELIKEKEKELEEVLREINEISSELPelreeleklEKEVKELEELKEEIEELEKELESLEGSKRKLEEKIRELEERIE 269
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 403 ENEEKSKELERQKHMCSVLQHKMEELKEGLRQRDELIEEKQRMQQKIDTMTKEVFDLQEtllwkdkKIGALEKQKEYIAC 482
Cdd:PRK03918 270 ELKKEIEELEEKVKELKELKEKAEEYIKLSEFYEEYLDELREIEKRLSRLEEEINGIEE-------RIKELEEKEERLEE 342
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 483 LRNERDMLREELADLQETVKTGEKhglviipdgtpngdvshepvAGAITVVSQEAAQVLESAGEGPLDVRLRKLAGEKEE 562
Cdd:PRK03918 343 LKKKLKELEKRLEELEERHELYEE--------------------AKAKKEELERLKKRLTGLTPEKLEKELEELEKAKEE 402
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 563 LLSQIRKLKLQLEEERQKCSRNDGTVGDLAGLQNGSDLQFIEMQRDANRQI-SEYKFKLSKAEQDITTLEQSISRL---- 637
Cdd:PRK03918 403 IEEEISKITARIGELKKEIKELKKAIEELKKAKGKCPVCGRELTEEHRKELlEEYTAELKRIEKELKEIEEKERKLrkel 482
|
330 340 350 360 370 380 390
....*....|....*....|....*....|....*....|....*....|....*....|....*....|.
gi 1370485581 638 ---------EGQVLRYKTAAENAEKVEDELKA----EKRKLQRELRTALDKIEEMEMTNSHLAKRLEKMKA 695
Cdd:PRK03918 483 relekvlkkESELIKLKELAEQLKELEEKLKKynleELEKKAEEYEKLKEKLIKLKGEIKSLKKELEKLEE 553
|
|
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
386-704 |
9.54e-06 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 49.16 E-value: 9.54e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 386 LKDVIEEQEEQM---------AEFYRENEEKSKELERQkhmcsVLQHKMEELKEGLRQRDELIEEKQRMQQKIDtmtkev 456
Cdd:COG1196 191 LEDILGELERQLeplerqaekAERYRELKEELKELEAE-----LLLLKLRELEAELEELEAELEELEAELEELE------ 259
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 457 fdlqetllwkdKKIGALEKQKEYiacLRNERDMLREELADLQEtvktgekhglviipdgtpngdvshepvagAITVVSQE 536
Cdd:COG1196 260 -----------AELAELEAELEE---LRLELEELELELEEAQA-----------------------------EEYELLAE 296
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 537 AAQvlESAGEGPLDVRLRKLAGEKEELLSQIRKLKLQLEEERQkcsrndgtvgdlaglqngsdlqfiemqrdanrQISEY 616
Cdd:COG1196 297 LAR--LEQDIARLEERRRELEERLEELEEELAELEEELEELEE--------------------------------ELEEL 342
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 617 KFKLSKAEQDITTLEQSISRLEGQVLRYKTAAENAEKVEDELKAEKRKLQRELRTALDKIEEMEMTNSHLAKRLEKMKAN 696
Cdd:COG1196 343 EEELEEAEEELEEAEAELAEAEEALLEAEAELAEAEEELEELAEELLEALRAAAELAAQLEELEEAEEALLERLERLEEE 422
|
....*...
gi 1370485581 697 RTALLAQQ 704
Cdd:COG1196 423 LEELEEAL 430
|
|
| PRK02224 |
PRK02224 |
DNA double-strand break repair Rad50 ATPase; |
332-695 |
1.42e-05 |
|
DNA double-strand break repair Rad50 ATPase;
Pssm-ID: 179385 [Multi-domain] Cd Length: 880 Bit Score: 48.50 E-value: 1.42e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 332 DLKDQIQDVE--------GRYMQGLKELKESLSEVEEKYKKAMVSNAQLD---NEKNNLIYQVDTLKDVIEEQEEQMAEF 400
Cdd:PRK02224 191 QLKAQIEEKEekdlherlNGLESELAELDEEIERYEEQREQARETRDEADevlEEHEERREELETLEAEIEDLRETIAET 270
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 401 YRENEEKSKELERQKHMCSVLqhkmEELKEGLRQRDELIE-EKQRMQQKIDTMTKEVFDLQETLLWKDKKIGALEKQKEy 479
Cdd:PRK02224 271 EREREELAEEVRDLRERLEEL----EEERDDLLAEAGLDDaDAEAVEARREELEDRDEELRDRLEECRVAAQAHNEEAE- 345
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 480 iaCLRNERDMLREELADLQETVKTGEKhglviipdGTPNGDVSHEPVAGAITVVSQEAAQVLESAGEGPldVRLRKLAGE 559
Cdd:PRK02224 346 --SLREDADDLEERAEELREEAAELES--------ELEEAREAVEDRREEIEELEEEIEELRERFGDAP--VDLGNAEDF 413
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 560 KEELLSQIRKLKLQLEEERQKCSRNDGTVGDLAGLQNGSDL----QFIEMQRDANRqISEYKFKLSKAEQDITTLEQSIS 635
Cdd:PRK02224 414 LEELREERDELREREAELEATLRTARERVEEAEALLEAGKCpecgQPVEGSPHVET-IEEDRERVEELEAELEDLEEEVE 492
|
330 340 350 360 370 380
....*....|....*....|....*....|....*....|....*....|....*....|.
gi 1370485581 636 RLEGQVLRYKTAAENAEKVEDelKAEKRKLQRELR-TALDKIEEMEMTNSHLAKRLEKMKA 695
Cdd:PRK02224 493 EVEERLERAEDLVEAEDRIER--LEERREDLEELIaERRETIEEKRERAEELRERAAELEA 551
|
|
| DR0291 |
COG1579 |
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General ... |
549-703 |
1.73e-05 |
|
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General function prediction only];
Pssm-ID: 441187 [Multi-domain] Cd Length: 236 Bit Score: 46.84 E-value: 1.73e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 549 LDVRLRKLAGEKEELLSQIRKLKLQLEEERQKCSRNDGTVGDLAglqngSDLQFIEMQ-RDANRQISEYKFKLSKA---- 623
Cdd:COG1579 15 LDSELDRLEHRLKELPAELAELEDELAALEARLEAAKTELEDLE-----KEIKRLELEiEEVEARIKKYEEQLGNVrnnk 89
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 624 -----EQDITTLEQSISRLEGQVLRYKTAAENAEKVEDELKAEKRKLQRELRTALDKIEEMEmtnSHLAKRLEKMKANRT 698
Cdd:COG1579 90 eyealQKEIESLKRRISDLEDEILELMERIEELEEELAELEAELAELEAELEEKKAELDEEL---AELEAELEELEAERE 166
|
....*
gi 1370485581 699 ALLAQ 703
Cdd:COG1579 167 ELAAK 171
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
328-703 |
1.82e-05 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 48.13 E-value: 1.82e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 328 RDIYDLKDQIQDVEgrymQGLKELKESLSEVEEKYKKAMVSNAQLDNEKNNLIYQVDTLKDVIEEQEEQM-------AEF 400
Cdd:TIGR02168 316 RQLEELEAQLEELE----SKLDELAEELAELEEKLEELKEELESLEAELEELEAELEELESRLEELEEQLetlrskvAQL 391
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 401 YRENEEKSKELERQKHMCSVLQHKMEELKEGLRQRDELIEEKQR--MQQKIDTMTKEVFDLQETLlwkDKKIGALEKQKE 478
Cdd:TIGR02168 392 ELQIASLNNEIERLEARLERLEDRRERLQQEIEELLKKLEEAELkeLQAELEELEEELEELQEEL---ERLEEALEELRE 468
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 479 YIACLRNERDMLREELA-----------------DLQETVKTGEKHGLVIIPDGTPNGD-VSHEP------------VAG 528
Cdd:TIGR02168 469 ELEEAEQALDAAERELAqlqarldslerlqenleGFSEGVKALLKNQSGLSGILGVLSElISVDEgyeaaieaalggRLQ 548
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 529 AITVVSQEAA----QVLESAGEG-----PLD-VRLRKLAGEKEELLSQIRKLKLQLEEERQKCSRNDGTVGDLAG----- 593
Cdd:TIGR02168 549 AVVVENLNAAkkaiAFLKQNELGrvtflPLDsIKGTEIQGNDREILKNIEGFLGVAKDLVKFDPKLRKALSYLLGgvlvv 628
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 594 --LQNGSDLQ--------FIEMQ--------------RDANRQISEYKFKLSKAEQDITTLEQSISRLEGQVLRYKTAAE 649
Cdd:TIGR02168 629 ddLDNALELAkklrpgyrIVTLDgdlvrpggvitggsAKTNSSILERRREIEELEEKIEELEEKIAELEKALAELRKELE 708
|
410 420 430 440 450
....*....|....*....|....*....|....*....|....*....|....
gi 1370485581 650 NAEKVEDELKAEKRKLQRELRTALDKIEEMEMTNSHLAKRLEKMKANRTALLAQ 703
Cdd:TIGR02168 709 ELEEELEQLRKELEELSRQISALRKDLARLEAEVEQLEERIAQLSKELTELEAE 762
|
|
| Mplasa_alph_rch |
TIGR04523 |
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of ... |
329-700 |
2.17e-05 |
|
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of Mycoplasma species. Members average 750 amino acids in length, including signal peptide. Sequences are predicted (Jpred 3) to be almost entirely alpha-helical. These sequences show strong periodicity (consistent with long alpha helical structures) and low complexity rich in D,E,N,Q, and K. Genes encoding these proteins are often found in tandem. The function is unknown.
Pssm-ID: 275316 [Multi-domain] Cd Length: 745 Bit Score: 47.71 E-value: 2.17e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 329 DIYDLKDQIQDVEGRYMQGLKELKESLSEVEEKYKKAMVSNAQLDNEK---NNLIYQVDTLKDVIEEQEEQMAEFYRENE 405
Cdd:TIGR04523 69 KINNSNNKIKILEQQIKDLNDKLKKNKDKINKLNSDLSKINSEIKNDKeqkNKLEVELNKLEKQKKENKKNIDKFLTEIK 148
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 406 EKSKELERQKHMCSVLQHKMEELKEglrQRDELIEEKQRMQQKIDTMTKEVFDLQETLL---WKDKKIGALEKQ----KE 478
Cdd:TIGR04523 149 KKEKELEKLNNKYNDLKKQKEELEN---ELNLLEKEKLNIQKNIDKIKNKLLKLELLLSnlkKKIQKNKSLESQiselKK 225
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 479 YIACLRNERDMLREELADLQETVKTGEKHGLVIIPDGTPNGDVSHEP---VAGAITVVSQEAAQVLEsagegpLDVRLRK 555
Cdd:TIGR04523 226 QNNQLKDNIEKKQQEINEKTTEISNTQTQLNQLKDEQNKIKKQLSEKqkeLEQNNKKIKELEKQLNQ------LKSEISD 299
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 556 LAGEKE-----ELLSQIRKLKLQLEEERQKCSRNDGTVGDLaglqnGSDLQFIEMQRD--------ANRQISEYKFKLSK 622
Cdd:TIGR04523 300 LNNQKEqdwnkELKSELKNQEKKLEEIQNQISQNNKIISQL-----NEQISQLKKELTnsesenseKQRELEEKQNEIEK 374
|
330 340 350 360 370 380 390
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*...
gi 1370485581 623 AEQDITTLEQSISRLEGQVLRYKTAAENAEKVEDELKAEKRKLQRELRTALDKIEEMEMTNSHLAKRLEKMKANRTAL 700
Cdd:TIGR04523 375 LKKENQSYKQEIKNLESQINDLESKIQNQEKLNQQKDEQIKKLQQEKELLEKEIERLKETIIKNNSEIKDLTNQDSVK 452
|
|
| YhaN |
COG4717 |
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; |
324-700 |
2.34e-05 |
|
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown];
Pssm-ID: 443752 [Multi-domain] Cd Length: 641 Bit Score: 47.84 E-value: 2.34e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 324 LSELRDIYDLKDQIQDVEGRYmqglKELKESLSEVEEKYKKAMVSNAQLDNEKNNLiyqvdtlkdvieEQEEQMAEFYRE 403
Cdd:COG4717 70 LKELKELEEELKEAEEKEEEY----AELQEELEELEEELEELEAELEELREELEKL------------EKLLQLLPLYQE 133
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 404 NEEKSKELERqkhmcsvLQHKMEELKEGLRQRDELIEEKQRMQQKIDTMTKEVFDLQETLLWKDKKigALEKQKEYIACL 483
Cdd:COG4717 134 LEALEAELAE-------LPERLEELEERLEELRELEEELEELEAELAELQEELEELLEQLSLATEE--ELQDLAEELEEL 204
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 484 RNERDMLREELADLQETVKTGEKH----------------------------GLVIIPDGTPNGDVSHEPVAGAITVV-- 533
Cdd:COG4717 205 QQRLAELEEELEEAQEELEELEEEleqleneleaaaleerlkearlllliaaALLALLGLGGSLLSLILTIAGVLFLVlg 284
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 534 ---------SQEAAQVLESAGEGPLDVRLRKLAGEK-------------------EELLSQIRKLKL------QLEEERQ 579
Cdd:COG4717 285 llallflllAREKASLGKEAEELQALPALEELEEEEleellaalglppdlspeelLELLDRIEELQEllreaeELEEELQ 364
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 580 KCSRNDGTVGDLAGLQNGSDLQFIEMQRDANRQIsEYKFKLSKAEQDITTLEQSI---------SRLEGQVLRYKTAAEN 650
Cdd:COG4717 365 LEELEQEIAALLAEAGVEDEEELRAALEQAEEYQ-ELKEELEELEEQLEELLGELeellealdeEELEEELEELEEELEE 443
|
410 420 430 440 450
....*....|....*....|....*....|....*....|....*....|....*....
gi 1370485581 651 AEKVEDELKAEKRKLQRELRT---------ALDKIEEMEMTNSHLAKRLEKMKANRTAL 700
Cdd:COG4717 444 LEEELEELREELAELEAELEQleedgelaeLLQELEELKAELRELAEEWAALKLALELL 502
|
|
| PRK03918 |
PRK03918 |
DNA double-strand break repair ATPase Rad50; |
326-697 |
2.43e-05 |
|
DNA double-strand break repair ATPase Rad50;
Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 47.75 E-value: 2.43e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 326 ELRDIYDLKDQIQDVEGRymqgLKELKESLSEVEEK---YKKAMVSNAQLDNEKNNL-IYQVDTLKDVIEEQEEQMAEFY 401
Cdd:PRK03918 329 RIKELEEKEERLEELKKK----LKELEKRLEELEERhelYEEAKAKKEELERLKKRLtGLTPEKLEKELEELEKAKEEIE 404
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 402 RENEEKSKELERQKHMCSVLQHKMEELKEGLRQ----RDELIEEKQrmQQKIDTMTKEVFDLQETLLWKDKKIGALEKQK 477
Cdd:PRK03918 405 EEISKITARIGELKKEIKELKKAIEELKKAKGKcpvcGRELTEEHR--KELLEEYTAELKRIEKELKEIEEKERKLRKEL 482
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 478 EYI-ACLRNERDMLR-EELAD-LQETVKTGEKHGLVIIPDGTPNGDVSHEPVAGaitvVSQEAAQVLESAGEG-PLDVRL 553
Cdd:PRK03918 483 RELeKVLKKESELIKlKELAEqLKELEEKLKKYNLEELEKKAEEYEKLKEKLIK----LKGEIKSLKKELEKLeELKKKL 558
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 554 RKLAGEKEELLSQIRKLKLQLEEERQKCSRN-DGTVGDLAGLQNgsdlQFIEMqRDANRQISEYKFKLSKAEQDITTLEQ 632
Cdd:PRK03918 559 AELEKKLDELEEELAELLKELEELGFESVEElEERLKELEPFYN----EYLEL-KDAEKELEREEKELKKLEEELDKAFE 633
|
330 340 350 360 370 380 390
....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 633 SISRLEGQVLRYKTAAENAEKVEDE-----LKAEKRKLQRELRTALDKIEEMEMTNSHLAKRLEKMKANR 697
Cdd:PRK03918 634 ELAETEKRLEELRKELEELEKKYSEeeyeeLREEYLELSRELAGLRAELEELEKRREEIKKTLEKLKEEL 703
|
|
| CwlO1 |
COG3883 |
Uncharacterized N-terminal coiled-coil domain of peptidoglycan hydrolase CwlO [Function ... |
329-548 |
2.79e-05 |
|
Uncharacterized N-terminal coiled-coil domain of peptidoglycan hydrolase CwlO [Function unknown];
Pssm-ID: 443091 [Multi-domain] Cd Length: 379 Bit Score: 47.13 E-value: 2.79e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 329 DIYDLKDQIQDVEGRYMQGLKELKESLSEVEEKYKKAMVSNAQLD---NEKNNLIYQVDTLKDVIEEQEEQMAEFYRENE 405
Cdd:COG3883 17 QIQAKQKELSELQAELEAAQAELDALQAELEELNEEYNELQAELEalqAEIDKLQAEIAEAEAEIEERREELGERARALY 96
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 406 EKSKE----------------LERQKHMCSVLQHKMEELKEGLRQRDELIEEKQRMQQKIDTMTKEVFDLQETllwKDKK 469
Cdd:COG3883 97 RSGGSvsyldvllgsesfsdfLDRLSALSKIADADADLLEELKADKAELEAKKAELEAKLAELEALKAELEAA---KAEL 173
|
170 180 190 200 210 220 230
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....
gi 1370485581 470 IGALEKQKEYIACLRNERDMLREELADLQETVKTGEKHGLVIIPDGTPNGDVSHEPVAGAITVVSQEAAQVLESAGEGP 548
Cdd:COG3883 174 EAQQAEQEALLAQLSAEEAAAEAQLAELEAELAAAEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAASAAGAGAA 252
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
398-681 |
2.92e-05 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 47.76 E-value: 2.92e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 398 AEFYRENEEKSKELERQKHMCSVLQHKMEELKEglrQRDELIEEKQRmQQKIDTMTKEVFDLQETLLWKDKKigALEKQK 477
Cdd:TIGR02169 166 AEFDRKKEKALEELEEVEENIERLDLIIDEKRQ---QLERLRREREK-AERYQALLKEKREYEGYELLKEKE--ALERQK 239
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 478 EYIaclRNERDMLREELADLQETVKTGEKHglviipdgtpngdvshepVAGAITVVSQEAAQVLESAGEGPLDVR--LRK 555
Cdd:TIGR02169 240 EAI---ERQLASLEEELEKLTEEISELEKR------------------LEEIEQLLEELNKKIKDLGEEEQLRVKekIGE 298
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 556 LAGEKEELLSQIRKLKLQLE----EERQKCSRNDGTVGDLAGLQngSDLQFIEMQRDA-NRQISEYKFKLSKAEQDITTL 630
Cdd:TIGR02169 299 LEAEIASLERSIAEKERELEdaeeRLAKLEAEIDKLLAEIEELE--REIEEERKRRDKlTEEYAELKEELEDLRAELEEV 376
|
250 260 270 280 290
....*....|....*....|....*....|....*....|....*....|.
gi 1370485581 631 EQSISRLEGQVLRYKTAAENAEKVEDELKAEKRKLQRELRTALDKIEEMEM 681
Cdd:TIGR02169 377 DKEFAETRDELKDYREKLEKLKREINELKRELDRLQEELQRLSEELADLNA 427
|
|
| Mplasa_alph_rch |
TIGR04523 |
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of ... |
333-704 |
3.03e-05 |
|
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of Mycoplasma species. Members average 750 amino acids in length, including signal peptide. Sequences are predicted (Jpred 3) to be almost entirely alpha-helical. These sequences show strong periodicity (consistent with long alpha helical structures) and low complexity rich in D,E,N,Q, and K. Genes encoding these proteins are often found in tandem. The function is unknown.
Pssm-ID: 275316 [Multi-domain] Cd Length: 745 Bit Score: 47.32 E-value: 3.03e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 333 LKDQIQDVEGRYMQGL-KELKESLSEVEEKYKkamvsnaQLDNEKNNLIYQVDTLKDVIEEQEEQMAEFYRENEEKSKEL 411
Cdd:TIGR04523 293 LKSEISDLNNQKEQDWnKELKSELKNQEKKLE-------EIQNQISQNNKIISQLNEQISQLKKELTNSESENSEKQREL 365
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 412 ERqkhmcsvlqhKMEELKEGLRQRDELIEEKQRMQQKIDTMTKEVFDLQETLLWKDKKIGALEKQKEYiacLRNERDMLR 491
Cdd:TIGR04523 366 EE----------KQNEIEKLKKENQSYKQEIKNLESQINDLESKIQNQEKLNQQKDEQIKKLQQEKEL---LEKEIERLK 432
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 492 EELADLQETVKTGEKhglviipdgtpngdvshepvagaitvvsQEAAqvlesagegpLDVRLRKLAGEKEELLSQIRKLK 571
Cdd:TIGR04523 433 ETIIKNNSEIKDLTN----------------------------QDSV----------KELIIKNLDNTRESLETQLKVLS 474
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 572 LQLEEERQKCSRNdgtvgdlaglqngsdlqfiemqrdanrqiseyKFKLSKAEQDITTLEQSISRLEGQVLRYKTAAENA 651
Cdd:TIGR04523 475 RSINKIKQNLEQK--------------------------------QKELKSKEKELKKLNEEKKELEEKVKDLTKKISSL 522
|
330 340 350 360 370 380
....*....|....*....|....*....|....*....|....*....|....*....|..
gi 1370485581 652 EKVEDELKAEKRKLQRELRTALDKIEEMEMTN---------SHLAKRLEKMKANRTALLAQQ 704
Cdd:TIGR04523 523 KEKIEKLESEKKEKESKISDLEDELNKDDFELkkenlekeiDEKNKEIEELKQTQKSLKKKQ 584
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
482-704 |
3.85e-05 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 47.36 E-value: 3.85e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 482 CLRNERDMLREELADLQETVKTGEKhglviipdgtpngdvshepvagAITVVSQEAAQVLEsagegpldvRLRKLAGEKE 561
Cdd:TIGR02168 674 ERRREIEELEEKIEELEEKIAELEK----------------------ALAELRKELEELEE---------ELEQLRKELE 722
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 562 ELLSQIRKLKLQLEEERQKCSRndgtVGDLAGLQNGSDLQFIEMQRDANRQISEYKFKLSKAEQDITTLEQSISRLEGQV 641
Cdd:TIGR02168 723 ELSRQISALRKDLARLEAEVEQ----LEERIAQLSKELTELEAEIEELEERLEEAEEELAEAEAEIEELEAQIEQLKEEL 798
|
170 180 190 200 210 220
....*....|....*....|....*....|....*....|....*....|....*....|...
gi 1370485581 642 LRYKTAAENAEKVEDELKAEKRKLQRELRTALDKIEEMEMTNSHLAKRLEKMKANRTALLAQQ 704
Cdd:TIGR02168 799 KALREALDELRAELTLLNEEAANLRERLESLERRIAATERRLEDLEEQIEELSEDIESLAAEI 861
|
|
| CALCOCO1 |
pfam07888 |
Calcium binding and coiled-coil domain (CALCOCO1) like; Proteins found in this family are ... |
332-506 |
5.30e-05 |
|
Calcium binding and coiled-coil domain (CALCOCO1) like; Proteins found in this family are similar to the coiled-coil transcriptional coactivator protein coexpressed by Mus musculus (CoCoA/CALCOCO1). This protein binds to a highly conserved N-terminal domain of p160 coactivators, such as GRIP1, and thus enhances transcriptional activation by a number of nuclear receptors. CALCOCO1 has a central coiled-coil region with three leucine zipper motifs, which is required for its interaction with GRIP1 and may regulate the autonomous transcriptional activation activity of the C-terminal region.
Pssm-ID: 462303 [Multi-domain] Cd Length: 488 Bit Score: 46.43 E-value: 5.30e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 332 DLKDQIQDVEgrymQGLKELKESLSEVEEKYKKAMVSNAQLDNEKNNLIYQVDTLKDVIEEQEEQMAEFYRENEEKSKEL 411
Cdd:pfam07888 77 ELESRVAELK----EELRQSREKHEELEEKYKELSASSEELSEEKDALLAQRAAHEARIRELEEDIKTLTQRVLERETEL 152
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 412 ERQKhmcsvlqhkmEELKEGLRQRDELIEEKQRMQQKIDTMTKEV----FDLQETLLWKDKKIGALEKQKEYIACLRN-- 485
Cdd:pfam07888 153 ERMK----------ERAKKAGAQRKEEEAERKQLQAKLQQTEEELrslsKEFQELRNSLAQRDTQVLQLQDTITTLTQkl 222
|
170 180
....*....|....*....|....*....
gi 1370485581 486 --------ERDMLREELADLQETVKTGEK 506
Cdd:pfam07888 223 ttahrkeaENEALLEELRSLQERLNASER 251
|
|
| Mplasa_alph_rch |
TIGR04523 |
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of ... |
332-680 |
5.80e-05 |
|
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of Mycoplasma species. Members average 750 amino acids in length, including signal peptide. Sequences are predicted (Jpred 3) to be almost entirely alpha-helical. These sequences show strong periodicity (consistent with long alpha helical structures) and low complexity rich in D,E,N,Q, and K. Genes encoding these proteins are often found in tandem. The function is unknown.
Pssm-ID: 275316 [Multi-domain] Cd Length: 745 Bit Score: 46.55 E-value: 5.80e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 332 DLKDQIQDVEGRymqgLKELKESLSEVEEKYKKAMVSNAQLDNEKNNLIYQVDTLKDVIEEQEEQMAEFYRENEEKSKEL 411
Cdd:TIGR04523 311 ELKSELKNQEKK----LEEIQNQISQNNKIISQLNEQISQLKKELTNSESENSEKQRELEEKQNEIEKLKKENQSYKQEI 386
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 412 ERQKHMCSVLQHKMEELKEGLRQRDELIEEKQRMQQKIDtmtKEVFDLQETLLWKDKKIGALEKQ----KEYIACLRNER 487
Cdd:TIGR04523 387 KNLESQINDLESKIQNQEKLNQQKDEQIKKLQQEKELLE---KEIERLKETIIKNNSEIKDLTNQdsvkELIIKNLDNTR 463
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 488 DMLREELADLQETVKTgEKHGLviipdgtpngdvshEPVAGAITVVSQEAAQVLESAGEgpLDVRLRKLAGEKEELLSQI 567
Cdd:TIGR04523 464 ESLETQLKVLSRSINK-IKQNL--------------EQKQKELKSKEKELKKLNEEKKE--LEEKVKDLTKKISSLKEKI 526
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 568 RKLKLQLEEERQKCSRNDgtvGDLAGLQNGSDLQFIEMQRDA-NRQISEYKF-------KLSKAEQDITTLEQSISRLEG 639
Cdd:TIGR04523 527 EKLESEKKEKESKISDLE---DELNKDDFELKKENLEKEIDEkNKEIEELKQtqkslkkKQEEKQELIDQKEKEKKDLIK 603
|
330 340 350 360
....*....|....*....|....*....|....*....|.
gi 1370485581 640 QVLRYKTAAENAEKVEDELKAEKRKLQRELRTALDKIEEME 680
Cdd:TIGR04523 604 EIEEKEKKISSLEKELEKAKKENEKLSSIIKNIKSKKNKLK 644
|
|
| COG4913 |
COG4913 |
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; |
549-695 |
7.40e-05 |
|
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown];
Pssm-ID: 443941 [Multi-domain] Cd Length: 1089 Bit Score: 46.06 E-value: 7.40e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 549 LDVRLRKLAGEKEELLSQIRKLKLQLEEERQKCsrnDGTVGDLAGlQNGSDLQFIEMQ-RDANRQISEYKFKLSKAEQDI 627
Cdd:COG4913 293 LEAELEELRAELARLEAELERLEARLDALREEL---DELEAQIRG-NGGDRLEQLEREiERLERELEERERRRARLEALL 368
|
90 100 110 120 130 140 150
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....
gi 1370485581 628 TTLEQSI-----------SRLEGQVLRYKTAAENAEKVEDELKAEKRKLQRELRTALDKIEEMEMTNSHLAKRLEKMKA 695
Cdd:COG4913 369 AALGLPLpasaeefaalrAEAAALLEALEEELEALEEALAEAEAALRDLRRELRELEAEIASLERRKSNIPARLLALRD 447
|
|
| Cast |
pfam10174 |
RIM-binding protein of the cytomatrix active zone; This is a family of proteins that form part ... |
346-687 |
8.74e-05 |
|
RIM-binding protein of the cytomatrix active zone; This is a family of proteins that form part of the CAZ (cytomatrix at the active zone) complex which is involved in determining the site of synaptic vesicle fusion. The C-terminus is a PDZ-binding motif that binds directly to RIM (a small G protein Rab-3A effector). The family also contains four coiled-coil domains.
Pssm-ID: 431111 [Multi-domain] Cd Length: 766 Bit Score: 45.97 E-value: 8.74e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 346 QGLKELKESLSEVEEKykkamvsnaqldneKNNLIYQVDTLKDVIEEQEEQMAE----FYRENEEKSK---ELERQKHM- 417
Cdd:pfam10174 324 QHIEVLKESLTAKEQR--------------AAILQTEVDALRLRLEEKESFLNKktkqLQDLTEEKSTlagEIRDLKDMl 389
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 418 ------CSVLQHKMEELKEGLRQRDELIEEKQR----MQQKIDTMTKEVFDLQETLLWKDKKIGALEKQKEYI-ACLRNE 486
Cdd:pfam10174 390 dvkerkINVLQKKIENLQEQLRDKDKQLAGLKErvksLQTDSSNTDTALTTLEEALSEKERIIERLKEQREREdRERLEE 469
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 487 RDMLREELADLQETVKTGEKHGL----VIIPDGTPNGDVSHEPVAGAITVVSQEAAqvLESAGEGP--LDVRLRKL---- 556
Cdd:pfam10174 470 LESLKKENKDLKEKVSALQPELTekesSLIDLKEHASSLASSGLKKDSKLKSLEIA--VEQKKEECskLENQLKKAhnae 547
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 557 --AGEKEELLSQIRKLKLQLEEERQKCSRNDGTVGDLAGL-------QNGSDLQFIEMQRDANRQISEykfkLSKAEQDI 627
Cdd:pfam10174 548 eaVRTNPEINDRIRLLEQEVARYKEESGKAQAEVERLLGIlreveneKNDKDKKIAELESLTLRQMKE----QNKKVANI 623
|
330 340 350 360 370 380
....*....|....*....|....*....|....*....|....*....|....*....|..
gi 1370485581 628 TTLEQSISRLEGQVLryktaaENAEKVEDELKAEKRKLQ-RELRTALDKI-EEMEMTNSHLA 687
Cdd:pfam10174 624 KHGQQEMKKKGAQLL------EEARRREDNLADNSQQLQlEELMGALEKTrQELDATKARLS 679
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
390-700 |
9.31e-05 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 45.83 E-value: 9.31e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 390 IEEQEEQMAEFYRENEEKSKELER------QKHMCSVLQHKMEELK--EGLRQRDELIEEKQRMQQKIDTMTKEVFDLQE 461
Cdd:TIGR02169 179 LEEVEENIERLDLIIDEKRQQLERlrrereKAERYQALLKEKREYEgyELLKEKEALERQKEAIERQLASLEEELEKLTE 258
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 462 TLLWKDKKIGALEKQKEYIAclRNERDMLREELADLQETVK--TGEKHGLV-IIPDGTPNGDVSHEPVAGAITVVSQEAA 538
Cdd:TIGR02169 259 EISELEKRLEEIEQLLEELN--KKIKDLGEEEQLRVKEKIGelEAEIASLErSIAEKERELEDAEERLAKLEAEIDKLLA 336
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 539 QVLESAGE-GPLDVRLRKLAGEKEELLSQIRKLKLQLEEERQKcsrNDGTVGDLAGLQNGSDlQFIEMQRDANRQISEYK 617
Cdd:TIGR02169 337 EIEELEREiEEERKRRDKLTEEYAELKEELEDLRAELEEVDKE---FAETRDELKDYREKLE-KLKREINELKRELDRLQ 412
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 618 FKLSKAEQDITTLEQSISRLEGQVLRYKTAAENA----EKVEDELK---AEKRKLQRELRTALDKIEEMEMTNSHLAKRL 690
Cdd:TIGR02169 413 EELQRLSEELADLNAAIAGIEAKINELEEEKEDKaleiKKQEWKLEqlaADLSKYEQELYDLKEEYDRVEKELSKLQREL 492
|
330
....*....|
gi 1370485581 691 EKMKANRTAL 700
Cdd:TIGR02169 493 AEAEAQARAS 502
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
537-704 |
1.03e-04 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 45.82 E-value: 1.03e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 537 AAQVLESAGEG--PLDVRLRKLAGEKEELLSQIRKLKLQLEEERQKCSRNDGTVGDLAGLQNgsdlQFIEMQRDANRQIS 614
Cdd:TIGR02168 230 LVLRLEELREEleELQEELKEAEEELEELTAELQELEEKLEELRLEVSELEEEIEELQKELY----ALANEISRLEQQKQ 305
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 615 EYKFKLSKAEQDITTLEQSISRLEGQVLRYKTAAENAEKVEDELKAEKRKLQRELRTALDKIEEMEMTNSHLAKRLEKMK 694
Cdd:TIGR02168 306 ILRERLANLERQLEELEAQLEELESKLDELAEELAELEEKLEELKEELESLEAELEELEAELEELESRLEELEEQLETLR 385
|
170
....*....|
gi 1370485581 695 ANRTALLAQQ 704
Cdd:TIGR02168 386 SKVAQLELQI 395
|
|
| PRK03918 |
PRK03918 |
DNA double-strand break repair ATPase Rad50; |
329-678 |
1.19e-04 |
|
DNA double-strand break repair ATPase Rad50;
Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 45.44 E-value: 1.19e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 329 DIYDLKDQIQDVEGRymqgLKELKESLSEVEE--KYKKAMVSNAQLDNEKNNLIYQVDTLKDVIEEQEEQMAEFYRENEE 406
Cdd:PRK03918 260 KIRELEERIEELKKE----IEELEEKVKELKElkEKAEEYIKLSEFYEEYLDELREIEKRLSRLEEEINGIEERIKELEE 335
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 407 KSKELERQKHMCSVLQHKMEELKEGLRQRDE---LIEEKQRMQQKIDTMTKEVFdlqetllwkDKKIGALEKQKEYIacl 483
Cdd:PRK03918 336 KEERLEELKKKLKELEKRLEELEERHELYEEakaKKEELERLKKRLTGLTPEKL---------EKELEELEKAKEEI--- 403
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 484 RNERDMLREELADLQETVKTGEKhglVIIPDGTPNGDVshePVAGAiTVVSQEAAQVLESAGEGPLDVR--LRKLAGEKE 561
Cdd:PRK03918 404 EEEISKITARIGELKKEIKELKK---AIEELKKAKGKC---PVCGR-ELTEEHRKELLEEYTAELKRIEkeLKEIEEKER 476
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 562 ELLSQIRKLKLQLEEERqKCSRNDGTVGDLAGLQNGSDLQFIEMQRDANRQISEYKFKLSKAEQDITTLEQSISRLEGQV 641
Cdd:PRK03918 477 KLRKELRELEKVLKKES-ELIKLKELAEQLKELEEKLKKYNLEELEKKAEEYEKLKEKLIKLKGEIKSLKKELEKLEELK 555
|
330 340 350
....*....|....*....|....*....|....*..
gi 1370485581 642 LRYKTAAENAEKVEDELKAEKRKLQRELRTALDKIEE 678
Cdd:PRK03918 556 KKLAELEKKLDELEEELAELLKELEELGFESVEELEE 592
|
|
| PRK03918 |
PRK03918 |
DNA double-strand break repair ATPase Rad50; |
355-693 |
1.47e-04 |
|
DNA double-strand break repair ATPase Rad50;
Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 45.05 E-value: 1.47e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 355 LSEVEEKYKKAMVSNAQLDNEKNNL---IYQVDTLKDVIEEQEEQMAEFYRENEEKSKELERQKHMCSVLQHKMEELKEG 431
Cdd:PRK03918 157 LDDYENAYKNLGEVIKEIKRRIERLekfIKRTENIEELIKEKEKELEEVLREINEISSELPELREELEKLEKEVKELEEL 236
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 432 LRQRDELIEEKQRMQQKIDTMTKEVFDLQETLLWKDKKIGALEKQ-----------KEYIAcLRNERDMLREELADLQET 500
Cdd:PRK03918 237 KEEIEELEKELESLEGSKRKLEEKIRELEERIEELKKEIEELEEKvkelkelkekaEEYIK-LSEFYEEYLDELREIEKR 315
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 501 vktgekhglviipdgtpngdvshepvagaITVVSQEAAQVLESAGEGPLDV-RLRKLAGEKEELLSQIRKLK---LQLEE 576
Cdd:PRK03918 316 -----------------------------LSRLEEEINGIEERIKELEEKEeRLEELKKKLKELEKRLEELEerhELYEE 366
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 577 ERQKCSRNDGTVGDLAGLQNGSDLQFIEMQRDANRQISEykfKLSKAEQDITTLEQSISRLEGQVLRYKTAAE-----NA 651
Cdd:PRK03918 367 AKAKKEELERLKKRLTGLTPEKLEKELEELEKAKEEIEE---EISKITARIGELKKEIKELKKAIEELKKAKGkcpvcGR 443
|
330 340 350 360
....*....|....*....|....*....|....*....|..
gi 1370485581 652 EKVEDELKAEKRKLQRELRTALDKIEEMEMTNSHLAKRLEKM 693
Cdd:PRK03918 444 ELTEEHRKELLEEYTAELKRIEKELKEIEEKERKLRKELREL 485
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
473-700 |
1.80e-04 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 45.05 E-value: 1.80e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 473 LEKQKEYIACLRNERDMLREELADLQETVKTGEKHGLviipdgtpngDVSHEPVAGAITVVSQEAAQVLESAGEGPLDVR 552
Cdd:TIGR02168 686 IEELEEKIAELEKALAELRKELEELEEELEQLRKELE----------ELSRQISALRKDLARLEAEVEQLEERIAQLSKE 755
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 553 LRKLAGEKEELLSQIRKLKLQLEEERQKCSRNDGTVGDLAGLQNGSDLQFIEMQRDANRQ----------ISEYKFKLSK 622
Cdd:TIGR02168 756 LTELEAEIEELEERLEEAEEELAEAEAEIEELEAQIEQLKEELKALREALDELRAELTLLneeaanlrerLESLERRIAA 835
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 623 AEQDITTLEQSISRLEGQVLRY----KTAAENAEKVEDELKA---EKRKLQRELRTALDKIEEMEMTNSHLAKRLEKMKA 695
Cdd:TIGR02168 836 TERRLEDLEEQIEELSEDIESLaaeiEELEELIEELESELEAllnERASLEEALALLRSELEELSEELRELESKRSELRR 915
|
....*
gi 1370485581 696 NRTAL 700
Cdd:TIGR02168 916 ELEEL 920
|
|
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
348-674 |
2.20e-04 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 44.54 E-value: 2.20e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 348 LKELKESLSEVEEKYKKAMVSNAQLDNEKNNLIYQVDTLKDVIEEQEEQM----AEFYRENEEKSKELERQKHMCSVLQH 423
Cdd:COG1196 241 LEELEAELEELEAELEELEAELAELEAELEELRLELEELELELEEAQAEEyellAELARLEQDIARLEERRRELEERLEE 320
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 424 KMEELKEGLRQRDELIEEKQRMQQKIDTMTKEVFDLQETLlwKDKKIGALEKQKEYIACLRNERDMLREELADLQEtvkt 503
Cdd:COG1196 321 LEEELAELEEELEELEEELEELEEELEEAEEELEEAEAEL--AEAEEALLEAEAELAEAEEELEELAEELLEALRA---- 394
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 504 gekhglviipdgtpngdvshepvagaitvVSQEAAQVLEsagegpLDVRLRKLAGEKEELLSQIRKLKLQLEEERQKCSR 583
Cdd:COG1196 395 -----------------------------AAELAAQLEE------LEEAEEALLERLERLEEELEELEEALAELEEEEEE 439
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 584 NDGTVGDLAGLQNGSDLQfiemQRDANRQISEYKFKLSKAEQDITTLEQSISRLEGQVLRYKTAAENAE-KVEDELKAEK 662
Cdd:COG1196 440 EEEALEEAAEEEAELEEE----EEALLELLAELLEEAALLEAALAELLEELAEAAARLLLLLEAEADYEgFLEGVKAALL 515
|
330
....*....|..
gi 1370485581 663 RKLQRELRTALD 674
Cdd:COG1196 516 LAGLRGLAGAVA 527
|
|
| Mplasa_alph_rch |
TIGR04523 |
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of ... |
332-503 |
2.42e-04 |
|
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of Mycoplasma species. Members average 750 amino acids in length, including signal peptide. Sequences are predicted (Jpred 3) to be almost entirely alpha-helical. These sequences show strong periodicity (consistent with long alpha helical structures) and low complexity rich in D,E,N,Q, and K. Genes encoding these proteins are often found in tandem. The function is unknown.
Pssm-ID: 275316 [Multi-domain] Cd Length: 745 Bit Score: 44.63 E-value: 2.42e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 332 DLKDQIQDVEGRY---MQGLKELKESLSEVEEKYKKAMVSNAQLDNEKNNLIYQVDTLKDVIEEQEEQMAEFYRENEEKS 408
Cdd:TIGR04523 465 SLETQLKVLSRSInkiKQNLEQKQKELKSKEKELKKLNEEKKELEEKVKDLTKKISSLKEKIEKLESEKKEKESKISDLE 544
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 409 KELERQK------HMCSVLQHKMEELKEgLRQRDELIEEKQR-MQQKIDTMTKEVFDLQETLLWKDKKIGALEKQ----- 476
Cdd:TIGR04523 545 DELNKDDfelkkeNLEKEIDEKNKEIEE-LKQTQKSLKKKQEeKQELIDQKEKEKKDLIKEIEEKEKKISSLEKElekak 623
|
170 180 190
....*....|....*....|....*....|...
gi 1370485581 477 KEY------IACLRNERDMLREELADLQETVKT 503
Cdd:TIGR04523 624 KENeklssiIKNIKSKKNKLKQEVKQIKETIKE 656
|
|
| EnvC |
COG4942 |
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
434-703 |
2.88e-04 |
|
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 43.60 E-value: 2.88e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 434 QRDELIEEKQRMQQKIDTMTKEVFDLQETllwKDKKIGALEKQKEYIACLRNERDMLREELADLQEtvktgekhglviip 513
Cdd:COG4942 21 AAAEAEAELEQLQQEIAELEKELAALKKE---EKALLKQLAALERRIAALARRIRALEQELAALEA-------------- 83
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 514 dgtpngdvshepvagaitvvsqeaaqvlesagegpldvRLRKLAGEKEELLSQIRKLKLQLEEERQKCSRNdGTVGDLAG 593
Cdd:COG4942 84 --------------------------------------ELAELEKEIAELRAELEAQKEELAELLRALYRL-GRQPPLAL 124
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 594 LQNGSDLQFIEMQRDANRQISEYKfklskaEQDITTLEQSISRLEGQVLRYKTAAENAEKVEDELKAEKRKLQRELRTAL 673
Cdd:COG4942 125 LLSPEDFLDAVRRLQYLKYLAPAR------REQAEELRADLAELAALRAELEAERAELEALLAELEEERAALEALKAERQ 198
|
250 260 270
....*....|....*....|....*....|
gi 1370485581 674 DKIEEMEMTNSHLAKRLEKMKANRTALLAQ 703
Cdd:COG4942 199 KLLARLEKELAELAAELAELQQEAEELEAL 228
|
|
| PRK03918 |
PRK03918 |
DNA double-strand break repair ATPase Rad50; |
348-697 |
3.09e-04 |
|
DNA double-strand break repair ATPase Rad50;
Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 44.28 E-value: 3.09e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 348 LKELKESLSEVEEKYKKAMVSNAQLDNEKNNLIYQVDTLKDVI------------EEQEEQMAEFYRENEEKSKELERQK 415
Cdd:PRK03918 393 LEELEKAKEEIEEEISKITARIGELKKEIKELKKAIEELKKAKgkcpvcgrelteEHRKELLEEYTAELKRIEKELKEIE 472
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 416 HMCSVLQHKMEELKEGLRQRDELIEEKQRMQQ--------------KIDTMTKEVFDLQETLLWKDKKIGALEKQKEYIA 481
Cdd:PRK03918 473 EKERKLRKELRELEKVLKKESELIKLKELAEQlkeleeklkkynleELEKKAEEYEKLKEKLIKLKGEIKSLKKELEKLE 552
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 482 CLRNERDMLREELADLQETVKTGEKHGLVIipdgtpnGDVSHEPVAGAItvvsqeaaQVLESAGEGPLdvRLRKLAGEKE 561
Cdd:PRK03918 553 ELKKKLAELEKKLDELEEELAELLKELEEL-------GFESVEELEERL--------KELEPFYNEYL--ELKDAEKELE 615
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 562 ELLSQIRKLKLQLEEERQKCSRNDGTVGDLAGLQNgsdlqfiemqrDANRQISEYKFKlsKAEQDITTLEQSISRLEGQV 641
Cdd:PRK03918 616 REEKELKKLEEELDKAFEELAETEKRLEELRKELE-----------ELEKKYSEEEYE--ELREEYLELSRELAGLRAEL 682
|
330 340 350 360 370
....*....|....*....|....*....|....*....|....*....|....*.
gi 1370485581 642 lryktaaENAEKVEDELKAEKRKLQRELRTALDKIEEMEMtnshLAKRLEKMKANR 697
Cdd:PRK03918 683 -------EELEKRREEIKKTLEKLKEELEEREKAKKELEK----LEKALERVEELR 727
|
|
| Myosin_tail_1 |
pfam01576 |
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and ... |
336-691 |
3.54e-04 |
|
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and four light chains it is a fundamental contractile protein found in all eukaryote cell types. This family consists of the coiled-coil myosin heavy chain tail region. The coiled-coil is composed of the tail from two molecules of myosin. These can then assemble into the macromolecular thick filament. The coiled-coil region provides the structural backbone the thick filament.
Pssm-ID: 460256 [Multi-domain] Cd Length: 1081 Bit Score: 44.01 E-value: 3.54e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 336 QIQDVEGRYMQGLKELKESLsEVEEKYKKAMVSNAQ-LDNEKNNLIYQVDTLkdvieEQEEQmaefyrENEEKSKELERQ 414
Cdd:pfam01576 346 QLQEMRQKHTQALEELTEQL-EQAKRNKANLEKAKQaLESENAELQAELRTL-----QQAKQ------DSEHKRKKLEGQ 413
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 415 khmcsvLQHKMEELKEGLRQRDELIEEKQRMQQKIDTMTKEVFDLQETLLWKDKKIGALEKQKE---------------- 478
Cdd:pfam01576 414 ------LQELQARLSESERQRAELAEKLSKLQSELESVSSLLNEAEGKNIKLSKDVSSLESQLQdtqellqeetrqklnl 487
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 479 --YIACLRNERDMLREELADLQETVKTGEKHGLviipdgtpngdvSHEPVAGAITVVSQEAAQVLESAGEGpldvrlrkl 556
Cdd:pfam01576 488 stRLRQLEDERNSLQEQLEEEEEAKRNVERQLS------------TLQAQLSDMKKKLEEDAGTLEALEEG--------- 546
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 557 ageKEELLSQIRKLKLQLEEERQKCSRNDGTVGDLAGlqngsDLQFIEMQRDANRQISEYKFKLSKAEQDITTLEQSISr 636
Cdd:pfam01576 547 ---KKRLQRELEALTQQLEEKAAAYDKLEKTKNRLQQ-----ELDDLLVDLDHQRQLVSNLEKKQKKFDQMLAEEKAIS- 617
|
330 340 350 360 370
....*....|....*....|....*....|....*....|....*....|....*
gi 1370485581 637 legqvLRYKTAAENAEKVEDELKAEKRKLQRELRTALDKIEEMEMTNSHLAKRLE 691
Cdd:pfam01576 618 -----ARYAEERDRAEAEAREKETRALSLARALEEALEAKEELERTNKQLRAEME 667
|
|
| DR0291 |
COG1579 |
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General ... |
324-456 |
4.39e-04 |
|
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General function prediction only];
Pssm-ID: 441187 [Multi-domain] Cd Length: 236 Bit Score: 42.60 E-value: 4.39e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 324 LSELRDIYD-LKDQIQDVEGRYMQGLKELKESLSEVEEKYKKAMVSNAQLDNEKNN-----LIYQVDTLKDVIEEQEEQM 397
Cdd:COG1579 33 LAELEDELAaLEARLEAAKTELEDLEKEIKRLELEIEEVEARIKKYEEQLGNVRNNkeyeaLQKEIESLKRRISDLEDEI 112
|
90 100 110 120 130 140
....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 398 AEFYRENEEKSKELERQKHMCSVLQHKMEELKEGLRQR-DELIEEKQRMQQKIDTMTKEV 456
Cdd:COG1579 113 LELMERIEELEEELAELEAELAELEAELEEKKAELDEElAELEAELEELEAEREELAAKI 172
|
|
| PRK03918 |
PRK03918 |
DNA double-strand break repair ATPase Rad50; |
399-694 |
4.81e-04 |
|
DNA double-strand break repair ATPase Rad50;
Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 43.51 E-value: 4.81e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 399 EFYRENEEKSKELERQKHMCSVLQHKMEELKEGLRQRDELIEEKQRMQQKIDTMTKEVFDLQETllwkDKKIGALEKQKE 478
Cdd:PRK03918 173 EIKRRIERLEKFIKRTENIEELIKEKEKELEEVLREINEISSELPELREELEKLEKEVKELEEL----KEEIEELEKELE 248
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 479 YiacLRNERDMLREELADLQETVKTGEKHglviipdgtpngdvshepvagaITVVSQEAAQVLESAGEGPLDVRLRKLAG 558
Cdd:PRK03918 249 S---LEGSKRKLEEKIRELEERIEELKKE----------------------IEELEEKVKELKELKEKAEEYIKLSEFYE 303
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 559 EKEELLSQIRKLKLQLEEERQKCSRNdgtvgdlaglqngsdlqfIEMQRDANRQISEYKFKLSKAEQDITTLE------Q 632
Cdd:PRK03918 304 EYLDELREIEKRLSRLEEEINGIEER------------------IKELEEKEERLEELKKKLKELEKRLEELEerhelyE 365
|
250 260 270 280 290 300
....*....|....*....|....*....|....*....|....*....|....*....|....*..
gi 1370485581 633 SISRLEGQVLRYKT--AAENAEKVEDELK-AEKRK--LQRELRTALDKIEEMEMTNSHLAKRLEKMK 694
Cdd:PRK03918 366 EAKAKKEELERLKKrlTGLTPEKLEKELEeLEKAKeeIEEEISKITARIGELKKEIKELKKAIEELK 432
|
|
| CCDC158 |
pfam15921 |
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. ... |
348-700 |
8.42e-04 |
|
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. The function is not known.
Pssm-ID: 464943 [Multi-domain] Cd Length: 1112 Bit Score: 42.80 E-value: 8.42e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 348 LKELKESLSEVEEKYKKAMVSNAQLDNEKNNLIYQVDTLKDVIEEQEEQMAEFYRENEEKSKELERQKHMCSVLQH---K 424
Cdd:pfam15921 470 LESTKEMLRKVVEELTAKKMTLESSERTVSDLTASLQEKERAIEATNAEITKLRSRVDLKLQELQHLKNEGDHLRNvqtE 549
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 425 MEELKEGLRQRDELIEekqRMQQKIDTMTKEVFDLQETllwkdkkIGALEKQKEYIACLRNERDMLREELADLQET--VK 502
Cdd:pfam15921 550 CEALKLQMAEKDKVIE---ILRQQIENMTQLVGQHGRT-------AGAMQVEKAQLEKEINDRRLELQEFKILKDKkdAK 619
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 503 TGEKHGLViipdgtpnGDVSHEPV----AG-----AITVVSQEAAQVLESAGEG---------PLDVRLRKLAGEKEELL 564
Cdd:pfam15921 620 IRELEARV--------SDLELEKVklvnAGserlrAVKDIKQERDQLLNEVKTSrnelnslseDYEVLKRNFRNKSEEME 691
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 565 SQIRKLKLQLEEERQKCSRNDGTVGDLaglqNGSDLQFIEMQRDANRQISEYKFKLSKAEQDITTLEQSISrlegqvlry 644
Cdd:pfam15921 692 TTTNKLKMQLKSAQSELEQTRNTLKSM----EGSDGHAMKVAMGMQKQITAKRGQIDALQSKIQFLEEAMT--------- 758
|
330 340 350 360 370 380
....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 645 ktaaeNAEKVEDELKAEKRKLQRELRT-ALDKIE---EMEMTNSHLAKRLEKMKANRTAL 700
Cdd:pfam15921 759 -----NANKEKHFLKEEKNKLSQELSTvATEKNKmagELEVLRSQERRLKEKVANMEVAL 813
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
328-506 |
8.96e-04 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 42.75 E-value: 8.96e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 328 RDIYDLKDQIQDVEGRYMQGLKELKESLSEVEE---KYKKAMVSNAQLDNEKNNLIYQVDTLKDVIEEQEEQMAEFYREN 404
Cdd:TIGR02169 308 RSIAEKERELEDAEERLAKLEAEIDKLLAEIEElerEIEEERKRRDKLTEEYAELKEELEDLRAELEEVDKEFAETRDEL 387
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 405 EEKSKELERQKHMCSVLQHKMEELKEGLRQRDELIEEkqrMQQKIDTMTKEVFDLQETLLWKDKKIGALEKQKEYIAclr 484
Cdd:TIGR02169 388 KDYREKLEKLKREINELKRELDRLQEELQRLSEELAD---LNAAIAGIEAKINELEEEKEDKALEIKKQEWKLEQLA--- 461
|
170 180
....*....|....*....|..
gi 1370485581 485 NERDMLREELADLQETVKTGEK 506
Cdd:TIGR02169 462 ADLSKYEQELYDLKEEYDRVEK 483
|
|
| PRK00409 |
PRK00409 |
recombination and DNA strand exchange inhibitor protein; Reviewed |
380-574 |
9.05e-04 |
|
recombination and DNA strand exchange inhibitor protein; Reviewed
Pssm-ID: 234750 [Multi-domain] Cd Length: 782 Bit Score: 42.51 E-value: 9.05e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 380 IYQVDTLK--DVI---EEQEEQMAEFYRENEEKSKELERQKhmcSVLQHKMEELKEglrQRDELIEE-KQRMQQKIDTMT 453
Cdd:PRK00409 510 LIGEDKEKlnELIaslEELERELEQKAEEAEALLKEAEKLK---EELEEKKEKLQE---EEDKLLEEaEKEAQQAIKEAK 583
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 454 KEVFDLQETLLWKDKKIGALEKQKEYIACLR--NERDMLREELADL----QETVKTGEKhglVIIPDGTPNGDVshepva 527
Cdd:PRK00409 584 KEADEIIKELRQLQKGGYASVKAHELIEARKrlNKANEKKEKKKKKqkekQEELKVGDE---VKYLSLGQKGEV------ 654
|
170 180 190 200 210
....*....|....*....|....*....|....*....|....*....|..
gi 1370485581 528 gaITVVSQEAAQVLesagEGPLDVR-----LRKLAGEKEELLSQIRKLKLQL 574
Cdd:PRK00409 655 --LSIPDDKEAIVQ----AGIMKMKvplsdLEKIQKPKKKKKKKPKTVKPKP 700
|
|
| Cast |
pfam10174 |
RIM-binding protein of the cytomatrix active zone; This is a family of proteins that form part ... |
321-693 |
9.57e-04 |
|
RIM-binding protein of the cytomatrix active zone; This is a family of proteins that form part of the CAZ (cytomatrix at the active zone) complex which is involved in determining the site of synaptic vesicle fusion. The C-terminus is a PDZ-binding motif that binds directly to RIM (a small G protein Rab-3A effector). The family also contains four coiled-coil domains.
Pssm-ID: 431111 [Multi-domain] Cd Length: 766 Bit Score: 42.50 E-value: 9.57e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 321 DTSLSEL-RDIYDLKDQIQDVEGRYMQGLKELKESLSEVE--EKYKKAMVSNA-QLDNEKNNLIYQVDTLKDVIEEQEEQ 396
Cdd:pfam10174 239 DTKISSLeRNIRDLEDEVQMLKTNGLLHTEDREEEIKQMEvyKSHSKFMKNKIdQLKQELSKKESELLALQTKLETLTNQ 318
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 397 MAEFYRENEEKSKELERQKHMCSVLQHKMEELKEGLRQRDELIEEK----QRMQQKIDTMTKEVFDLQETLLWKDKKIGA 472
Cdd:pfam10174 319 NSDCKQHIEVLKESLTAKEQRAAILQTEVDALRLRLEEKESFLNKKtkqlQDLTEEKSTLAGEIRDLKDMLDVKERKINV 398
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 473 LEKQKEyiaclrNERDMLRE---ELADLQETVKTGEKHglviipdgTPNGDVSHEPVAGAITvvsqEAAQVLEsagegpl 549
Cdd:pfam10174 399 LQKKIE------NLQEQLRDkdkQLAGLKERVKSLQTD--------SSNTDTALTTLEEALS----EKERIIE------- 453
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 550 dvRLRK-LAGEKEELLSQIRKLKLQLEEERQKCSRNDGTVGDlaglQNGSdlqFIEMQRDANRQISEYKFKLSKAEQDIT 628
Cdd:pfam10174 454 --RLKEqREREDRERLEELESLKKENKDLKEKVSALQPELTE----KESS---LIDLKEHASSLASSGLKKDSKLKSLEI 524
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 629 TLEQSI---SRLEGQVLRYKTAAENAEKVED-------------ELKAEKRKLQRELRTALDKIEEMEMTNSHLAKRLEK 692
Cdd:pfam10174 525 AVEQKKeecSKLENQLKKAHNAEEAVRTNPEindrirlleqevaRYKEESGKAQAEVERLLGILREVENEKNDKDKKIAE 604
|
.
gi 1370485581 693 M 693
Cdd:pfam10174 605 L 605
|
|
| COG2433 |
COG2433 |
Possible nuclease of RNase H fold, RuvC/YqgF family [General function prediction only]; |
604-695 |
1.10e-03 |
|
Possible nuclease of RNase H fold, RuvC/YqgF family [General function prediction only];
Pssm-ID: 441980 [Multi-domain] Cd Length: 644 Bit Score: 42.15 E-value: 1.10e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 604 EMQRDANRQISEYKFKLSKAEQDITTLEQSISRLEGQVLRYKtaAENA-------------EKVEDELKAEKRKLQRELR 670
Cdd:COG2433 385 LIEKELPEEEPEAEREKEHEERELTEEEEEIRRLEEQVERLE--AEVEeleaeleekderiERLERELSEARSEERREIR 462
|
90 100 110
....*....|....*....|....*....|....*...
gi 1370485581 671 -----TALD--------KIEEMEMTNSHLAKRLEKMKA 695
Cdd:COG2433 463 kdreiSRLDreierlerELEEERERIEELKRKLERLKE 500
|
|
| mukB |
PRK04863 |
chromosome partition protein MukB; |
321-667 |
1.65e-03 |
|
chromosome partition protein MukB;
Pssm-ID: 235316 [Multi-domain] Cd Length: 1486 Bit Score: 41.87 E-value: 1.65e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 321 DTSLSELRDIYDLKDQIQDVEGRY---MQGLKELKESLSEVEEKYKKAmvsNAQLDNEKNNLIYQvdtlkdvieEQEEQm 397
Cdd:PRK04863 286 EEALELRRELYTSRRQLAAEQYRLvemARELAELNEAESDLEQDYQAA---SDHLNLVQTALRQQ---------EKIER- 352
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 398 aefYREN-EEKSKELERQkhmcsvlqhkMEELKEGLRQRDELIEEKQRMQQKIDTMTKEVFDLQETLLWKDKKIG----- 471
Cdd:PRK04863 353 ---YQADlEELEERLEEQ----------NEVVEEADEQQEENEARAEAAEEEVDELKSQLADYQQALDVQQTRAIqyqqa 419
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 472 --ALEKQK--------------EYIACLRNERDMLREELADLQETVKtgekhglviipdgtpngdvshepvagaitvVSQ 535
Cdd:PRK04863 420 vqALERAKqlcglpdltadnaeDWLEEFQAKEQEATEELLSLEQKLS------------------------------VAQ 469
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 536 EAAQVLESAGEgpldvRLRKLAGE--KEELLSQIRKLKLQLEEERQKCSRNDGTVGDLAGLQngsdlQFIEMQRDANRQI 613
Cdd:PRK04863 470 AAHSQFEQAYQ-----LVRKIAGEvsRSEAWDVARELLRRLREQRHLAEQLQQLRMRLSELE-----QRLRQQQRAERLL 539
|
330 340 350 360 370
....*....|....*....|....*....|....*....|....*....|....*...
gi 1370485581 614 SEYKFKLSKAEQDITTLEQSISRLEGQVLRYK----TAAENAEKVEDELKAEKRKLQR 667
Cdd:PRK04863 540 AEFCKRLGKNLDDEDELEQLQEELEARLESLSesvsEARERRMALRQQLEQLQARIQR 597
|
|
| CCDC158 |
pfam15921 |
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. ... |
371-694 |
1.69e-03 |
|
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. The function is not known.
Pssm-ID: 464943 [Multi-domain] Cd Length: 1112 Bit Score: 42.03 E-value: 1.69e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 371 QLDNEKNNLIYQVDTLKDVIEEQEEQMAEFYRENEEKSKELERQKHMCSvlqhkmEELKEGLRQRDELIEEKQRMQqkiD 450
Cdd:pfam15921 307 QARNQNSMYMRQLSDLESTVSQLRSELREAKRMYEDKIEELEKQLVLAN------SELTEARTERDQFSQESGNLD---D 377
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 451 TMTKEVFDLQetllwKDKKIGALEKQKEYIACLRNER-----DMLREELADLQETVKTGEkhGLVIIPDGTPNGDVSHEP 525
Cdd:pfam15921 378 QLQKLLADLH-----KREKELSLEKEQNKRLWDRDTGnsitiDHLRRELDDRNMEVQRLE--ALLKAMKSECQGQMERQM 450
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 526 VA-----GAITVVSQEAAQvLESAGEGPLDVrLRKLAGEKEELLSQIRKLKLQLEEERQKCSRNDGTVGDLAGLQNGSDL 600
Cdd:pfam15921 451 AAiqgknESLEKVSSLTAQ-LESTKEMLRKV-VEELTAKKMTLESSERTVSDLTASLQEKERAIEATNAEITKLRSRVDL 528
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 601 QFIEMQ---------RDANRQISEYKFKLSKAEQDITTLEQSI---SRLEGQVLRyKTAAENAEKVEDELKAEKRKLQ-R 667
Cdd:pfam15921 529 KLQELQhlknegdhlRNVQTECEALKLQMAEKDKVIEILRQQIenmTQLVGQHGR-TAGAMQVEKAQLEKEINDRRLElQ 607
|
330 340 350
....*....|....*....|....*....|.
gi 1370485581 668 ELRTALD----KIEEMEMTNSHLakRLEKMK 694
Cdd:pfam15921 608 EFKILKDkkdaKIRELEARVSDL--ELEKVK 636
|
|
| SCP-1 |
pfam05483 |
Synaptonemal complex protein 1 (SCP-1); Synaptonemal complex protein 1 (SCP-1) is the major ... |
348-681 |
1.92e-03 |
|
Synaptonemal complex protein 1 (SCP-1); Synaptonemal complex protein 1 (SCP-1) is the major component of the transverse filaments of the synaptonemal complex. Synaptonemal complexes are structures that are formed between homologous chromosomes during meiotic prophase.
Pssm-ID: 114219 [Multi-domain] Cd Length: 787 Bit Score: 41.63 E-value: 1.92e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 348 LKELKESLSEVEEKYKKamvsnaqldnEKNNLIYQVDTLKDVIEEQEEQMAEF---YRENEEKSKELERQKHMCSvlqhk 424
Cdd:pfam05483 217 LKEDHEKIQHLEEEYKK----------EINDKEKQVSLLLIQITEKENKMKDLtflLEESRDKANQLEEKTKLQD----- 281
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 425 mEELKEGLRQRDELIEEKQRMQQKIDTMTKEVFDLQETLLWKDKKIGALEKQKEyiaclrnerdmlreelADLQETVKTG 504
Cdd:pfam05483 282 -ENLKELIEKKDHLTKELEDIKMSLQRSMSTQKALEEDLQIATKTICQLTEEKE----------------AQMEELNKAK 344
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 505 EKHGLVIipdgtpngdVSHEPVAGAITVVSQEAAQVLESAGE--GPLDVRLRKLAGEKEELLSQIRKLKLQLEE------ 576
Cdd:pfam05483 345 AAHSFVV---------TEFEATTCSLEELLRTEQQRLEKNEDqlKIITMELQKKSSELEEMTKFKNNKEVELEElkkila 415
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 577 ERQKCSRNDGTVGDLAGLQNGSDLQFIEMQRDANRQISEYKFKLSKaeqdITTLEQSISRlegQVLRYKTAAENAEKVED 656
Cdd:pfam05483 416 EDEKLLDEKKQFEKIAEELKGKEQELIFLLQAREKEIHDLEIQLTA----IKTSEEHYLK---EVEDLKTELEKEKLKNI 488
|
330 340
....*....|....*....|....*
gi 1370485581 657 ELKAEKRKLQRELRTALDKIEEMEM 681
Cdd:pfam05483 489 ELTAHCDKLLLENKELTQEASDMTL 513
|
|
| SCP-1 |
pfam05483 |
Synaptonemal complex protein 1 (SCP-1); Synaptonemal complex protein 1 (SCP-1) is the major ... |
390-695 |
1.94e-03 |
|
Synaptonemal complex protein 1 (SCP-1); Synaptonemal complex protein 1 (SCP-1) is the major component of the transverse filaments of the synaptonemal complex. Synaptonemal complexes are structures that are formed between homologous chromosomes during meiotic prophase.
Pssm-ID: 114219 [Multi-domain] Cd Length: 787 Bit Score: 41.63 E-value: 1.94e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 390 IEEQEEQMAEFYRENEEKSKELERQKHMCSVLQHKMEELKEGLRQRDELIEEKQRMQQKIDTMTKEVFDLQETLLWKDKK 469
Cdd:pfam05483 372 LEKNEDQLKIITMELQKKSSELEEMTKFKNNKEVELEELKKILAEDEKLLDEKKQFEKIAEELKGKEQELIFLLQAREKE 451
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 470 IGALEKQKEYIAC-----LRNERDMLRE-ELADLQETVKTGEKHGLVIipdgtPNGDVSHEPVAGAITVVSQEAAQVLES 543
Cdd:pfam05483 452 IHDLEIQLTAIKTseehyLKEVEDLKTElEKEKLKNIELTAHCDKLLL-----ENKELTQEASDMTLELKKHQEDIINCK 526
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 544 AGEGPLDVRLRKLAGEKEELLSQIRKLKLQLEEERQ--KCSRNDGTvgdlaglQNGSDLQFIEMQRDANRQISEYkfKLS 621
Cdd:pfam05483 527 KQEERMLKQIENLEEKEMNLRDELESVREEFIQKGDevKCKLDKSE-------ENARSIEYEVLKKEKQMKILEN--KCN 597
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 622 KAEQDITTLEQSISRL--EGQVLRYKTAAENAE---------KVEDELKAEKRKLQRELRTALDKIEEMEMTNSHLAKRL 690
Cdd:pfam05483 598 NLKKQIENKNKNIEELhqENKALKKKGSAENKQlnayeikvnKLELELASAKQKFEEIIDNYQKEIEDKKISEEKLLEEV 677
|
....*
gi 1370485581 691 EKMKA 695
Cdd:pfam05483 678 EKAKA 682
|
|
| EnvC |
COG4942 |
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
332-499 |
2.25e-03 |
|
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 40.90 E-value: 2.25e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 332 DLKDQIQDVEGRymqgLKELKESLSEVEEKYKKAMVSNAQLDNEKNNLIYQVDTLKDVIEEQEEQMAEFYRENEEKSKEL 411
Cdd:COG4942 24 EAEAELEQLQQE----IAELEKELAALKKEEKALLKQLAALERRIAALARRIRALEQELAALEAELAELEKEIAELRAEL 99
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 412 ERQKHMCSVL------QHKMEELKEGLRQRD--ELIEEKQRMQQKIDTMTKEVFDLQETLLWKDKKIGALEKQKEYIACL 483
Cdd:COG4942 100 EAQKEELAELlralyrLGRQPPLALLLSPEDflDAVRRLQYLKYLAPARREQAEELRADLAELAALRAELEAERAELEAL 179
|
170
....*....|....*.
gi 1370485581 484 RNERDMLREELADLQE 499
Cdd:COG4942 180 LAELEEERAALEALKA 195
|
|
| Mplasa_alph_rch |
TIGR04523 |
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of ... |
325-506 |
2.37e-03 |
|
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of Mycoplasma species. Members average 750 amino acids in length, including signal peptide. Sequences are predicted (Jpred 3) to be almost entirely alpha-helical. These sequences show strong periodicity (consistent with long alpha helical structures) and low complexity rich in D,E,N,Q, and K. Genes encoding these proteins are often found in tandem. The function is unknown.
Pssm-ID: 275316 [Multi-domain] Cd Length: 745 Bit Score: 41.16 E-value: 2.37e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 325 SELRDIYDLKDQIQDVEGRYM----------QGLKELKESLSEVEEKYKKAMVSNAQLDNEKNNLIYQ-------VDTLK 387
Cdd:TIGR04523 381 SYKQEIKNLESQINDLESKIQnqeklnqqkdEQIKKLQQEKELLEKEIERLKETIIKNNSEIKDLTNQdsvkeliIKNLD 460
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 388 DVIEEQEEQMAEFYRE-------NEEKSKELERQKHMCSVLQHKMEELKEGL----RQRDELIE-------EKQRMQQKI 449
Cdd:TIGR04523 461 NTRESLETQLKVLSRSinkikqnLEQKQKELKSKEKELKKLNEEKKELEEKVkdltKKISSLKEkieklesEKKEKESKI 540
|
170 180 190 200 210
....*....|....*....|....*....|....*....|....*....|....*..
gi 1370485581 450 DTMTKEVFDLQETLLWKDKKIGALEKQKEyIACLRNERDMLREELADLQETVKTGEK 506
Cdd:TIGR04523 541 SDLEDELNKDDFELKKENLEKEIDEKNKE-IEELKQTQKSLKKKQEEKQELIDQKEK 596
|
|
| rad50 |
TIGR00606 |
rad50; All proteins in this family for which functions are known are involvedin recombination, ... |
380-686 |
2.67e-03 |
|
rad50; All proteins in this family for which functions are known are involvedin recombination, recombinational repair, and/or non-homologous end joining.They are components of an exonuclease complex with MRE11 homologs. This family is distantly related to the SbcC family of bacterial proteins.This family is based on the phylogenomic analysis of JA Eisen (1999, Ph.D. Thesis, Stanford University).
Pssm-ID: 129694 [Multi-domain] Cd Length: 1311 Bit Score: 41.19 E-value: 2.67e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 380 IYQVDTLKDVIEEQEEQMAE------FYRENEEKSKELERQkhmCSVLQHKMEELKEGLRQRDELIEEKQRMQQKIDTMT 453
Cdd:TIGR00606 185 IKALETLRQVRQTQGQKVQEhqmelkYLKQYKEKACEIRDQ---ITSKEAQLESSREIVKSYENELDPLKNRLKEIEHNL 261
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 454 KEVFDLQETllwkdkkIGALEKQKEyiaclrnERDMLREELADLQETVKTGEKHGLviipdgtpnGDVSHEPVAgaiTVV 533
Cdd:TIGR00606 262 SKIMKLDNE-------IKALKSRKK-------QMEKDNSELELKMEKVFQGTDEQL---------NDLYHNHQR---TVR 315
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 534 SQEAAQVLESAGEGPLDVRLRKLAGEKEELLSQIRKLKLQLEEERQKCSRNDGTVGDlagLQNGSDLQFIEMQRDANRQI 613
Cdd:TIGR00606 316 EKERELVDCQRELEKLNKERRLLNQEKTELLVEQGRLQLQADRHQEHIRARDSLIQS---LATRLELDGFERGPFSERQI 392
|
250 260 270 280 290 300 310
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....
gi 1370485581 614 SEY-KFKLSKAEQDITTLEQSISRLEGQVlryKTAAENAEKVEDELKAEKRKLQRELRTALDKIEEMEMTNSHL 686
Cdd:TIGR00606 393 KNFhTLVIERQEDEAKTAAQLCADLQSKE---RLKQEQADEIRDEKKGLGRTIELKKEILEKKQEELKFVIKEL 463
|
|
| rad50 |
TIGR00606 |
rad50; All proteins in this family for which functions are known are involvedin recombination, ... |
326-700 |
3.03e-03 |
|
rad50; All proteins in this family for which functions are known are involvedin recombination, recombinational repair, and/or non-homologous end joining.They are components of an exonuclease complex with MRE11 homologs. This family is distantly related to the SbcC family of bacterial proteins.This family is based on the phylogenomic analysis of JA Eisen (1999, Ph.D. Thesis, Stanford University).
Pssm-ID: 129694 [Multi-domain] Cd Length: 1311 Bit Score: 41.19 E-value: 3.03e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 326 ELRDIYDLKDQIQDVEGRyMQGLKELKESLSEVEEKYKKAMvSNAQLDNEKNNLIY----QVDTLKDVIEEQEEqmaefy 401
Cdd:TIGR00606 452 KQEELKFVIKELQQLEGS-SDRILELDQELRKAERELSKAE-KNSLTETLKKEVKSlqneKADLDRKLRKLDQE------ 523
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 402 reNEEKSKELERQKHMCSVLQHKMEE----LKEGLRQRDELIEE------KQRMQQKIDTMTKEVFDLQETLLWKDKKIG 471
Cdd:TIGR00606 524 --MEQLNHHTTTRTQMEMLTKDKMDKdeqiRKIKSRHSDELTSLlgyfpnKKQLEDWLHSKSKEINQTRDRLAKLNKELA 601
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 472 ALEKQKEYIaclRNERDMLREELADLQETV-----KTGEKHGLVIIPDGTPNGDVSHEPVAGAITVVSQEAAQVL-ESAG 545
Cdd:TIGR00606 602 SLEQNKNHI---NNELESKEEQLSSYEDKLfdvcgSQDEESDLERLKEEIEKSSKQRAMLAGATAVYSQFITQLTdENQS 678
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 546 EGPLDVRLRKLAGEKEELLSQIR--------KLKLQLEEERQKCSRNDGTVGDLAGLQNGSDLQFIEMQ------RDANR 611
Cdd:TIGR00606 679 CCPVCQRVFQTEAELQEFISDLQsklrlapdKLKSTESELKKKEKRRDEMLGLAPGRQSIIDLKEKEIPelrnklQKVNR 758
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 612 QISEYKFKLSKAEQ-----------------DITTLEQSISRLEGQVLRYKTAAENAEKVE-----DELKAEKRKLQREL 669
Cdd:TIGR00606 759 DIQRLKNDIEEQETllgtimpeeesakvcltDVTIMERFQMELKDVERKIAQQAAKLQGSDldrtvQQVNQEKQEKQHEL 838
|
410 420 430
....*....|....*....|....*....|.
gi 1370485581 670 RTALDKIEEMEMTNSHLAKRLEKMKANRTAL 700
Cdd:TIGR00606 839 DTVVSKIELNRKLIQDQQEQIQHLKSKTNEL 869
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
328-660 |
3.41e-03 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 40.82 E-value: 3.41e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 328 RDIYDLKDQIQDVEGRYMQGLKELKESLSEVEEKYKKAMVsnaQLDNEKNNLIYQVDTLKDVIEEQEEQMAEFyrENEEK 407
Cdd:TIGR02169 251 EELEKLTEEISELEKRLEEIEQLLEELNKKIKDLGEEEQL---RVKEKIGELEAEIASLERSIAEKERELEDA--EERLA 325
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 408 SKELERQKhmcsvLQHKMEELKEGL----RQRDELIEEKQRMQQKIDTMTKEVFDLQETL-LWKDKkigaLEKQKEYIAC 482
Cdd:TIGR02169 326 KLEAEIDK-----LLAEIEELEREIeeerKRRDKLTEEYAELKEELEDLRAELEEVDKEFaETRDE----LKDYREKLEK 396
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 483 LRNERDMLREELADLQETVKTGEKHGLVIipdgtpngdvshepvagaitvvsQEAAQVLESagegpldvRLRKLAGEKEE 562
Cdd:TIGR02169 397 LKREINELKRELDRLQEELQRLSEELADL-----------------------NAAIAGIEA--------KINELEEEKED 445
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 563 LLSQIRKLKLQLEeerqkcsrndgtvgdlaglqngsdlQFIEMQRDANRQISEYKFKLSKAEQDITTLEQSISRLEGQVL 642
Cdd:TIGR02169 446 KALEIKKQEWKLE-------------------------QLAADLSKYEQELYDLKEEYDRVEKELSKLQRELAEAEAQAR 500
|
330
....*....|....*...
gi 1370485581 643 RYKTAAENAEKVEDELKA 660
Cdd:TIGR02169 501 ASEERVRGGRAVEEVLKA 518
|
|
| DR0291 |
COG1579 |
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General ... |
552-697 |
3.52e-03 |
|
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General function prediction only];
Pssm-ID: 441187 [Multi-domain] Cd Length: 236 Bit Score: 39.52 E-value: 3.52e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 552 RLRKLAGEKEELLSQIRKLKLQLEEERQKCSRNDGTVG------DLAGLQngSDLQFIEMQR-DANRQISEYKFKLSKAE 624
Cdd:COG1579 46 RLEAAKTELEDLEKEIKRLELEIEEVEARIKKYEEQLGnvrnnkEYEALQ--KEIESLKRRIsDLEDEILELMERIEELE 123
|
90 100 110 120 130 140 150
....*....|....*....|....*....|....*....|....*....|....*....|....*....|...
gi 1370485581 625 QDITTLEQSISRLEGQVLRYKTAAENAEKvedELKAEKRKLQRELRTALDKIEEmemtnsHLAKRLEKMKANR 697
Cdd:COG1579 124 EELAELEAELAELEAELEEKKAELDEELA---ELEAELEELEAEREELAAKIPP------ELLALYERIRKRK 187
|
|
| Myosin_tail_1 |
pfam01576 |
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and ... |
348-674 |
3.52e-03 |
|
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and four light chains it is a fundamental contractile protein found in all eukaryote cell types. This family consists of the coiled-coil myosin heavy chain tail region. The coiled-coil is composed of the tail from two molecules of myosin. These can then assemble into the macromolecular thick filament. The coiled-coil region provides the structural backbone the thick filament.
Pssm-ID: 460256 [Multi-domain] Cd Length: 1081 Bit Score: 40.93 E-value: 3.52e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 348 LKELKESLSEVEEKYKKAMVSNAQLDNEKNNLiyqvdtlkdviEEQEEQMAEFYRENEEKSKELERQKHMCSVLQHKME- 426
Cdd:pfam01576 14 LQKVKERQQKAESELKELEKKHQQLCEEKNAL-----------QEQLQAETELCAEAEEMRARLAARKQELEEILHELEs 82
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 427 ELKEGLRQRDELIEEKQRMQQKIDTMTKEVFD-------LQETLLWKDKKIGALEKQ----KEYIACLRNERDMLREELA 495
Cdd:pfam01576 83 RLEEEEERSQQLQNEKKKMQQHIQDLEEQLDEeeaarqkLQLEKVTTEAKIKKLEEDilllEDQNSKLSKERKLLEERIS 162
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 496 DLQETVKTGEKHGLVIIPDGTpngdvSHEPVagaitVVSQEAAQVLESAGEGPLDVRLRKLAGEKEELLSQIRKLKLQLE 575
Cdd:pfam01576 163 EFTSNLAEEEEKAKSLSKLKN-----KHEAM-----ISDLEERLKKEEKGRQELEKAKRKLEGESTDLQEQIAELQAQIA 232
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 576 EERQKCSRNDgtvgdlaglqngsdlqfiEMQRDANRQISEYKFKLSKAEQDITTLEQSISRLEGQVLRYKTAAENAEKVE 655
Cdd:pfam01576 233 ELRAQLAKKE------------------EELQAALARLEEETAQKNNALKKIRELEAQISELQEDLESERAARNKAEKQR 294
|
330
....*....|....*....
gi 1370485581 656 DELKAEKRKLQRELRTALD 674
Cdd:pfam01576 295 RDLGEELEALKTELEDTLD 313
|
|
| DUF724 |
pfam05266 |
Protein of unknown function (DUF724); This family contains several uncharacterized proteins ... |
386-463 |
4.43e-03 |
|
Protein of unknown function (DUF724); This family contains several uncharacterized proteins found in Arabidopsis thaliana and other plants. This region is often found associated with Agenet domains and may contain coiled-coil.
Pssm-ID: 428400 [Multi-domain] Cd Length: 188 Bit Score: 38.79 E-value: 4.43e-03
10 20 30 40 50 60 70
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*...
gi 1370485581 386 LKDVIEEQEEQMAEFYRENEEKSKELERQKHMCSVLQHKMEELKeglRQRDELIEEKQRMQQKIDTMTKEVFDLQETL 463
Cdd:pfam05266 100 LKDRQTKLLEELKKLEKKIAEEESEKRKLEEEIDELEKKILELE---RQLALAKEKKEAADKEIARLKSEAEKLEQEI 174
|
|
| CwlO1 |
COG3883 |
Uncharacterized N-terminal coiled-coil domain of peptidoglycan hydrolase CwlO [Function ... |
549-704 |
4.80e-03 |
|
Uncharacterized N-terminal coiled-coil domain of peptidoglycan hydrolase CwlO [Function unknown];
Pssm-ID: 443091 [Multi-domain] Cd Length: 379 Bit Score: 39.81 E-value: 4.80e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 549 LDVRLRKLAGEKEELLSQIRKLKLQLEEERQKCS-------RNDGTVGDLAGLQNGSDLQ-FIE-------MQRDANRQI 613
Cdd:COG3883 56 LQAELEALQAEIDKLQAEIAEAEAEIEERREELGeraralyRSGGSVSYLDVLLGSESFSdFLDrlsalskIADADADLL 135
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 614 SEYKFKLSKAEQDITTLEQSISRLEGQVLRYKTAAENAEKVEDELKAEKRKLQRELRTALDKIEEMEMTNSHLAKRLEKM 693
Cdd:COG3883 136 EELKADKAELEAKKAELEAKLAELEALKAELEAAKAELEAQQAEQEALLAQLSAEEAAAEAQLAELEAELAAAEAAAAAA 215
|
170
....*....|.
gi 1370485581 694 KANRTALLAQQ 704
Cdd:COG3883 216 AAAAAAAAAAA 226
|
|
| COG4026 |
COG4026 |
Uncharacterized conserved protein, contains TOPRIM domain, potential nuclease [General ... |
345-430 |
5.52e-03 |
|
Uncharacterized conserved protein, contains TOPRIM domain, potential nuclease [General function prediction only];
Pssm-ID: 443204 [Multi-domain] Cd Length: 287 Bit Score: 39.33 E-value: 5.52e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 345 MQGLKELKESLSEVEEKYKkamvsnaQLDNEKNNLIYQVDTLKDVIEEQEEQMAEFYRENEEKSKELERQKHMCSVLQHK 424
Cdd:COG4026 127 IPEYNELREELLELKEKID-------EIAKEKEKLTKENEELESELEELREEYKKLREENSILEEEFDNIKSEYSDLKSR 199
|
....*.
gi 1370485581 425 MEELKE 430
Cdd:COG4026 200 FEELLK 205
|
|
| PRK05771 |
PRK05771 |
V-type ATP synthase subunit I; Validated |
321-580 |
6.13e-03 |
|
V-type ATP synthase subunit I; Validated
Pssm-ID: 235600 [Multi-domain] Cd Length: 646 Bit Score: 39.91 E-value: 6.13e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 321 DTSLSELRD-----IYDLKDQIQDVEGR----YMQGLKELKESLSEVEEKYKKAmvsnaqldnEKNNLIYQVDTLKDVIE 391
Cdd:PRK05771 19 DEVLEALHElgvvhIEDLKEELSNERLRklrsLLTKLSEALDKLRSYLPKLNPL---------REEKKKVSVKSLEELIK 89
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 392 EQEEQMAEFYRENEEKSKELErqkhmcsvlqhkmeelkeglrqrdELIEEKQRMQQKIDTMTK-EVFDLQETLLWKDKKI 470
Cdd:PRK05771 90 DVEEELEKIEKEIKELEEEIS------------------------ELENEIKELEQEIERLEPwGNFDLDLSLLLGFKYV 145
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 471 ----GALEKQKEyiaclrnERDMLREELADLQETVKTGEKHGLVIIPDgtpngdvshepvAGAITVVSQEAAQV----LE 542
Cdd:PRK05771 146 svfvGTVPEDKL-------EELKLESDVENVEYISTDKGYVYVVVVVL------------KELSDEVEEELKKLgferLE 206
|
250 260 270
....*....|....*....|....*....|....*...
gi 1370485581 543 SAGEGPLDVRLRKLAGEKEELLSQIRKLKLQLEEERQK 580
Cdd:PRK05771 207 LEEEGTPSELIREIKEELEEIEKERESLLEELKELAKK 244
|
|
| sbcc |
TIGR00618 |
exonuclease SbcC; All proteins in this family for which functions are known are part of an ... |
326-667 |
7.07e-03 |
|
exonuclease SbcC; All proteins in this family for which functions are known are part of an exonuclease complex with sbcD homologs. This complex is involved in the initiation of recombination to regulate the levels of palindromic sequences in DNA. This family is based on the phylogenomic analysis of JA Eisen (1999, Ph.D. Thesis, Stanford University). [DNA metabolism, DNA replication, recombination, and repair]
Pssm-ID: 129705 [Multi-domain] Cd Length: 1042 Bit Score: 39.95 E-value: 7.07e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 326 ELRDIYDLKDQIQDVEGRYMQGLKELKES------LSEVEEKYKKAMVSNAQLDNEKNNLIYQVDTLKDV-----IEEQE 394
Cdd:TIGR00618 227 ELKHLREALQQTQQSHAYLTQKREAQEEQlkkqqlLKQLRARIEELRAQEAVLEETQERINRARKAAPLAahikaVTQIE 306
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 395 EQMAEFYRENEEKSKELERQKHMCSVLQHKMEELKEGLRQRDELIEEKQRMQQKID--TMTKEVFDLQETLLwkdKKIGA 472
Cdd:TIGR00618 307 QQAQRIHTELQSKMRSRAKLLMKRAAHVKQQSSIEEQRRLLQTLHSQEIHIRDAHEvaTSIREISCQQHTLT---QHIHT 383
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 473 LEKQKEYIACLRNERDMLREELADLQETVKTgekhglviiPDGTPNGDVSHEPVAGAITVVSQEAAQVLESAGEG----- 547
Cdd:TIGR00618 384 LQQQKTTLTQKLQSLCKELDILQREQATIDT---------RTSAFRDLQGQLAHAKKQQELQQRYAELCAAAITCtaqce 454
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 548 ----PLDVRLRKLAGEKEELLSQIRKLKLQLEEERQKcsrndgtvgdlaglqngsDLQFIEMQRDANRQISEYKFKLSKA 623
Cdd:TIGR00618 455 klekIHLQESAQSLKEREQQLQTKEQIHLQETRKKAV------------------VLARLLELQEEPCPLCGSCIHPNPA 516
|
330 340 350 360
....*....|....*....|....*....|....*....|....
gi 1370485581 624 EQDITTLEQSISRLEGQVLRYKTAAENAEKVEDELKAEKRKLQR 667
Cdd:TIGR00618 517 RQDIDNPGPLTRRMQRGEQTYAQLETSEEDVYHQLTSERKQRAS 560
|
|
| COG1340 |
COG1340 |
Uncharacterized coiled-coil protein, contains DUF342 domain [Function unknown]; |
402-699 |
7.63e-03 |
|
Uncharacterized coiled-coil protein, contains DUF342 domain [Function unknown];
Pssm-ID: 440951 [Multi-domain] Cd Length: 297 Bit Score: 39.12 E-value: 7.63e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 402 RENEEKSKELERQKhmcSVLQHKMEELKEglrQRDELIEEKQRMQQKIDTMTKEVFDLQEtllwkdkKIGALEKQK---- 477
Cdd:COG1340 4 DELSSSLEELEEKI---EELREEIEELKE---KRDELNEELKELAEKRDELNAQVKELRE-------EAQELREKRdeln 70
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 478 EYIACLRNERDMLREELADLQETVKTGEKHGLVIIPDGTPngdvshepvagaITVVSQEAAQVLESAGEGPLDVrlrkla 557
Cdd:COG1340 71 EKVKELKEERDELNEKLNELREELDELRKELAELNKAGGS------------IDKLRKEIERLEWRQQTEVLSP------ 132
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 558 gEKE-ELLSQIRKLKLQLEEERQKCSRNDgtvgDLAGLQNGSDLQFIEMqRDANRQISEYKFKLSKAEQDITTLEQSISR 636
Cdd:COG1340 133 -EEEkELVEKIKELEKELEKAKKALEKNE----KLKELRAELKELRKEA-EEIHKKIKELAEEAQELHEEMIELYKEADE 206
|
250 260 270 280 290 300
....*....|....*....|....*....|....*....|....*....|....*....|...
gi 1370485581 637 LEGQVLRYKTAAENAEKVEDELKAEKRKLQRELRTALDKIEEMEMTNSHLAKRLEKMKANRTA 699
Cdd:COG1340 207 LRKEADELHKEIVEAQEKADELHEEIIELQKELRELRKELKKLRKKQRALKREKEKEELEEKA 269
|
|
| SMC_N |
pfam02463 |
RecF/RecN/SMC N terminal domain; This domain is found at the N terminus of SMC proteins. The ... |
344-697 |
7.74e-03 |
|
RecF/RecN/SMC N terminal domain; This domain is found at the N terminus of SMC proteins. The SMC (structural maintenance of chromosomes) superfamily proteins have ATP-binding domains at the N- and C-termini, and two extended coiled-coil domains separated by a hinge in the middle. The eukaryotic SMC proteins form two kind of heterodimers: the SMC1/SMC3 and the SMC2/SMC4 types. These heterodimers constitute an essential part of higher order complexes, which are involved in chromatin and DNA dynamics. This family also includes the RecF and RecN proteins that are involved in DNA metabolism and recombination.
Pssm-ID: 426784 [Multi-domain] Cd Length: 1161 Bit Score: 39.57 E-value: 7.74e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 344 YMQGLKELKESLSEVEEKYKKAMVSNAQLDNEKNNLIYQVDTLKDVIEEQEEQMAEFYRENEEKSKELERQKHMCSVLQH 423
Cdd:pfam02463 168 KRKKKEALKKLIEETENLAELIIDLEELKLQELKLKEQAKKALEYYQLKEKLELEEEYLLYLDYLKLNEERIDLLQELLR 247
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 424 KMEELKEGLRQRDELIEEKQRMQQKIDTMTKEVFDLQETllWKDKKIGALEKQKEYIACLRNERDMLREELADLQETVKT 503
Cdd:pfam02463 248 DEQEEIESSKQEIEKEEEKLAQVLKENKEEEKEKKLQEE--ELKLLAKEEEELKSELLKLERRKVDDEEKLKESEKEKKK 325
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 504 GEKHglviipdgtpngdvshepvagaitvVSQEAAQVLESAGEGPLDVRLRKLAGEKEELLSQIRKLKLQLEEERQ--KC 581
Cdd:pfam02463 326 AEKE-------------------------LKKEKEEIEELEKELKELEIKREAEEEEEEELEKLQEKLEQLEEELLakKK 380
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 582 SRNDGTVGDLAGL-QNGSDLQFIEMQRDANRQISEYKFKLSKAEQDITTLEQSISRLEGQVLRYKTAAENAEKVEDELKA 660
Cdd:pfam02463 381 LESERLSSAAKLKeEELELKSEEEKEAQLLLELARQLEDLLKEEKKEELEILEEEEESIELKQGKLTEEKEELEKQELKL 460
|
330 340 350
....*....|....*....|....*....|....*..
gi 1370485581 661 EKRKLQRELRTALDKIEEMEMTNSHLAKRLEKMKANR 697
Cdd:pfam02463 461 LKDELELKKSEDLLKETQLVKLQEQLELLLSRQKLEE 497
|
|
| EzrA |
pfam06160 |
Septation ring formation regulator, EzrA; During the bacterial cell cycle, the tubulin-like ... |
328-503 |
8.09e-03 |
|
Septation ring formation regulator, EzrA; During the bacterial cell cycle, the tubulin-like cell-division protein FtsZ polymerizes into a ring structure that establishes the location of the nascent division site. EzrA modulates the frequency and position of FtsZ ring formation. The structure contains 5 spectrin like alpha helical repeats.
Pssm-ID: 428797 [Multi-domain] Cd Length: 542 Bit Score: 39.45 E-value: 8.09e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 328 RDIYDLKDQIQDVEGRY---MQGLKELKESLSEVEEKYKKAMVSNAQLDNE--KNNLIY--QVDTLKDVIEEQEEQMAEF 400
Cdd:pfam06160 86 KALDEIEELLDDIEEDIkqiLEELDELLESEEKNREEVEELKDKYRELRKTllANRFSYgpAIDELEKQLAEIEEEFSQF 165
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 401 YRENE-----EKSKELERQKHMCSVLQHKMEELKEGLRQ-RDELIEEKQRMQQKIDTMTKEVFDLQETLLwkDKKIGALE 474
Cdd:pfam06160 166 EELTEsgdylEAREVLEKLEEETDALEELMEDIPPLYEElKTELPDQLEELKEGYREMEEEGYALEHLNV--DKEIQQLE 243
|
170 180 190
....*....|....*....|....*....|.
gi 1370485581 475 KQ-KEYIACLRN-ERDMLREELADLQETVKT 503
Cdd:pfam06160 244 EQlEENLALLENlELDEAEEALEEIEERIDQ 274
|
|
| COG2433 |
COG2433 |
Possible nuclease of RNase H fold, RuvC/YqgF family [General function prediction only]; |
385-507 |
8.17e-03 |
|
Possible nuclease of RNase H fold, RuvC/YqgF family [General function prediction only];
Pssm-ID: 441980 [Multi-domain] Cd Length: 644 Bit Score: 39.46 E-value: 8.17e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 385 TLKDVIEEQEEqmaefyrenEEKSKELERQKHMCSVLQHKMEELKEGLRQRDELIEEKQrmqqkidtmtKEVFDLQETLL 464
Cdd:COG2433 377 SIEEALEELIE---------KELPEEEPEAEREKEHEERELTEEEEEIRRLEEQVERLE----------AEVEELEAELE 437
|
90 100 110 120 130
....*....|....*....|....*....|....*....|....*....|....*..
gi 1370485581 465 WKDKKIGALE------KQKEY--------IACLRNERDMLREELADLQETVKTGEKH 507
Cdd:COG2433 438 EKDERIERLErelseaRSEERreirkdreISRLDREIERLERELEEERERIEELKRK 494
|
|
| DUF4201 |
pfam13870 |
Domain of unknown function (DUF4201); This is a family of coiled-coil proteins from eukaryotes. ... |
405-502 |
8.95e-03 |
|
Domain of unknown function (DUF4201); This is a family of coiled-coil proteins from eukaryotes. The function is not known.
Pssm-ID: 464008 [Multi-domain] Cd Length: 177 Bit Score: 37.97 E-value: 8.95e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 405 EEKSKELERQKHMCSVLQHKMEELKEglrQRDELIEEKQRMQQKIDTMTKEVFDLQETLL-------WKDKKIGALEKQK 477
Cdd:pfam13870 59 EERNKELKRLKLKVTNTVHALTHLKE---KLHFLSAELSRLKKELRERQELLAKLRKELYrvklerdKLRKQNKKLRQQG 135
|
90 100 110
....*....|....*....|....*....|....*
gi 1370485581 478 E----------YIAClRNERDMLREELADLQETVK 502
Cdd:pfam13870 136 GllhvpallhdYDKT-KAEVEEKRKSVKKLRRKVK 169
|
|
| rad50 |
TIGR00606 |
rad50; All proteins in this family for which functions are known are involvedin recombination, ... |
348-508 |
9.63e-03 |
|
rad50; All proteins in this family for which functions are known are involvedin recombination, recombinational repair, and/or non-homologous end joining.They are components of an exonuclease complex with MRE11 homologs. This family is distantly related to the SbcC family of bacterial proteins.This family is based on the phylogenomic analysis of JA Eisen (1999, Ph.D. Thesis, Stanford University).
Pssm-ID: 129694 [Multi-domain] Cd Length: 1311 Bit Score: 39.26 E-value: 9.63e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 348 LKELKESLSEVEEKYKKAMvsnAQLDNEKNNLIYQvdTLKDVIEEQEEQMAEFYRENEEKSKELERQKHMCSVLQHKMEE 427
Cdd:TIGR00606 794 MERFQMELKDVERKIAQQA---AKLQGSDLDRTVQ--QVNQEKQEKQHELDTVVSKIELNRKLIQDQQEQIQHLKSKTNE 868
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1370485581 428 LKEGLRQRDELIEEKQRMQQKIDTMTKEVFDLQETLLWKDKKIGALE--------KQKEYIACLRNERDMLREELADLQE 499
Cdd:TIGR00606 869 LKSEKLQIGTNLQRRQQFEEQLVELSTEVQSLIREIKDAKEQDSPLEtflekdqqEKEELISSKETSNKKAQDKVNDIKE 948
|
....*....
gi 1370485581 500 TVKtgEKHG 508
Cdd:TIGR00606 949 KVK--NIHG 955
|
|
| |