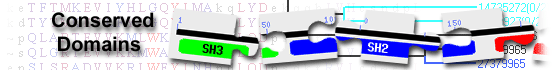|
Name |
Accession |
Description |
Interval |
E-value |
| Filament |
pfam00038 |
Intermediate filament protein; |
55-366 |
8.91e-133 |
|
Intermediate filament protein;
Pssm-ID: 459643 [Multi-domain] Cd Length: 313 Bit Score: 383.12 E-value: 8.91e-133
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 55 SEKETMQFLNDRLASYLEKVRQLERDNAELENLIRERSQQQEPLLCPSYQSYFKTIEELQQKILCSKSENARLVVQIDNA 134
Cdd:pfam00038 1 NEKEQLQELNDRLASYIDKVRFLEQQNKLLETKISELRQKKGAEPSRLYSLYEKEIEDLRRQLDTLTVERARLQLELDNL 80
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 135 KLAADDFRTKYQTEQSLRQLVESDINSLRRILDELTLCRSDLEAQMESLKEELLSLKQNHEQEVNTLRCQLGD-RLNVEV 213
Cdd:pfam00038 81 RLAAEDFRQKYEDELNLRTSAENDLVGLRKDLDEATLARVDLEAKIESLKEELAFLKKNHEEEVRELQAQVSDtQVNVEM 160
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 214 DAAPAVDLNQVLNETRNQYEALVETNRREVEQWFATQTEELNKQVVSSSEQLQSYQAEIIELRRTVNALEIELQAQHNLR 293
Cdd:pfam00038 161 DAARKLDLTSALAEIRAQYEEIAAKNREEAEEWYQSKLEELQQAAARNGDALRSAKEEITELRRTIQSLEIELQSLKKQK 240
|
250 260 270 280 290 300 310
....*....|....*....|....*....|....*....|....*....|....*....|....*....|...
gi 10337581 294 YSLENTLTESEARYSSQLSQVQSLITNVESQLAEIRSDLERQNQEYQVLLDVRARLECEINTYRSLLESEDCK 366
Cdd:pfam00038 241 ASLERQLAETEERYELQLADYQELISELEAELQETRQEMARQLREYQELLNVKLALDIEIATYRKLLEGEECR 313
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
110-362 |
1.24e-12 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 69.70 E-value: 1.24e-12
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 110 IEELQQKILCSKSENARLVVQIDNAKLAADDFRTKYQTEQSLRQLVESDINSLRRILDELTLCRSDLEAQMESLKEELLS 189
Cdd:TIGR02168 234 LEELREELEELQEELKEAEEELEELTAELQELEEKLEELRLEVSELEEEIEELQKELYALANEISRLEQQKQILRERLAN 313
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 190 LKQNHEqEVNTLRCQLGDRLnvEVDAAPAVDLNQVLNETRNQYEALVETNRREVEQWFA---------TQTEELNKQVVS 260
Cdd:TIGR02168 314 LERQLE-ELEAQLEELESKL--DELAEELAELEEKLEELKEELESLEAELEELEAELEElesrleeleEQLETLRSKVAQ 390
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 261 SSEQLQSYQAEIIELRRTVNALEIELQAQHNLRYSLENTLTESE-ARYSSQLSQVQSLITNVESQLAEIRSDLERQNQEY 339
Cdd:TIGR02168 391 LELQIASLNNEIERLEARLERLEDRRERLQQEIEELLKKLEEAElKELQAELEELEEELEELQEELERLEEALEELREEL 470
|
250 260
....*....|....*....|...
gi 10337581 340 QVLLDVRARLECEINTYRSLLES 362
Cdd:TIGR02168 471 EEAEQALDAAERELAQLQARLDS 493
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
73-350 |
1.41e-11 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 66.62 E-value: 1.41e-11
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 73 KVRQLERDNAELENLIRERSQQQEPLLcpsyqsyfKTIEELQQKILCSKSENARLVVQIDNAKLAADDFRTKYQTEQSLR 152
Cdd:TIGR02168 678 EIEELEEKIEELEEKIAELEKALAELR--------KELEELEEELEQLRKELEELSRQISALRKDLARLEAEVEQLEERI 749
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 153 QLVESDINSLRRILDELTLCRSDLEAQMESLKEELLSLKQ---NHEQEVNTLRCQLgDRLNVEVDAapavdlnqvLNETR 229
Cdd:TIGR02168 750 AQLSKELTELEAEIEELEERLEEAEEELAEAEAEIEELEAqieQLKEELKALREAL-DELRAELTL---------LNEEA 819
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 230 NQYEALVETNRREVEQWfATQTEELNKQVVSSSEQLQSYQAEIIELRRTVNALEIELQAQHNLRYSLENTLTESEARYSS 309
Cdd:TIGR02168 820 ANLRERLESLERRIAAT-ERRLEDLEEQIEELSEDIESLAAEIEELEELIEELESELEALLNERASLEEALALLRSELEE 898
|
250 260 270 280
....*....|....*....|....*....|....*....|.
gi 10337581 310 QLSQVQslitNVESQLAEIRSDLERQNQEyqvLLDVRARLE 350
Cdd:TIGR02168 899 LSEELR----ELESKRSELRRELEELREK---LAQLELRLE 932
|
|
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
66-350 |
1.76e-10 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 63.03 E-value: 1.76e-10
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 66 RLASYLEKVRQLERDNAELENLIRERSQQQEpllcpsyqsyfkTIEELQQkilcsksenarlvvQIDNAKLAADDFRTKY 145
Cdd:COG1196 230 LLLKLRELEAELEELEAELEELEAELEELEA------------ELAELEA--------------ELEELRLELEELELEL 283
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 146 QTEQSLRQLVESDINSLRRILDELTLCRSDLEAQMESLKEELLSLKQNHEQEVNTLRCQLGDRLNVEVDAApavDLNQVL 225
Cdd:COG1196 284 EEAQAEEYELLAELARLEQDIARLEERRRELEERLEELEEELAELEEELEELEEELEELEEELEEAEEELE---EAEAEL 360
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 226 NETRNQYEALVETNRREVEQWFA---------TQTEELNKQVVSSSEQLQSYQAEIIELRRTVNALEIELQAQHNLRYSL 296
Cdd:COG1196 361 AEAEEALLEAEAELAEAEEELEElaeellealRAAAELAAQLEELEEAEEALLERLERLEEELEELEEALAELEEEEEEE 440
|
250 260 270 280 290
....*....|....*....|....*....|....*....|....*....|....
gi 10337581 297 ENTLTESEARYSSQLSQVQSLITNVESQLAEIRSDLERQNQEYQVLLDVRARLE 350
Cdd:COG1196 441 EEALEEAAEEEAELEEEEEALLELLAELLEEAALLEAALAELLEELAEAAARLL 494
|
|
| GumC |
COG3206 |
Exopolysaccharide export protein/domain GumC/Wzc1 [Cell wall/membrane/envelope biogenesis]; |
146-350 |
4.46e-09 |
|
Exopolysaccharide export protein/domain GumC/Wzc1 [Cell wall/membrane/envelope biogenesis];
Pssm-ID: 442439 [Multi-domain] Cd Length: 687 Bit Score: 58.49 E-value: 4.46e-09
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 146 QTEQSLRQLvESDINSLRR---ILDeLTLCRSDLEAQMESLKEELLSLkQNHEQEVNTLRCQLGDRLNVEVDAAPAVDLN 222
Cdd:COG3206 186 ELRKELEEA-EAALEEFRQkngLVD-LSEEAKLLLQQLSELESQLAEA-RAELAEAEARLAALRAQLGSGPDALPELLQS 262
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 223 QVLNETRNQYEALvetnRREVEQWFATQTEElNKQVVSSSEQLQSYQAEI-IELRRTVNALEIELQAQHnlrySLENTLT 301
Cdd:COG3206 263 PVIQQLRAQLAEL----EAELAELSARYTPN-HPDVIALRAQIAALRAQLqQEAQRILASLEAELEALQ----AREASLQ 333
|
170 180 190 200
....*....|....*....|....*....|....*....|....*....
gi 10337581 302 ESEARYSSQLSQVQSLitnvESQLAEIRSDLERQNQEYQVLLdvrARLE 350
Cdd:COG3206 334 AQLAQLEARLAELPEL----EAELRRLEREVEVARELYESLL---QRLE 375
|
|
| GumC |
COG3206 |
Exopolysaccharide export protein/domain GumC/Wzc1 [Cell wall/membrane/envelope biogenesis]; |
176-362 |
4.58e-09 |
|
Exopolysaccharide export protein/domain GumC/Wzc1 [Cell wall/membrane/envelope biogenesis];
Pssm-ID: 442439 [Multi-domain] Cd Length: 687 Bit Score: 58.10 E-value: 4.58e-09
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 176 LEAQMESLKEELLSLkqnhEQEVNTLRCQLGDrLNVEVDAAPAV----DLNQVLNETRNQYEALvETNRREVEQWFATQT 251
Cdd:COG3206 180 LEEQLPELRKELEEA----EAALEEFRQKNGL-VDLSEEAKLLLqqlsELESQLAEARAELAEA-EARLAALRAQLGSGP 253
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 252 EELNKqvVSSSEQLQSYQAEIIELRRTVNALEIELQAQH----NLRYSLENTLTESEARYSSQLSQVQSLITNVESQLAE 327
Cdd:COG3206 254 DALPE--LLQSPVIQQLRAQLAELEAELAELSARYTPNHpdviALRAQIAALRAQLQQEAQRILASLEAELEALQAREAS 331
|
170 180 190
....*....|....*....|....*....|....*...
gi 10337581 328 IRSDLERQNQEYQVLLDVRA---RLECEINTYRSLLES 362
Cdd:COG3206 332 LQAQLAQLEARLAELPELEAelrRLEREVEVARELYES 369
|
|
| EnvC |
COG4942 |
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
98-353 |
4.96e-09 |
|
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 57.47 E-value: 4.96e-09
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 98 LLCPSYQSYFKTIEELQQKIlcsksenARLVVQIDNAKLAADDFRTKYQTEQSLRQLVESDINSLRRILDELTLCRSDLE 177
Cdd:COG4942 10 LLALAAAAQADAAAEAEAEL-------EQLQQEIAELEKELAALKKEEKALLKQLAALERRIAALARRIRALEQELAALE 82
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 178 AQMESLKEELLSLKQNHEQEVNTLRCQLGDRLNVEVDAAPAVDLNQvlnetrnqyEALVETNRREveQWFATQTEELNKQ 257
Cdd:COG4942 83 AELAELEKEIAELRAELEAQKEELAELLRALYRLGRQPPLALLLSP---------EDFLDAVRRL--QYLKYLAPARREQ 151
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 258 VvsssEQLQSYQAEIIELRRTVNALEIELQAqhnlrysLENTLTESEARYSSQLSQVQSLITNVESQLAEIRSDLERQNQ 337
Cdd:COG4942 152 A----EELRADLAELAALRAELEAERAELEA-------LLAELEEERAALEALKAERQKLLARLEKELAELAAELAELQQ 220
|
250
....*....|....*.
gi 10337581 338 EYQVLLDVRARLECEI 353
Cdd:COG4942 221 EAEELEALIARLEAEA 236
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
48-283 |
9.26e-09 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 57.37 E-value: 9.26e-09
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 48 CEGSFNGSEKEtMQFLNDRLASYLEKVRQLERDNAELENLIRERSQQQEPLLcPSYQSYFKTIEELQQKILCSKSENARL 127
Cdd:TIGR02168 265 LEEKLEELRLE-VSELEEEIEELQKELYALANEISRLEQQKQILRERLANLE-RQLEELEAQLEELESKLDELAEELAEL 342
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 128 V-------VQIDNAKLAADDFRTKYQTEQSLRQLVESDINSLRRILDELTLCRSDLEAQMESLKEELLSLKQNHEQEVNT 200
Cdd:TIGR02168 343 EekleelkEELESLEAELEELEAELEELESRLEELEEQLETLRSKVAQLELQIASLNNEIERLEARLERLEDRRERLQQE 422
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 201 LRCQLGDRLNVEVDAAPA--VDLNQVLNETRNQYEALVETNRREVEqwfatQTEELNKQVVSSSEQLQSYQAEIIELRRT 278
Cdd:TIGR02168 423 IEELLKKLEEAELKELQAelEELEEELEELQEELERLEEALEELRE-----ELEEAEQALDAAERELAQLQARLDSLERL 497
|
....*
gi 10337581 279 VNALE 283
Cdd:TIGR02168 498 QENLE 502
|
|
| COG4913 |
COG4913 |
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; |
65-360 |
4.43e-08 |
|
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown];
Pssm-ID: 443941 [Multi-domain] Cd Length: 1089 Bit Score: 55.31 E-value: 4.43e-08
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 65 DRLASYLEKVRQLERDNAELENLIRERSQQQEPL--------LCPSYQSYFKTIEELQQKIlcsksenARLVVQIDNAKL 136
Cdd:COG4913 610 AKLAALEAELAELEEELAEAEERLEALEAELDALqerrealqRLAEYSWDEIDVASAEREI-------AELEAELERLDA 682
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 137 AADDFRtkyQTEQSLRQLvESDINSLRRILDELTLCRSDLEAQMESLKEELLSLKQNHEqevntlrcqlgdrlnvEVDAA 216
Cdd:COG4913 683 SSDDLA---ALEEQLEEL-EAELEELEEELDELKGEIGRLEKELEQAEEELDELQDRLE----------------AAEDL 742
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 217 PAVDLNQVLNETRNQyeALVETNRREVEQWFATQTEELNKQVVSSSEQL--------QSYQAEIIELRRTVNALEiELQA 288
Cdd:COG4913 743 ARLELRALLEERFAA--ALGDAVERELRENLEERIDALRARLNRAEEELeramrafnREWPAETADLDADLESLP-EYLA 819
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 289 QHNlrySLENT-LTESEARYSSQLSQ-----VQSLITNVESQLAEIRSDLERQNQE-----------YQvlLDVRARLEC 351
Cdd:COG4913 820 LLD---RLEEDgLPEYEERFKELLNEnsiefVADLLSKLRRAIREIKERIDPLNDSlkripfgpgryLR--LEARPRPDP 894
|
....*....
gi 10337581 352 EINTYRSLL 360
Cdd:COG4913 895 EVREFRQEL 903
|
|
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
56-316 |
7.51e-08 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 54.56 E-value: 7.51e-08
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 56 EKETMQFLNDRLASYLEKVR----QLERDNAELENLIRERSQQQEpllcpSYQSYFKTIEELQQKILCSKSENARLVVQI 131
Cdd:COG1196 244 LEAELEELEAELEELEAELAeleaELEELRLELEELELELEEAQA-----EEYELLAELARLEQDIARLEERRRELEERL 318
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 132 DNAKLAADDFRTKYQTEQSLRQLVESDINSLRRILDELTLCRSDLEAQMESLKEELLSLKQNHEQEVNTLRCQLGDRLNV 211
Cdd:COG1196 319 EELEEELAELEEELEELEEELEELEEELEEAEEELEEAEAELAEAEEALLEAEAELAEAEEELEELAEELLEALRAAAEL 398
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 212 EVDAAPAVDLNQVLNETRNQYEALVETNRREVEQwFATQTEELNKQVVSSSEQLQSYQAEIIELRRTVNALEIELQAQHN 291
Cdd:COG1196 399 AAQLEELEEAEEALLERLERLEEELEELEEALAE-LEEEEEEEEEALEEAAEEEAELEEEEEALLELLAELLEEAALLEA 477
|
250 260
....*....|....*....|....*
gi 10337581 292 LRYSLENTLTESEARYSSQLSQVQS 316
Cdd:COG1196 478 ALAELLEELAEAAARLLLLLEAEAD 502
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
143-361 |
8.96e-08 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 54.29 E-value: 8.96e-08
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 143 TKYQT--EQSLRQLVESDINslrriLDELTLCRSDLEAQMESLK---EELLSLKQNHEQEVNTLRCQLGDRLNVEVDAAP 217
Cdd:TIGR02168 168 SKYKErrKETERKLERTREN-----LDRLEDILNELERQLKSLErqaEKAERYKELKAELRELELALLVLRLEELREELE 242
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 218 AvdLNQVLNETRNQYEALvETNRREVEqwfaTQTEELNKQVVSSSEQLQSYQAEIIELRRTVNALEIELQAQhnlrysle 297
Cdd:TIGR02168 243 E--LQEELKEAEEELEEL-TAELQELE----EKLEELRLEVSELEEEIEELQKELYALANEISRLEQQKQIL-------- 307
|
170 180 190 200 210 220
....*....|....*....|....*....|....*....|....*....|....*....|....
gi 10337581 298 ntlTESEARYSSQLSQVQSLITNVESQLAEIRSDLERQNQEYQVLLDVRARLECEINTYRSLLE 361
Cdd:TIGR02168 308 ---RERLANLERQLEELEAQLEELESKLDELAEELAELEEKLEELKEELESLEAELEELEAELE 368
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
111-358 |
1.26e-07 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 53.91 E-value: 1.26e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 111 EELQQKILCSKSENARLVVQIDNAKLAADDFRTKYQTEQSLRQLVESDINSLRRILDELtlcrsdlEAQMESLKEELLSL 190
Cdd:TIGR02168 666 AKTNSSILERRREIEELEEKIEELEEKIAELEKALAELRKELEELEEELEQLRKELEEL-------SRQISALRKDLARL 738
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 191 KQNHEQEVNTLRCQLGDRLNVEVDAAPAVDLNQVLNETRNQYEALVETNRREVEQwFATQTEELNKQVVSSSEQLQSYQA 270
Cdd:TIGR02168 739 EAEVEQLEERIAQLSKELTELEAEIEELEERLEEAEEELAEAEAEIEELEAQIEQ-LKEELKALREALDELRAELTLLNE 817
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 271 EIIELRRTVNALEIELQAQHNLRYSLENT---LTESEARYSSQLSQVQSLITNVESQLAEIRSDLERQNQEYQVLLDVRA 347
Cdd:TIGR02168 818 EAANLRERLESLERRIAATERRLEDLEEQieeLSEDIESLAAEIEELEELIEELESELEALLNERASLEEALALLRSELE 897
|
250
....*....|.
gi 10337581 348 RLECEINTYRS 358
Cdd:TIGR02168 898 ELSEELRELES 908
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
71-367 |
2.66e-07 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 52.76 E-value: 2.66e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 71 LEKVRQLERDNAELENLIRERSQQQEPLL-----CPSYQSYFKTIEELQQKILCSKSENArlvvqidnaklaaddfrtky 145
Cdd:TIGR02169 176 LEELEEVEENIERLDLIIDEKRQQLERLRrerekAERYQALLKEKREYEGYELLKEKEAL-------------------- 235
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 146 qtEQSLRQlVESDINSLRRILDELTLCRSDLEAQMESLKEEL----LSLKQNHEQEVNTLRCQLGDrLNVEV---DAAPA 218
Cdd:TIGR02169 236 --ERQKEA-IERQLASLEEELEKLTEEISELEKRLEEIEQLLeelnKKIKDLGEEEQLRVKEKIGE-LEAEIaslERSIA 311
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 219 VDLNQV--LNETRNQYEALVETNRREVEQwFATQTEELNKQVVSSSEQLQSYQAEIIELRRTVNALEIELQA----QHNL 292
Cdd:TIGR02169 312 EKERELedAEERLAKLEAEIDKLLAEIEE-LEREIEEERKRRDKLTEEYAELKEELEDLRAELEEVDKEFAEtrdeLKDY 390
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 293 RYSLENTLTEseaRYSSQ--LSQVQSLITNVESQLAEIRSDLER----QNQEYQVLLDVRARL---ECEINTYRSLLESE 363
Cdd:TIGR02169 391 REKLEKLKRE---INELKreLDRLQEELQRLSEELADLNAAIAGieakINELEEEKEDKALEIkkqEWKLEQLAADLSKY 467
|
....
gi 10337581 364 DCKL 367
Cdd:TIGR02169 468 EQEL 471
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
60-328 |
4.33e-07 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 52.37 E-value: 4.33e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 60 MQFLNDRLASYLEKVRQLERDNAELENLIRERSQQQEPLlcpsyQSYF----KTIEELQQKILCSKSENARLVVQIDNAK 135
Cdd:TIGR02168 234 LEELREELEELQEELKEAEEELEELTAELQELEEKLEEL-----RLEVseleEEIEELQKELYALANEISRLEQQKQILR 308
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 136 -----LAADDFRTKYQTEQSLRQLVES----------------DINSLRRILDELTLCRSDLEAQMESLKEELLSLKQN- 193
Cdd:TIGR02168 309 erlanLERQLEELEAQLEELESKLDELaeelaeleekleelkeELESLEAELEELEAELEELESRLEELEEQLETLRSKv 388
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 194 --HEQEVNTLRCQLGdRLNVEVDAApAVDLNQVLNETRNQYEALVETNRREVEQWFATQTEELNK---QVVSSSEQLQSY 268
Cdd:TIGR02168 389 aqLELQIASLNNEIE-RLEARLERL-EDRRERLQQEIEELLKKLEEAELKELQAELEELEEELEElqeELERLEEALEEL 466
|
250 260 270 280 290 300
....*....|....*....|....*....|....*....|....*....|....*....|..
gi 10337581 269 QAEIIELRRTVNALEIELQAQHNLRYSLENTLT--ESEARYSSQLSQVQSLITNVESQLAEI 328
Cdd:TIGR02168 467 REELEEAEQALDAAERELAQLQARLDSLERLQEnlEGFSEGVKALLKNQSGLSGILGVLSEL 528
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
72-377 |
5.97e-07 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 51.60 E-value: 5.97e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 72 EKVRQLERDNAEL---ENLIRERSQQQEPL-----LCPSYQSYFKTIEELQQKILCSKSEnaRLVVQIDNAKLAADDFRT 143
Cdd:TIGR02168 176 ETERKLERTRENLdrlEDILNELERQLKSLerqaeKAERYKELKAELRELELALLVLRLE--ELREELEELQEELKEAEE 253
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 144 KYQTEQSLRQLVESDINSLRRILDELtlcrsdlEAQMESLKEELLSLKQnheqEVNTLRCQLgdrlnvevdaapavdlnQ 223
Cdd:TIGR02168 254 ELEELTAELQELEEKLEELRLEVSEL-------EEEIEELQKELYALAN----EISRLEQQK-----------------Q 305
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 224 VLNETRNQyealVETNRREVEqwfaTQTEELNKQVVSSSEQLQSYQAEIIELRRTVNALEIELQAQHNLRYSLENTLTES 303
Cdd:TIGR02168 306 ILRERLAN----LERQLEELE----AQLEELESKLDELAEELAELEEKLEELKEELESLEAELEELEAELEELESRLEEL 377
|
250 260 270 280 290 300 310
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....
gi 10337581 304 EAryssQLSQVQSLITNVESQLAEIRSDLERQNQEYQVLLDVRARLECEINTYRSLLESEDCKLPSNPCATTNA 377
Cdd:TIGR02168 378 EE----QLETLRSKVAQLELQIASLNNEIERLEARLERLEDRRERLQQEIEELLKKLEEAELKELQAELEELEE 447
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
56-359 |
6.07e-07 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 51.61 E-value: 6.07e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 56 EKETMQFLNDRL--ASYLEKVRQLERDNAELENLIRERSQQQEpllcpsyqsyfkTIEELQQKIlcskSENARLVVQIdN 133
Cdd:TIGR02169 209 KAERYQALLKEKreYEGYELLKEKEALERQKEAIERQLASLEE------------ELEKLTEEI----SELEKRLEEI-E 271
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 134 AKLAADDFRTKYQTEQSLRQL------VESDINSLRRILDELTLCRSDLEAQMESLKEELLSLKQNHE------QEVNTL 201
Cdd:TIGR02169 272 QLLEELNKKIKDLGEEEQLRVkekigeLEAEIASLERSIAEKERELEDAEERLAKLEAEIDKLLAEIEelereiEEERKR 351
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 202 RCQLGDRLNvevdaapavDLNQVLNETRNQYEALVETNRReveqWFatqteelnkqvvsssEQLQSYQAEIIELRRTVNA 281
Cdd:TIGR02169 352 RDKLTEEYA---------ELKEELEDLRAELEEVDKEFAE----TR---------------DELKDYREKLEKLKREINE 403
|
250 260 270 280 290 300 310
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*...
gi 10337581 282 LEIELQAQHNLRYSLENTLTESEARYSSQLSQVQSLITNVESQLAEIRSDLERQNQEYQVLLDVRARLECEINTYRSL 359
Cdd:TIGR02169 404 LKRELDRLQEELQRLSEELADLNAAIAGIEAKINELEEEKEDKALEIKKQEWKLEQLAADLSKYEQELYDLKEEYDRV 481
|
|
| EnvC |
COG4942 |
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
108-335 |
6.26e-07 |
|
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 50.92 E-value: 6.26e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 108 KTIEELQQKILCSKSENARLVVQIDNAKLAADDFRTKYQTEQSLRQLVESDINSLRRILDELTLCRSDLEAQMESLKEEL 187
Cdd:COG4942 27 AELEQLQQEIAELEKELAALKKEEKALLKQLAALERRIAALARRIRALEQELAALEAELAELEKEIAELRAELEAQKEEL 106
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 188 LslkqnhEQEVNTLRCQLGDRLNVEVDAAPAVDLNQVLnetrNQYEALVETNRREVEQWFATQTE--ELNKQVVSSSEQL 265
Cdd:COG4942 107 A------ELLRALYRLGRQPPLALLLSPEDFLDAVRRL----QYLKYLAPARREQAEELRADLAElaALRAELEAERAEL 176
|
170 180 190 200 210 220 230
....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 266 QSYQAEIIELRRtvnaleiELQAQHNLRYSLENTLTESEARYSSQLSQVQSLITNVESQLAEIRSDLERQ 335
Cdd:COG4942 177 EALLAELEEERA-------ALEALKAERQKLLARLEKELAELAAELAELQQEAEELEALIARLEAEAAAA 239
|
|
| Myosin_tail_1 |
pfam01576 |
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and ... |
56-361 |
1.59e-06 |
|
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and four light chains it is a fundamental contractile protein found in all eukaryote cell types. This family consists of the coiled-coil myosin heavy chain tail region. The coiled-coil is composed of the tail from two molecules of myosin. These can then assemble into the macromolecular thick filament. The coiled-coil region provides the structural backbone the thick filament.
Pssm-ID: 460256 [Multi-domain] Cd Length: 1081 Bit Score: 50.56 E-value: 1.59e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 56 EKETMQFLNDRLASYLEKVRQLERDNAELEN----LIRERSQQQEPLlcPSYQSYFKTIEELQQKILCSKSEnARLVVQI 131
Cdd:pfam01576 3 QEEEMQAKEEELQKVKERQQKAESELKELEKkhqqLCEEKNALQEQL--QAETELCAEAEEMRARLAARKQE-LEEILHE 79
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 132 DNAKLAADDFRTkyQTEQSLRQLVESDINSLRRILDE-------LTLCRSDLEAQMESLKEELLSLkQNHEQEVNTLRCQ 204
Cdd:pfam01576 80 LESRLEEEEERS--QQLQNEKKKMQQHIQDLEEQLDEeeaarqkLQLEKVTTEAKIKKLEEDILLL-EDQNSKLSKERKL 156
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 205 LGDRLN-VEVDAAPAVDLNQVLNETRNQYEALV----------ETNRREVEQWfatqTEELNKQVVSSSEQLQSYQAEII 273
Cdd:pfam01576 157 LEERISeFTSNLAEEEEKAKSLSKLKNKHEAMIsdleerlkkeEKGRQELEKA----KRKLEGESTDLQEQIAELQAQIA 232
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 274 ELRRTVNALEIELQAqhnlrysLENTLTESEARYSSQLSQVQSLitnvESQLAEIRSDLERQNQEYQVLLDVRARLECEI 353
Cdd:pfam01576 233 ELRAQLAKKEEELQA-------ALARLEEETAQKNNALKKIREL----EAQISELQEDLESERAARNKAEKQRRDLGEEL 301
|
....*...
gi 10337581 354 NTYRSLLE 361
Cdd:pfam01576 302 EALKTELE 309
|
|
| COG4913 |
COG4913 |
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; |
110-335 |
1.62e-06 |
|
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown];
Pssm-ID: 443941 [Multi-domain] Cd Length: 1089 Bit Score: 50.30 E-value: 1.62e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 110 IEELQQKIlcsksenARLVVQIDNAKLAADDFRtkYQTEQSLRQLVESDINSLRRILDELTLCRSDLEAQMESLKEELLS 189
Cdd:COG4913 257 IRELAERY-------AAARERLAELEYLRAALR--LWFAQRRLELLEAELEELRAELARLEAELERLEARLDALREELDE 327
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 190 LKQNHEQevntlrcQLGDRLNvevdaapavDLNQVLNETRNQYEAlVETNRREVEQWFATqteeLNKQVVSSSEQLQSYQ 269
Cdd:COG4913 328 LEAQIRG-------NGGDRLE---------QLEREIERLERELEE-RERRRARLEALLAA----LGLPLPASAEEFAALR 386
|
170 180 190 200 210 220
....*....|....*....|....*....|....*....|....*....|....*....|....*....
gi 10337581 270 AeiiELRRTVNALEIELQAQHNLRYSLENTLTESEARY---SSQLSQVQSLITNVESQLAEIRSDLERQ 335
Cdd:COG4913 387 A---EAAALLEALEEELEALEEALAEAEAALRDLRRELrelEAEIASLERRKSNIPARLLALRDALAEA 452
|
|
| CHASE3 |
COG5278 |
Extracytoplasmic sensor domain CHASE3 (specificity unknown) [Signal transduction mechanisms]; |
67-350 |
3.15e-06 |
|
Extracytoplasmic sensor domain CHASE3 (specificity unknown) [Signal transduction mechanisms];
Pssm-ID: 444089 [Multi-domain] Cd Length: 530 Bit Score: 49.13 E-value: 3.15e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 67 LASYLEKVRQLERDNAELENLIRERSQQQEPL--LCPSYQSYFKTIEELQQKILCSKSENARLVVQIDNAKLAADDFRTK 144
Cdd:COG5278 78 LEPYEEARAEIDELLAELRSLTADNPEQQARLdeLEALIDQWLAELEQVIALRRAGGLEAALALVRSGEGKALMDEIRAR 157
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 145 YQTEQSLRQLVESDINSLRRILDELTLCRSDLEAQMESLKEELLSLKQNHEQEVNTL-RCQLGDRLNVEVDAAPAVDLNQ 223
Cdd:COG5278 158 LLLLALALAALLLAAAALLLLLLALAALLALAELLLLALARALAALLLLLLLEAELAaAAALLAAAAALAALAALELLAA 237
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 224 VLNETRNQYEALVETNRREVEQWFATQTEELNKQVVSSSEQLQSYQAEIIELRRTVNALEIELQAQHNLRYSLENTLTES 303
Cdd:COG5278 238 LALALALLLAALLLALLAALALAALLAAALLALAALLLALAAAAALAAAAALELAAAEALALAELELELLLAAAAAAAAA 317
|
250 260 270 280
....*....|....*....|....*....|....*....|....*..
gi 10337581 304 EARYSSQLSQVQSLITNVESQLAEIRSDLERQNQEYQVLLDVRARLE 350
Cdd:COG5278 318 AAAAAAALAALLALALATALAAAAAALALLAALLAEAAAAAAEEAEA 364
|
|
| CCDC158 |
pfam15921 |
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. ... |
63-358 |
5.11e-06 |
|
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. The function is not known.
Pssm-ID: 464943 [Multi-domain] Cd Length: 1112 Bit Score: 48.96 E-value: 5.11e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 63 LNDRLASYLEKVRQLERDNAELENLiRERS--QQQEPLLCPSYQSYFKTIEELQQKILCSKSENARLV----VQIDN-AK 135
Cdd:pfam15921 498 VSDLTASLQEKERAIEATNAEITKL-RSRVdlKLQELQHLKNEGDHLRNVQTECEALKLQMAEKDKVIeilrQQIENmTQ 576
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 136 LAADDFRTKYQTEQSLRQLvESDINSLRRILDELTLCRSDLEAQMESLKEELLSLKQNHEQEVNTLrcqlGDRLNVEVDA 215
Cdd:pfam15921 577 LVGQHGRTAGAMQVEKAQL-EKEINDRRLELQEFKILKDKKDAKIRELEARVSDLELEKVKLVNAG----SERLRAVKDI 651
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 216 APAVDlnQVLNE---TRNQYEALVEtNRREVEQWFATQTEELNKQVVSSSEQLQSYQAEIIELRRTVNALEIELQAQHNL 292
Cdd:pfam15921 652 KQERD--QLLNEvktSRNELNSLSE-DYEVLKRNFRNKSEEMETTTNKLKMQLKSAQSELEQTRNTLKSMEGSDGHAMKV 728
|
250 260 270 280 290 300
....*....|....*....|....*....|....*....|....*....|....*....|....*....
gi 10337581 293 RYSLENTLTESEARYSSQLSQVQSL---ITNVESQLAEIRSDLERQNQEYQVLLDVRARLECEINTYRS 358
Cdd:pfam15921 729 AMGMQKQITAKRGQIDALQSKIQFLeeaMTNANKEKHFLKEEKNKLSQELSTVATEKNKMAGELEVLRS 797
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
57-338 |
5.42e-06 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 48.90 E-value: 5.42e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 57 KETMQFLNDRLASYLEKVRQLERDNAELENLIRERSQQQEPLLcPSYQSYFKTIEELQQKILCSKSENARLVVQIDNAKL 136
Cdd:TIGR02168 732 RKDLARLEAEVEQLEERIAQLSKELTELEAEIEELEERLEEAE-EELAEAEAEIEELEAQIEQLKEELKALREALDELRA 810
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 137 AADDFRTKYQTEQSLRQLVESDINSLRRILDELTLCRSDLEAQMESLKEELLSLKQNHEQEvntlrcqlgdrlnvevdaa 216
Cdd:TIGR02168 811 ELTLLNEEAANLRERLESLERRIAATERRLEDLEEQIEELSEDIESLAAEIEELEELIEEL------------------- 871
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 217 pAVDLNQVLNETRNQYEALVETNRREveqwfatqtEELNKQVVSSSEQLQSYQAEIIELRRTVNALEIELQAQHNLRYSL 296
Cdd:TIGR02168 872 -ESELEALLNERASLEEALALLRSEL---------EELSEELRELESKRSELRRELEELREKLAQLELRLEGLEVRIDNL 941
|
250 260 270 280
....*....|....*....|....*....|....*....|..
gi 10337581 297 ENTLTEseaRYSSQLSQVQSLITNVESQLAEIRSDLERQNQE 338
Cdd:TIGR02168 942 QERLSE---EYSLTLEEAEALENKIEDDEEEARRRLKRLENK 980
|
|
| DR0291 |
COG1579 |
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General ... |
153-338 |
6.38e-06 |
|
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General function prediction only];
Pssm-ID: 441187 [Multi-domain] Cd Length: 236 Bit Score: 47.23 E-value: 6.38e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 153 QLVESDINSLRRILDELTLCRSDLEAQMESLKEELLSLKQNHEQevntlrcqlgdrlnvevdaapavdlnqvLNETRNQY 232
Cdd:COG1579 13 QELDSELDRLEHRLKELPAELAELEDELAALEARLEAAKTELED----------------------------LEKEIKRL 64
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 233 EALVETNRREVEQWfatqTEELNKqvVSSSEQLQSYQAEIIELRRTVNALEIELQAQHNLRYSLENTLTESEARYSSQLS 312
Cdd:COG1579 65 ELEIEEVEARIKKY----EEQLGN--VRNNKEYEALQKEIESLKRRISDLEDEILELMERIEELEEELAELEAELAELEA 138
|
170 180
....*....|....*....|....*.
gi 10337581 313 QVQSLITNVESQLAEIRSDLERQNQE 338
Cdd:COG1579 139 ELEEKKAELDEELAELEAELEELEAE 164
|
|
| COG4913 |
COG4913 |
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; |
149-337 |
7.01e-06 |
|
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown];
Pssm-ID: 443941 [Multi-domain] Cd Length: 1089 Bit Score: 48.37 E-value: 7.01e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 149 QSLRQLveSDINSLRR--ILDEltlcrSDLEAQMESLKEELLSLKQNHEQEVNTLRCQlgDRLnvevdaAPAVDLNQVLN 226
Cdd:COG4913 201 QSFKPI--GDLDDFVReyMLEE-----PDTFEAADALVEHFDDLERAHEALEDAREQI--ELL------EPIRELAERYA 265
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 227 ETRNQYEALVETnRREVEQWFATQTEELNKQvvssseQLQSYQAEIIELRRTVNALEIELQAQHNLRYSLENTLTESEAR 306
Cdd:COG4913 266 AARERLAELEYL-RAALRLWFAQRRLELLEA------ELEELRAELARLEAELERLEARLDALREELDELEAQIRGNGGD 338
|
170 180 190
....*....|....*....|....*....|.
gi 10337581 307 yssQLSQVQSLITNVESQLAEIRSDLERQNQ 337
Cdd:COG4913 339 ---RLEQLEREIERLERELEERERRRARLEA 366
|
|
| Myosin_tail_1 |
pfam01576 |
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and ... |
76-344 |
1.19e-05 |
|
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and four light chains it is a fundamental contractile protein found in all eukaryote cell types. This family consists of the coiled-coil myosin heavy chain tail region. The coiled-coil is composed of the tail from two molecules of myosin. These can then assemble into the macromolecular thick filament. The coiled-coil region provides the structural backbone the thick filament.
Pssm-ID: 460256 [Multi-domain] Cd Length: 1081 Bit Score: 47.48 E-value: 1.19e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 76 QLERDNAELENLIRERSQQQEPL--LCPSYQSYFKTIEELQQKILCSKSENARLVVQI-DNAKLAADDFRTKYQTEQSLR 152
Cdd:pfam01576 413 QLQELQARLSESERQRAELAEKLskLQSELESVSSLLNEAEGKNIKLSKDVSSLESQLqDTQELLQEETRQKLNLSTRLR 492
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 153 QLvESDINSLRRILDELTLCRSDLEAQMESLKEELLSLKQNHEQEVNTLRCQLGDRLNVEVDAApavDLNQVLNETRNQY 232
Cdd:pfam01576 493 QL-EDERNSLQEQLEEEEEAKRNVERQLSTLQAQLSDMKKKLEEDAGTLEALEEGKKRLQRELE---ALTQQLEEKAAAY 568
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 233 EALVETNRReVEQWFATQTEEL--NKQVVSSSEQLQSYQAEIIELRRTVNAleielqaqhnlRYSLENTLTESEARysSQ 310
Cdd:pfam01576 569 DKLEKTKNR-LQQELDDLLVDLdhQRQLVSNLEKKQKKFDQMLAEEKAISA-----------RYAEERDRAEAEAR--EK 634
|
250 260 270
....*....|....*....|....*....|....
gi 10337581 311 LSQVQSLITNVESQLaEIRSDLERQNQEYQVLLD 344
Cdd:pfam01576 635 ETRALSLARALEEAL-EAKEELERTNKQLRAEME 667
|
|
| CwlO1 |
COG3883 |
Uncharacterized N-terminal coiled-coil domain of peptidoglycan hydrolase CwlO [Function ... |
134-338 |
1.34e-05 |
|
Uncharacterized N-terminal coiled-coil domain of peptidoglycan hydrolase CwlO [Function unknown];
Pssm-ID: 443091 [Multi-domain] Cd Length: 379 Bit Score: 46.75 E-value: 1.34e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 134 AKLAADDFRTKYQTEQSLRQLVESDINSLRRILDELTLCRSDLEAQMESLKEELLSLKQN---HEQEVNTLRCQLGDRLN 210
Cdd:COG3883 14 ADPQIQAKQKELSELQAELEAAQAELDALQAELEELNEEYNELQAELEALQAEIDKLQAEiaeAEAEIEERREELGERAR 93
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 211 VE-VDAAPAVDLNQVLNET-------RNQY-EALVETNRREVEQwFATQTEELN---KQVVSSSEQLQSYQAEIIELRRT 278
Cdd:COG3883 94 ALyRSGGSVSYLDVLLGSEsfsdfldRLSAlSKIADADADLLEE-LKADKAELEakkAELEAKLAELEALKAELEAAKAE 172
|
170 180 190 200 210 220
....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 279 VNALEIELQAQHNLRYSLENTLTESEARYSSQLSQVQSLITNVESQLAEIRSDLERQNQE 338
Cdd:COG3883 173 LEAQQAEQEALLAQLSAEEAAAEAQLAELEAELAAAEAAAAAAAAAAAAAAAAAAAAAAA 232
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
163-362 |
1.57e-05 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 47.37 E-value: 1.57e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 163 RRILDELTLCrSDLEAQMESLKEELLSLKQNHEqEVNTLRCQLGDRLnvevdaapavdlnQVLNETRNQ---YEALvETN 239
Cdd:TIGR02169 156 RKIIDEIAGV-AEFDRKKEKALEELEEVEENIE-RLDLIIDEKRQQL-------------ERLRREREKaerYQAL-LKE 219
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 240 RREVEQW--------FATQTEELNKQVVSSSEQLQSYQAEIIELRRTVNALEIELqAQHNLRYsleNTLTESEARyssql 311
Cdd:TIGR02169 220 KREYEGYellkekeaLERQKEAIERQLASLEEELEKLTEEISELEKRLEEIEQLL-EELNKKI---KDLGEEEQL----- 290
|
170 180 190 200 210
....*....|....*....|....*....|....*....|....*....|.
gi 10337581 312 sQVQSLITNVESQLAEIRSDLERQNQEYQVLLDVRARLECEINTYRSLLES 362
Cdd:TIGR02169 291 -RVKEKIGELEAEIASLERSIAEKERELEDAEERLAKLEAEIDKLLAEIEE 340
|
|
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
143-350 |
2.47e-05 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 46.47 E-value: 2.47e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 143 TKYQT--EQSLRQL--VESDINSLRRILDELtlcrsdlEAQMESLKEEllslkqnheqevntlrcqlgdrlnVEVdAAPA 218
Cdd:COG1196 168 SKYKErkEEAERKLeaTEENLERLEDILGEL-------ERQLEPLERQ------------------------AEK-AERY 215
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 219 VDLNQVLNETRNQYEALVETNRREVEQWFATQTEELNKQVVSSSEQLQSYQAEIIELRRTVNALEIELQAQHNLRYSLEN 298
Cdd:COG1196 216 RELKEELKELEAELLLLKLRELEAELEELEAELEELEAELEELEAELAELEAELEELRLELEELELELEEAQAEEYELLA 295
|
170 180 190 200 210
....*....|....*....|....*....|....*....|....*....|..
gi 10337581 299 TLTESEARYSSQLSQVQSLITNVESQLAEIRSDLERQNQEYQVLLDVRARLE 350
Cdd:COG1196 296 ELARLEQDIARLEERRRELEERLEELEEELAELEEELEELEEELEELEEELE 347
|
|
| PRK02224 |
PRK02224 |
DNA double-strand break repair Rad50 ATPase; |
58-338 |
2.55e-05 |
|
DNA double-strand break repair Rad50 ATPase;
Pssm-ID: 179385 [Multi-domain] Cd Length: 880 Bit Score: 46.57 E-value: 2.55e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 58 ETMQFLNDRLASYLEKVRQLERDNAELENLIRERSQQQEPLLcpsyqsyfKTIEELQqkilcSKSENARLVVQidNAKLA 137
Cdd:PRK02224 502 EDLVEAEDRIERLEERREDLEELIAERRETIEEKRERAEELR--------ERAAELE-----AEAEEKREAAA--EAEEE 566
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 138 ADDFRTKYQTEQSLRQLVESDINSLRRILDELTLcRSDLEAQMESLKEellslKQNHEQEVNTLRcqlGDRLnvevdaap 217
Cdd:PRK02224 567 AEEAREEVAELNSKLAELKERIESLERIRTLLAA-IADAEDEIERLRE-----KREALAELNDER---RERL-------- 629
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 218 avdlnQVLNETRNQYEALVETNRREVEQWFATQTEELNKQVvssSEQLQSYQAEIIELRRTVNALEIELQAQHNLR---Y 294
Cdd:PRK02224 630 -----AEKRERKRELEAEFDEARIEEAREDKERAEEYLEQV---EEKLDELREERDDLQAEIGAVENELEELEELRerrE 701
|
250 260 270 280
....*....|....*....|....*....|....*....|....
gi 10337581 295 SLENTLTESEARYSsqlsQVQSLitnvESQLAEIRSDLERQNQE 338
Cdd:PRK02224 702 ALENRVEALEALYD----EAEEL----ESMYGDLRAELRQRNVE 737
|
|
| COG4913 |
COG4913 |
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; |
146-358 |
3.12e-05 |
|
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown];
Pssm-ID: 443941 [Multi-domain] Cd Length: 1089 Bit Score: 46.45 E-value: 3.12e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 146 QTEQSLRQLVES--DINSLRRILDeltlcrsDLEAQMESLkEELLSLKQNHEQ---EVNTLRcQLGDRLNVEVDAAPAVD 220
Cdd:COG4913 222 DTFEAADALVEHfdDLERAHEALE-------DAREQIELL-EPIRELAERYAAareRLAELE-YLRAALRLWFAQRRLEL 292
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 221 LNQVLNETRNQYEALvETNRREVEQwfatQTEELNKQVVSSSEQLQSYQAEIIE-LRRTVNALEIELQ--AQHNLRY--- 294
Cdd:COG4913 293 LEAELEELRAELARL-EAELERLEA----RLDALREELDELEAQIRGNGGDRLEqLEREIERLERELEerERRRARLeal 367
|
170 180 190 200 210 220
....*....|....*....|....*....|....*....|....*....|....*....|....*.
gi 10337581 295 --SLENTLTESEARYSSQLSQVQSLITNVESQLAEIRSDLERQNQEYQVLLDVRARLECEINTYRS 358
Cdd:COG4913 368 laALGLPLPASAEEFAALRAEAAALLEALEEELEALEEALAEAEAALRDLRRELRELEAEIASLER 433
|
|
| CCDC158 |
pfam15921 |
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. ... |
68-367 |
4.66e-05 |
|
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. The function is not known.
Pssm-ID: 464943 [Multi-domain] Cd Length: 1112 Bit Score: 45.88 E-value: 4.66e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 68 ASYLEKVRQLERDNAELENLIRErsqqqepllcpSYQSYFKTIEELQQKILCSKSENARLVVQIDN------------AK 135
Cdd:pfam15921 313 SMYMRQLSDLESTVSQLRSELRE-----------AKRMYEDKIEELEKQLVLANSELTEARTERDQfsqesgnlddqlQK 381
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 136 LAADdfRTKYQTEQSL-----RQLVESD------INSLRRILDELTLCRSDLEAQMESLKEEllslkqnheqevntlrCQ 204
Cdd:pfam15921 382 LLAD--LHKREKELSLekeqnKRLWDRDtgnsitIDHLRRELDDRNMEVQRLEALLKAMKSE----------------CQ 443
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 205 lgdrLNVEVDAAPAVDLNQVLNETRN---QYEALVETNRREVEQWFATQ-TEELNKQVVS--------SSEQLQSYQAEI 272
Cdd:pfam15921 444 ----GQMERQMAAIQGKNESLEKVSSltaQLESTKEMLRKVVEELTAKKmTLESSERTVSdltaslqeKERAIEATNAEI 519
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 273 IELRRTVNALEIELQAQHNLRYSLENTLTESEArYSSQLSQVQSLITNVESQLAEIRSDLERQNQEYQVLLDVRARLECE 352
Cdd:pfam15921 520 TKLRSRVDLKLQELQHLKNEGDHLRNVQTECEA-LKLQMAEKDKVIEILRQQIENMTQLVGQHGRTAGAMQVEKAQLEKE 598
|
330
....*....|....*
gi 10337581 353 INTYRslLESEDCKL 367
Cdd:pfam15921 599 INDRR--LELQEFKI 611
|
|
| Mplasa_alph_rch |
TIGR04523 |
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of ... |
104-363 |
1.16e-04 |
|
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of Mycoplasma species. Members average 750 amino acids in length, including signal peptide. Sequences are predicted (Jpred 3) to be almost entirely alpha-helical. These sequences show strong periodicity (consistent with long alpha helical structures) and low complexity rich in D,E,N,Q, and K. Genes encoding these proteins are often found in tandem. The function is unknown.
Pssm-ID: 275316 [Multi-domain] Cd Length: 745 Bit Score: 44.24 E-value: 1.16e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 104 QSYFKTIEELQQKILCSKSENARLVVQIDNAKLAADDFRTKYQ-TEQSLRQLVESDINSLRRI------LDELTLCRSDL 176
Cdd:TIGR04523 207 KKKIQKNKSLESQISELKKQNNQLKDNIEKKQQEINEKTTEISnTQTQLNQLKDEQNKIKKQLsekqkeLEQNNKKIKEL 286
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 177 EAQMESLKEELLSLKQNHEQEVN-TLRCQLGDRLNVEVDAAPAVDLN-QVLNETRNQYEALVE--TNRREVEQWFATQTE 252
Cdd:TIGR04523 287 EKQLNQLKSEISDLNNQKEQDWNkELKSELKNQEKKLEEIQNQISQNnKIISQLNEQISQLKKelTNSESENSEKQRELE 366
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 253 ELNKQVVSSSEQLQSYQAEIIELRRTVNALEIELQAQHNLRYSLENTLTESEARYSSQLSQVQSLITNVESQLAEIrSDL 332
Cdd:TIGR04523 367 EKQNEIEKLKKENQSYKQEIKNLESQINDLESKIQNQEKLNQQKDEQIKKLQQEKELLEKEIERLKETIIKNNSEI-KDL 445
|
250 260 270
....*....|....*....|....*....|.
gi 10337581 333 ERQNQEYQVLLDVRARLECEINTYRSLLESE 363
Cdd:TIGR04523 446 TNQDSVKELIIKNLDNTRESLETQLKVLSRS 476
|
|
| CusB_dom_1 |
pfam00529 |
Cation efflux system protein CusB domain 1; The cation efflux system protein CusB from E. coli ... |
120-279 |
1.66e-04 |
|
Cation efflux system protein CusB domain 1; The cation efflux system protein CusB from E. coli can be divided into four different domains, the first three domains of the protein are mostly beta-strands and the fourth forms an all alpha-helical domain. This entry represents the first beta-domain (domain 1) of CusB and it is formed by the N and C-terminal ends of the polypeptide (residues 89-102 and 324-385). CusB is part of the copper-transporting efflux system CusCFBA. This domain can also be found in other membrane-fusion proteins, such as HlyD, MdtN, MdtE and AaeA. HlyD is a component of the prototypical alpha-haemolysin (HlyA) bacterial type I secretion system, along with the other components HlyB and TolC. HlyD is anchored in the cytoplasmic membrane by a single transmembrane domain and has a large periplasmic domain within the carboxy-terminal 100 amino acids, HlyB and HlyD form a stable complex that binds the recombinant protein bearing a C-terminal HlyA signal sequence and ATP in the cytoplasm. HlyD, HlyB and TolC combine to form the three-component ABC transporter complex that forms a trans-membrane channel or pore through which HlyA can be transferred directly to the extracellular medium. Cutinase has been shown to be transported effectively through this pore.
Pssm-ID: 425733 [Multi-domain] Cd Length: 322 Bit Score: 43.18 E-value: 1.66e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 120 SKSENARLVVQIDNAKLAaddfRTKYQTEQSLRQLVESDINSLRRILDELTLCRSDLEAQMESLKEELLSLKQNHEQEVN 199
Cdd:pfam00529 56 YQAALDSAEAQLAKAQAQ----VARLQAELDRLQALESELAISRQDYDGATAQLRAAQAAVKAAQAQLAQAQIDLARRRV 131
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 200 TLrcqlgdrlnvEVDAAPA---VDLNQVLNETRNQYEALV---ETNRREVEQWFATQTEELNKQVVSSSEQLQSYQAEII 273
Cdd:pfam00529 132 LA----------PIGGISReslVTAGALVAQAQANLLATVaqlDQIYVQITQSAAENQAEVRSELSGAQLQIAEAEAELK 201
|
170
....*....|
gi 10337581 274 ----ELRRTV 279
Cdd:pfam00529 202 laklDLERTE 211
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
51-341 |
1.92e-04 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 43.90 E-value: 1.92e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 51 SFNGSEKETMQFLNDR-------LASYLEKVRQLERDNAEL-------ENLIRERSQQQEPLLcpSYQSYFKT------- 109
Cdd:TIGR02169 667 LFSRSEPAELQRLRERleglkreLSSLQSELRRIENRLDELsqelsdaSRKIGEIEKEIEQLE--QEEEKLKErleelee 744
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 110 -IEELQQKILCSKSENARLVVQIDNAKLAADDFRTkyQTEQSLRQLVESDINSLRRILDELTLCRSDLEAQMESLKEELL 188
Cdd:TIGR02169 745 dLSSLEQEIENVKSELKELEARIEELEEDLHKLEE--ALNDLEARLSHSRIPEIQAELSKLEEEVSRIEARLREIEQKLN 822
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 189 SL---KQNHEQEVNTLrcqlgdrlnvevdaapaVDLNQVLNETRNQYEALVETNRREVEQwFATQTEELNKQVVSSSEQL 265
Cdd:TIGR02169 823 RLtleKEYLEKEIQEL-----------------QEQRIDLKEQIKSIEKEIENLNGKKEE-LEEELEELEAALRDLESRL 884
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 266 QSYQAEIIELRRTVNALEI---ELQAQHNLRYSLENTLTESEARYSSQLSQVQSLITNVESQLAEIRS--DLERQNQEYQ 340
Cdd:TIGR02169 885 GDLKKERDELEAQLRELERkieELEAQIEKKRKRLSELKAKLEALEEELSEIEDPKGEDEEIPEEELSleDVQAELQRVE 964
|
.
gi 10337581 341 V 341
Cdd:TIGR02169 965 E 965
|
|
| EnvC |
COG4942 |
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
258-364 |
2.61e-04 |
|
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 42.83 E-value: 2.61e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 258 VVSSSEQLQSYQAEIIELRRTVNALEIELQAQHNLRYSLENTLTESEAR----------YSSQLSQVQSLITNVESQLAE 327
Cdd:COG4942 15 AAAQADAAAEAEAELEQLQQEIAELEKELAALKKEEKALLKQLAALERRiaalarriraLEQELAALEAELAELEKEIAE 94
|
90 100 110
....*....|....*....|....*....|....*..
gi 10337581 328 IRSDLERQNQEYQVLLDVRARLEcEINTYRSLLESED 364
Cdd:COG4942 95 LRAELEAQKEELAELLRALYRLG-RQPPLALLLSPED 130
|
|
| Apolipoprotein |
pfam01442 |
Apolipoprotein A1/A4/E domain; These proteins contain several 22 residue repeats which form a ... |
166-333 |
3.25e-04 |
|
Apolipoprotein A1/A4/E domain; These proteins contain several 22 residue repeats which form a pair of alpha helices. This family includes: Apolipoprotein A-I. Apolipoprotein A-IV. Apolipoprotein E.
Pssm-ID: 460211 [Multi-domain] Cd Length: 175 Bit Score: 41.10 E-value: 3.25e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 166 LDELTLCRSDLEAQMESLKEELlslKQNHEQEVNTLRCQLGDRLN-VEVDAAPAVD-LNQVLNETRNQYEALVETNRREV 243
Cdd:pfam01442 6 LDELSTYAEELQEQLGPVAQEL---VDRLEKETEALRERLQKDLEeVRAKLEPYLEeLQAKLGQNVEELRQRLEPYTEEL 82
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 244 EQWFATQTEELNKQVVSSSEQLQSYQAEIIE-LRRTVNALEIELQAQHNLRY-SLENTLTESEARYSSQLSQ-VQSLITN 320
Cdd:pfam01442 83 RKRLNADAEELQEKLAPYGEELRERLEQNVDaLRARLAPYAEELRQKLAERLeELKESLAPYAEEVQAQLSQrLQELREK 162
|
170
....*....|...
gi 10337581 321 VESQLAEIRSDLE 333
Cdd:pfam01442 163 LEPQAEDLREKLD 175
|
|
| Myosin_tail_1 |
pfam01576 |
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and ... |
71-363 |
4.44e-04 |
|
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and four light chains it is a fundamental contractile protein found in all eukaryote cell types. This family consists of the coiled-coil myosin heavy chain tail region. The coiled-coil is composed of the tail from two molecules of myosin. These can then assemble into the macromolecular thick filament. The coiled-coil region provides the structural backbone the thick filament.
Pssm-ID: 460256 [Multi-domain] Cd Length: 1081 Bit Score: 42.47 E-value: 4.44e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 71 LEKV-RQLERDNAELENLIRERSQQQEPLLcpsyQSYFKTIEELQQKILCSKSENARlvvqidnaklaaddfrtKYQTEQ 149
Cdd:pfam01576 206 LEKAkRKLEGESTDLQEQIAELQAQIAELR----AQLAKKEEELQAALARLEEETAQ-----------------KNNALK 264
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 150 SLRQLvESDINSLRRILDELTLCRSDLEAQMESLKEELLSLKQNHEQEVNTLRCQLGDRLNVEVDAApavDLNQVLNETR 229
Cdd:pfam01576 265 KIREL-EAQISELQEDLESERAARNKAEKQRRDLGEELEALKTELEDTLDTTAAQQELRSKREQEVT---ELKKALEEET 340
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 230 NQYEALVETNRREVEQWFATQTEEL-----NKQVVSSSEQ---------------LQSYQAEIIELRRTVNALEIELQAQ 289
Cdd:pfam01576 341 RSHEAQLQEMRQKHTQALEELTEQLeqakrNKANLEKAKQalesenaelqaelrtLQQAKQDSEHKRKKLEGQLQELQAR 420
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 290 HNLRYSLENTLTESEARYSSQLSQVQSLITNVESQ---LAEIRSDLERQNQEYQVLLDVRAR-----------LECEINT 355
Cdd:pfam01576 421 LSESERQRAELAEKLSKLQSELESVSSLLNEAEGKnikLSKDVSSLESQLQDTQELLQEETRqklnlstrlrqLEDERNS 500
|
....*...
gi 10337581 356 YRSLLESE 363
Cdd:pfam01576 501 LQEQLEEE 508
|
|
| COG1340 |
COG1340 |
Uncharacterized coiled-coil protein, contains DUF342 domain [Function unknown]; |
55-282 |
5.49e-04 |
|
Uncharacterized coiled-coil protein, contains DUF342 domain [Function unknown];
Pssm-ID: 440951 [Multi-domain] Cd Length: 297 Bit Score: 41.43 E-value: 5.49e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 55 SEKETMQFLNDRLASYLEKVRQLERDNAELENLIRERSQQQEPLlcpsyqsyFKTIEELQQKILCSKSENARLVVQIDNA 134
Cdd:COG1340 5 ELSSSLEELEEKIEELREEIEELKEKRDELNEELKELAEKRDEL--------NAQVKELREEAQELREKRDELNEKVKEL 76
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 135 KLAADDFRTKyqteqsLRQLVEsDINSLRRILDELTLCRSDLEA---QMESLKEELL--SLKQNHEQE-VNTLRcQLGDR 208
Cdd:COG1340 77 KEERDELNEK------LNELRE-ELDELRKELAELNKAGGSIDKlrkEIERLEWRQQteVLSPEEEKElVEKIK-ELEKE 148
|
170 180 190 200 210 220 230
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....
gi 10337581 209 LNvevDAAPAVDLNQVLNETRNQYEALVEtnrreveqwfatQTEELNKQVVSSSEQLQSYQAEIIELRRTVNAL 282
Cdd:COG1340 149 LE---KAKKALEKNEKLKELRAELKELRK------------EAEEIHKKIKELAEEAQELHEEMIELYKEADEL 207
|
|
| Mplasa_alph_rch |
TIGR04523 |
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of ... |
53-367 |
5.60e-04 |
|
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of Mycoplasma species. Members average 750 amino acids in length, including signal peptide. Sequences are predicted (Jpred 3) to be almost entirely alpha-helical. These sequences show strong periodicity (consistent with long alpha helical structures) and low complexity rich in D,E,N,Q, and K. Genes encoding these proteins are often found in tandem. The function is unknown.
Pssm-ID: 275316 [Multi-domain] Cd Length: 745 Bit Score: 42.31 E-value: 5.60e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 53 NGSEKETMQFLNDRLASYLEKVRQLERDNAELENLIRERSQQQEPL------LCPSYQSYFKTIEELQQKILCSKSENAR 126
Cdd:TIGR04523 302 NQKEQDWNKELKSELKNQEKKLEEIQNQISQNNKIISQLNEQISQLkkeltnSESENSEKQRELEEKQNEIEKLKKENQS 381
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 127 LVVQIDNAKLAADDFRTKYQTEQSLRQLVESDINSLRRILDELTLCRSDLEAQMESLKEELLSLKqNHEQEVNTLRCQLG 206
Cdd:TIGR04523 382 YKQEIKNLESQINDLESKIQNQEKLNQQKDEQIKKLQQEKELLEKEIERLKETIIKNNSEIKDLT-NQDSVKELIIKNLD 460
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 207 DRLNvevdaapavDLNQVLNETRNQYEAlVETNRREVEQWFATQTEE---LNKQVVSSSEQLQSYQAEIIELRRTVNALE 283
Cdd:TIGR04523 461 NTRE---------SLETQLKVLSRSINK-IKQNLEQKQKELKSKEKElkkLNEEKKELEEKVKDLTKKISSLKEKIEKLE 530
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 284 IELQAQHNLRYSLENTLTESEARY-SSQLSQVQSLITNVESQLAEIRSDLERQNQEYQVLLDvraRLECEINTYRSLLES 362
Cdd:TIGR04523 531 SEKKEKESKISDLEDELNKDDFELkKENLEKEIDEKNKEIEELKQTQKSLKKKQEEKQELID---QKEKEKKDLIKEIEE 607
|
....*
gi 10337581 363 EDCKL 367
Cdd:TIGR04523 608 KEKKI 612
|
|
| HEC1 |
COG5185 |
Chromosome segregation protein NDC80, interacts with SMC proteins [Cell cycle control, cell ... |
56-364 |
7.20e-04 |
|
Chromosome segregation protein NDC80, interacts with SMC proteins [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 444066 [Multi-domain] Cd Length: 594 Bit Score: 41.87 E-value: 7.20e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 56 EKETMQFLNDRLASYLEKVRQLERDNAELENLIRERsqqQEPLLCPSYQS--YFKTIEELQQKILcSKSENARLVVQ--- 130
Cdd:COG5185 227 EIINIEEALKGFQDPESELEDLAQTSDKLEKLVEQN---TDLRLEKLGENaeSSKRLNENANNLI-KQFENTKEKIAeyt 302
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 131 ----IDNAKLAADDFRTKYQTEQSLRQLVESDINSLRRILDELTLCRSDLEAQMESLKEELLSLKQnhEQEVNTLRCQLG 206
Cdd:COG5185 303 ksidIKKATESLEEQLAAAEAEQELEESKRETETGIQNLTAEIEQGQESLTENLEAIKEEIENIVG--EVELSKSSEELD 380
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 207 DrLNVEVDAAPAVDLNQVLNETRNQYEAL--VETNRREVEQwfatQTEELNKQVVSSSEQLQSYQAEIIELRRTVNALEI 284
Cdd:COG5185 381 S-FKDTIESTKESLDEIPQNQRGYAQEILatLEDTLKAADR----QIEELQRQIEQATSSNEEVSKLLNELISELNKVMR 455
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 285 ELQAQHNLRYS-----LENTLTESEARYSSQLSQVQSLITNVESQLAEIRSDLERQNQEYQVLLDVRARLECEINTYRSL 359
Cdd:COG5185 456 EADEESQSRLEeaydeINRSVRSKKEDLNEELTQIESRVSTLKATLEKLRAKLERQLEGVRSKLDQVAESLKDFMRARGY 535
|
....*
gi 10337581 360 LESED 364
Cdd:COG5185 536 AHILA 540
|
|
| EnvC |
COG4942 |
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
146-361 |
8.13e-04 |
|
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 41.29 E-value: 8.13e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 146 QTEQSLRQLvESDINSLRRILDELTLCRSDLEAQMESLKEELLSLkqnhEQEVNTLRCQLGDrlnvevdaapavdLNQVL 225
Cdd:COG4942 24 EAEAELEQL-QQEIAELEKELAALKKEEKALLKQLAALERRIAAL----ARRIRALEQELAA-------------LEAEL 85
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 226 NETRNQYEALvETNRREVEQWFATQTEELNKQVVSSSEQLQSYQAEIIELRRTVNALEIELQAQHNLRYSLENTLTESEA 305
Cdd:COG4942 86 AELEKEIAEL-RAELEAQKEELAELLRALYRLGRQPPLALLLSPEDFLDAVRRLQYLKYLAPARREQAEELRADLAELAA 164
|
170 180 190 200 210
....*....|....*....|....*....|....*....|....*....|....*.
gi 10337581 306 RYSSQLSQVQSLiTNVESQLAEIRSDLERQNQEYQVLLdvrARLECEINTYRSLLE 361
Cdd:COG4942 165 LRAELEAERAEL-EALLAELEEERAALEALKAERQKLL---ARLEKELAELAAELA 216
|
|
| YhaN |
COG4717 |
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; |
57-358 |
8.63e-04 |
|
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown];
Pssm-ID: 443752 [Multi-domain] Cd Length: 641 Bit Score: 41.68 E-value: 8.63e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 57 KETMQFLNDRLASYLEKVRQLERDNAELENLIRERSQQQEPLLcpsyQSYFKTIEELQQKILCSKSENARLVVQIDNAKL 136
Cdd:COG4717 152 EERLEELRELEEELEELEAELAELQEELEELLEQLSLATEEEL----QDLAEELEELQQRLAELEEELEEAQEELEELEE 227
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 137 AADDFRTKYQTEQSLRQLVE-------------------SDINSLRRILDELTLC--------------RSDLEAQMESL 183
Cdd:COG4717 228 ELEQLENELEAAALEERLKEarlllliaaallallglggSLLSLILTIAGVLFLVlgllallflllareKASLGKEAEEL 307
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 184 kEELLSLKQNHEQEVNTLRCQLGdrLNVEVDAAPAVDLNQVLNETRNQYEALVETNRR-EVEQWFATQTEELNKQVVSSS 262
Cdd:COG4717 308 -QALPALEELEEEELEELLAALG--LPPDLSPEELLELLDRIEELQELLREAEELEEElQLEELEQEIAALLAEAGVEDE 384
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 263 EQLQS---YQAEIIELRRTVNALEIELQAQHNLRYSLENTLTESEaryssqlsqvqslitnVESQLAEIRSDLERQNQEY 339
Cdd:COG4717 385 EELRAaleQAEEYQELKEELEELEEQLEELLGELEELLEALDEEE----------------LEEELEELEEELEELEEEL 448
|
330
....*....|....*....
gi 10337581 340 QVLLDVRARLECEINTYRS 358
Cdd:COG4717 449 EELREELAELEAELEQLEE 467
|
|
| COG4372 |
COG4372 |
Uncharacterized protein, contains DUF3084 domain [Function unknown]; |
151-348 |
9.56e-04 |
|
Uncharacterized protein, contains DUF3084 domain [Function unknown];
Pssm-ID: 443500 [Multi-domain] Cd Length: 370 Bit Score: 41.04 E-value: 9.56e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 151 LRQLVESDINSLRRILDELTLCRSDLEAQMESLKEELLSLKQNHEQevntlrcqlgdrlnvevdaapavdLNQVLNETRN 230
Cdd:COG4372 18 LRPKTGILIAALSEQLRKALFELDKLQEELEQLREELEQAREELEQ------------------------LEEELEQARS 73
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 231 QYEALVEtnrrEVEQWfATQTEELNKQVVSSSEQLQSYQAEIIELRRTVNALEIELQAQHNLRYSLENTLTESEARYSSQ 310
Cdd:COG4372 74 ELEQLEE----ELEEL-NEQLQAAQAELAQAQEELESLQEEAEELQEELEELQKERQDLEQQRKQLEAQIAELQSEIAER 148
|
170 180 190
....*....|....*....|....*....|....*...
gi 10337581 311 LSQVQSLitnvESQLAEIRSDLERQNQEYQVLLDVRAR 348
Cdd:COG4372 149 EEELKEL----EEQLESLQEELAALEQELQALSEAEAE 182
|
|
| PRK10246 |
PRK10246 |
exonuclease subunit SbcC; Provisional |
168-381 |
1.07e-03 |
|
exonuclease subunit SbcC; Provisional
Pssm-ID: 182330 [Multi-domain] Cd Length: 1047 Bit Score: 41.32 E-value: 1.07e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 168 ELTLCRSDLEAQMESLKEELLSLKQNHEQ--EVNTlRCQLGDRLNVEVDAAPAVDLNQVLNETRNQYEALVETNR----- 240
Cdd:PRK10246 284 SLAQPARQLRPHWERIQEQSAALAHTRQQieEVNT-RLQSTMALRARIRHHAAKQSAELQAQQQSLNTWLAEHDRfrqwn 362
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 241 REVEQWFAtqteeLNKQVVSSSEQLQSYQAEIIELRRTVNAL-EIELQ----------AQHNLRYSLENTLTESEARYSS 309
Cdd:PRK10246 363 NELAGWRA-----QFSQQTSDREQLRQWQQQLTHAEQKLNALpAITLTltadevaaalAQHAEQRPLRQRLVALHGQIVP 437
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 310 Q----------LSQVQSLITNVESQLAEIRSDLERQNQEYqvlLDVRARLECE-----INTYRSLLEsedcklPSNPCAT 374
Cdd:PRK10246 438 QqkrlaqlqvaIQNVTQEQTQRNAALNEMRQRYKEKTQQL---ADVKTICEQEarikdLEAQRAQLQ------AGQPCPL 508
|
....*..
gi 10337581 375 TNACEKP 381
Cdd:PRK10246 509 CGSTSHP 515
|
|
| CwlO1 |
COG3883 |
Uncharacterized N-terminal coiled-coil domain of peptidoglycan hydrolase CwlO [Function ... |
101-316 |
1.40e-03 |
|
Uncharacterized N-terminal coiled-coil domain of peptidoglycan hydrolase CwlO [Function unknown];
Pssm-ID: 443091 [Multi-domain] Cd Length: 379 Bit Score: 40.58 E-value: 1.40e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 101 PSYQSYFKTIEELQQKILCSKSENARLVVQIDNAKLAADdfrtkyQTEQSLRQLvESDINSLRRILDELtlcRSDLEAQM 180
Cdd:COG3883 16 PQIQAKQKELSELQAELEAAQAELDALQAELEELNEEYN------ELQAELEAL-QAEIDKLQAEIAEA---EAEIEERR 85
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 181 ESLKEELLSLKQNhEQEVNTLRCQLG--------DRLNVeVDAAPAVDlNQVLNETRNQYEALvETNRREVEQwfatQTE 252
Cdd:COG3883 86 EELGERARALYRS-GGSVSYLDVLLGsesfsdflDRLSA-LSKIADAD-ADLLEELKADKAEL-EAKKAELEA----KLA 157
|
170 180 190 200 210 220
....*....|....*....|....*....|....*....|....*....|....*....|....
gi 10337581 253 ELNKQVVSSSEQLQSYQAEIIELRRTVNALEIELQAQHNLRYSLENTLTESEARYSSQLSQVQS 316
Cdd:COG3883 158 ELEALKAELEAAKAELEAQQAEQEALLAQLSAEEAAAEAQLAELEAELAAAEAAAAAAAAAAAA 221
|
|
| COG4913 |
COG4913 |
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; |
63-227 |
1.44e-03 |
|
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown];
Pssm-ID: 443941 [Multi-domain] Cd Length: 1089 Bit Score: 41.05 E-value: 1.44e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 63 LNDRLASYLEKVRQLERDNAELENLIRERSQQQEpllcpsyQSYFKTIEELQQKI------LCSKSEN-ARLVVQIDNAK 135
Cdd:COG4913 300 LRAELARLEAELERLEARLDALREELDELEAQIR-------GNGGDRLEQLEREIerlereLEERERRrARLEALLAALG 372
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 136 LA----ADDFRTKYQTEQSLRQLVESDINSLRRILDELTLCRSDLEAQMESLKEELLSLKQ---NHEQEVNTLRCQLGDR 208
Cdd:COG4913 373 LPlpasAEEFAALRAEAAALLEALEEELEALEEALAEAEAALRDLRRELRELEAEIASLERrksNIPARLLALRDALAEA 452
|
170 180
....*....|....*....|
gi 10337581 209 LNVEVDAAP-AVDLNQVLNE 227
Cdd:COG4913 453 LGLDEAELPfVGELIEVRPE 472
|
|
| EnvC |
COG4942 |
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
63-241 |
2.42e-03 |
|
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 39.75 E-value: 2.42e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 63 LNDRLASYLEKVRQLERDNAELENLIRERSQQqepllcpsyqsyfktIEELQQKILCSKSENARLVVQI--------DNA 134
Cdd:COG4942 60 LERRIAALARRIRALEQELAALEAELAELEKE---------------IAELRAELEAQKEELAELLRALyrlgrqppLAL 124
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 135 KLAADDFRTKYQTEQSLRQLVESD---INSLRRILDELTLCRSDLEAQmeslKEELLSLKQNHEQEVNTLRCQLGDRlnv 211
Cdd:COG4942 125 LLSPEDFLDAVRRLQYLKYLAPARreqAEELRADLAELAALRAELEAE----RAELEALLAELEEERAALEALKAER--- 197
|
170 180 190
....*....|....*....|....*....|
gi 10337581 212 evdAAPAVDLNQVLNETRNQYEALVETNRR 241
Cdd:COG4942 198 ---QKLLARLEKELAELAAELAELQQEAEE 224
|
|
| SCP-1 |
pfam05483 |
Synaptonemal complex protein 1 (SCP-1); Synaptonemal complex protein 1 (SCP-1) is the major ... |
59-372 |
2.78e-03 |
|
Synaptonemal complex protein 1 (SCP-1); Synaptonemal complex protein 1 (SCP-1) is the major component of the transverse filaments of the synaptonemal complex. Synaptonemal complexes are structures that are formed between homologous chromosomes during meiotic prophase.
Pssm-ID: 114219 [Multi-domain] Cd Length: 787 Bit Score: 40.09 E-value: 2.78e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 59 TMQFLNDRLASYLEKVRQL-ERDNAELENLIRERSQQQepLLCPSYQSYFKTIEELQqkilcsKSENARLVVQIDNAKLA 137
Cdd:pfam05483 311 TQKALEEDLQIATKTICQLtEEKEAQMEELNKAKAAHS--FVVTEFEATTCSLEELL------RTEQQRLEKNEDQLKII 382
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 138 ADDFRTKYQTEQSLRQLV---ESDINSLRRILDE---LTLCRSDLEAQMESLK---EELLSLKQNHEQEVNTLRCQLgdr 208
Cdd:pfam05483 383 TMELQKKSSELEEMTKFKnnkEVELEELKKILAEdekLLDEKKQFEKIAEELKgkeQELIFLLQAREKEIHDLEIQL--- 459
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 209 lnvevdaapavdlnQVLNETRNQYEALVETNRREVEQwfatqtEEL-NKQVVSSSEQLqsyQAEIIELRRTVNALEIELQ 287
Cdd:pfam05483 460 --------------TAIKTSEEHYLKEVEDLKTELEK------EKLkNIELTAHCDKL---LLENKELTQEASDMTLELK 516
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 288 AQHNLRysleNTLTESEARYSSQLSQVQSLITNVESQLAEIRSDLERQNQEYQVLLDvRARLECEINTYRSLLESEDCKL 367
Cdd:pfam05483 517 KHQEDI----INCKKQEERMLKQIENLEEKEMNLRDELESVREEFIQKGDEVKCKLD-KSEENARSIEYEVLKKEKQMKI 591
|
....*
gi 10337581 368 PSNPC 372
Cdd:pfam05483 592 LENKC 596
|
|
| COG4372 |
COG4372 |
Uncharacterized protein, contains DUF3084 domain [Function unknown]; |
263-364 |
2.95e-03 |
|
Uncharacterized protein, contains DUF3084 domain [Function unknown];
Pssm-ID: 443500 [Multi-domain] Cd Length: 370 Bit Score: 39.50 E-value: 2.95e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 263 EQLQSYQAEIIELRRTVNALEIELQAQHNLRYSLENTLTESE---ARYSSQLSQVQSLITNVESQLAEIRSDLERQNQEY 339
Cdd:COG4372 45 EELEQLREELEQAREELEQLEEELEQARSELEQLEEELEELNeqlQAAQAELAQAQEELESLQEEAEELQEELEELQKER 124
|
90 100
....*....|....*....|....*
gi 10337581 340 QVLLDVRARLECEINTYRSLLESED 364
Cdd:COG4372 125 QDLEQQRKQLEAQIAELQSEIAERE 149
|
|
| PRK03918 |
PRK03918 |
DNA double-strand break repair ATPase Rad50; |
55-363 |
2.97e-03 |
|
DNA double-strand break repair ATPase Rad50;
Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 40.05 E-value: 2.97e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 55 SEKETMQFLNDRLASYLEKVRQLERDNAELENLIRERSQQQEPLLcpsyqsyfKTIEELQQKILCSKS--ENARLVVQId 132
Cdd:PRK03918 228 KEVKELEELKEEIEELEKELESLEGSKRKLEEKIRELEERIEELK--------KEIEELEEKVKELKElkEKAEEYIKL- 298
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 133 nAKLAADDFRTKYQTEQSLRQLvESDINSLRRILDELTLCRS---DLEAQMESLKEELLSLKQNHE--QEVNTLRCQLgD 207
Cdd:PRK03918 299 -SEFYEEYLDELREIEKRLSRL-EEEINGIEERIKELEEKEErleELKKKLKELEKRLEELEERHElyEEAKAKKEEL-E 375
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 208 RLNVEVDAAPAVDLNQVLNETRNQYEAlVETNRREVEQWFA---TQTEELNKQVVS-------------------SSEQL 265
Cdd:PRK03918 376 RLKKRLTGLTPEKLEKELEELEKAKEE-IEEEISKITARIGelkKEIKELKKAIEElkkakgkcpvcgrelteehRKELL 454
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 266 QSYQAEIIELRRTVNAL-EIELQAQHNLRySLENTLteSEARYSSQLSQVQSLITNVESQLAEIR-SDLERQNQEYQVLL 343
Cdd:PRK03918 455 EEYTAELKRIEKELKEIeEKERKLRKELR-ELEKVL--KKESELIKLKELAEQLKELEEKLKKYNlEELEKKAEEYEKLK 531
|
330 340
....*....|....*....|
gi 10337581 344 DVRARLECEINTYRSLLESE 363
Cdd:PRK03918 532 EKLIKLKGEIKSLKKELEKL 551
|
|
| DUF3584 |
pfam12128 |
Protein of unknown function (DUF3584); This protein is found in bacteria and eukaryotes. ... |
110-352 |
4.85e-03 |
|
Protein of unknown function (DUF3584); This protein is found in bacteria and eukaryotes. Proteins in this family are typically between 943 to 1234 amino acids in length. This family contains a P-loop motif suggesting it is a nucleotide binding protein. It may be involved in replication.
Pssm-ID: 432349 [Multi-domain] Cd Length: 1191 Bit Score: 39.44 E-value: 4.85e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 110 IEELQQKILCSKSENARLV---VQIDNAKLAADDFRTKYQTEQS-LRQLVESDINSLRRILDELTLcrsDLEAQMESLke 185
Cdd:pfam12128 243 FTKLQQEFNTLESAELRLShlhFGYKSDETLIASRQEERQETSAeLNQLLRTLDDQWKEKRDELNG---ELSAADAAV-- 317
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 186 ellslkQNHEQEVNTLRCQLG--DRLNVEVDAAPAVDLNQVLNETRNQYE--ALVETNRREVEQWFAT---QTEELNKQV 258
Cdd:pfam12128 318 ------AKDRSELEALEDQHGafLDADIETAAADQEQLPSWQSELENLEErlKALTGKHQDVTAKYNRrrsKIKEQNNRD 391
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 259 VSSSEQLQSYQAEIIELRRTV-----NALEIELQAQHNlrySLENTLTESEARYSSQLSQVQSLITNvesqlAEIRSDLE 333
Cdd:pfam12128 392 IAGIKDKLAKIREARDRQLAVaeddlQALESELREQLE---AGKLEFNEEEYRLKSRLGELKLRLNQ-----ATATPELL 463
|
250
....*....|....*....
gi 10337581 334 RQNQEYQVLLDvRARLECE 352
Cdd:pfam12128 464 LQLENFDERIE-RAREEQE 481
|
|
| Myosin_tail_1 |
pfam01576 |
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and ... |
78-362 |
4.86e-03 |
|
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and four light chains it is a fundamental contractile protein found in all eukaryote cell types. This family consists of the coiled-coil myosin heavy chain tail region. The coiled-coil is composed of the tail from two molecules of myosin. These can then assemble into the macromolecular thick filament. The coiled-coil region provides the structural backbone the thick filament.
Pssm-ID: 460256 [Multi-domain] Cd Length: 1081 Bit Score: 39.39 E-value: 4.86e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 78 ERDNAELENLIRERSQQQEPLLCPSYQSYFKTIEELQQkilcsksenarlvvQIDNAKlaaddfRTKYQTEQSlRQLVES 157
Cdd:pfam01576 326 EQEVTELKKALEEETRSHEAQLQEMRQKHTQALEELTE--------------QLEQAK------RNKANLEKA-KQALES 384
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 158 DINSLRRILDELTLCRSDLEAQMESLKEELlslkqnheQEVNtLRCQLGDRLNVEvdaapavdLNQVLNETRNQYEAlVE 237
Cdd:pfam01576 385 ENAELQAELRTLQQAKQDSEHKRKKLEGQL--------QELQ-ARLSESERQRAE--------LAEKLSKLQSELES-VS 446
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 238 TNRREVEqwfaTQTEELNKQVVSSSEQLQSYQAEIIELRRTVNALEIELQAQHNLRYSLENTLTESEARYSSQLSQVQSL 317
Cdd:pfam01576 447 SLLNEAE----GKNIKLSKDVSSLESQLQDTQELLQEETRQKLNLSTRLRQLEDERNSLQEQLEEEEEAKRNVERQLSTL 522
|
250 260 270 280
....*....|....*....|....*....|....*....|....*
gi 10337581 318 itnvESQLAEIRSDLERQNQEYQVLLDVRARLECEINTYRSLLES 362
Cdd:pfam01576 523 ----QAQLSDMKKKLEEDAGTLEALEEGKKRLQRELEALTQQLEE 563
|
|
| DUF5401 |
pfam17380 |
Family of unknown function (DUF5401); This is a family of unknown function found in ... |
65-355 |
5.24e-03 |
|
Family of unknown function (DUF5401); This is a family of unknown function found in Chromadorea.
Pssm-ID: 375164 [Multi-domain] Cd Length: 722 Bit Score: 38.95 E-value: 5.24e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 65 DRLAsyLEKVRQLERDNAELENLIRERSQQQEPLLcpsyqsYFKTIEELQQKILCSKSENARLVVQIDNAKlaaddfrtK 144
Cdd:pfam17380 340 ERMA--MERERELERIRQEERKRELERIRQEEIAM------EISRMRELERLQMERQQKNERVRQELEAAR--------K 403
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 145 YQTEQSLRQlvesdinslRRILDELTLCRSDLEAQMESLKEELLSLKQNHEQEVNTLRCQlgdrlnvEVDAAPAVDLNQV 224
Cdd:pfam17380 404 VKILEEERQ---------RKIQQQKVEMEQIRAEQEEARQREVRRLEEERAREMERVRLE-------EQERQQQVERLRQ 467
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 225 LNETRNQYEALVETNRREveqwfATQTEELNKQVVssSEQLQSYQAEIIELRRTVNALEIELQAQHNLRYSLENTLTESE 304
Cdd:pfam17380 468 QEEERKRKKLELEKEKRD-----RKRAEEQRRKIL--EKELEERKQAMIEEERKRKLLEKEMEERQKAIYEEERRREAEE 540
|
250 260 270 280 290
....*....|....*....|....*....|....*....|....*....|....*
gi 10337581 305 ARYSSQLSQVQSLITNVESQLAEIRSDLERQNQEYQVLLDV----RARLECEINT 355
Cdd:pfam17380 541 ERRKQQEMEERRRIQEQMRKATEERSRLEAMEREREMMRQIveseKARAEYEATT 595
|
|
| COG4913 |
COG4913 |
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; |
239-361 |
7.17e-03 |
|
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown];
Pssm-ID: 443941 [Multi-domain] Cd Length: 1089 Bit Score: 38.74 E-value: 7.17e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 239 NRREVEQWF-----ATQTEELNKQVVSSSEQLQSYQAEIIELRRTVNALEIELQAQHNLRY---------SLENTLTESE 304
Cdd:COG4913 595 RRRIRSRYVlgfdnRAKLAALEAELAELEEELAEAEERLEALEAELDALQERREALQRLAEyswdeidvaSAEREIAELE 674
|
90 100 110 120 130
....*....|....*....|....*....|....*....|....*....|....*..
gi 10337581 305 ARYSsQLSQVQSLITNVESQLAEIRSDLERQNQEYQVLLDVRARLECEINTYRSLLE 361
Cdd:COG4913 675 AELE-RLDASSDDLAALEEQLEELEAELEELEEELDELKGEIGRLEKELEQAEEELD 730
|
|
| HEC1 |
COG5185 |
Chromosome segregation protein NDC80, interacts with SMC proteins [Cell cycle control, cell ... |
54-325 |
9.02e-03 |
|
Chromosome segregation protein NDC80, interacts with SMC proteins [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 444066 [Multi-domain] Cd Length: 594 Bit Score: 38.40 E-value: 9.02e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 54 GSEKETMQFLNdrlasylEKVRQLERDNAELENLIRERSQQQE-PLLCPSYQSYFKTIE---ELQQKILCSKSENARLVV 129
Cdd:COG5185 271 GENAESSKRLN-------ENANNLIKQFENTKEKIAEYTKSIDiKKATESLEEQLAAAEaeqELEESKRETETGIQNLTA 343
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 130 QIDNAKLAADDFRTKYQTEQSlrQLVEsdINSLRRILDELtlcrSDLEAQMESLKEELLSLKQNHEQEVNTLRCQLGDRL 209
Cdd:COG5185 344 EIEQGQESLTENLEAIKEEIE--NIVG--EVELSKSSEEL----DSFKDTIESTKESLDEIPQNQRGYAQEILATLEDTL 415
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 210 -NVEVDAApavDLNQVLNETRNQYEALVETNRreveqwfaTQTEELNKQVVSSSEQLQS-----YQAEIIELRRTVNALE 283
Cdd:COG5185 416 kAADRQIE---ELQRQIEQATSSNEEVSKLLN--------ELISELNKVMREADEESQSrleeaYDEINRSVRSKKEDLN 484
|
250 260 270 280
....*....|....*....|....*....|....*....|..
gi 10337581 284 IELQAQHNLRYSLENTLTESEARYSSQLSQVQSLITNVESQL 325
Cdd:COG5185 485 EELTQIESRVSTLKATLEKLRAKLERQLEGVRSKLDQVAESL 526
|
|
| PRK11281 |
PRK11281 |
mechanosensitive channel MscK; |
160-332 |
9.42e-03 |
|
mechanosensitive channel MscK;
Pssm-ID: 236892 [Multi-domain] Cd Length: 1113 Bit Score: 38.35 E-value: 9.42e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 160 NSLRRILDELTLcRSDLEAQMESLKEEL------LSLKQNHEQEVNTLRCQLGDrlnvevdaAPavdlnQVLNETRNQYE 233
Cdd:PRK11281 39 ADVQAQLDALNK-QKLLEAEDKLVQQDLeqtlalLDKIDRQKEETEQLKQQLAQ--------AP-----AKLRQAQAELE 104
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 234 ALVETNRREVEQWFATQT-EELNKQVVSSSEQLQSYQAEIIELrrtvNALEIELQaqhnlryslentltesearysSQLS 312
Cdd:PRK11281 105 ALKDDNDEETRETLSTLSlRQLESRLAQTLDQLQNAQNDLAEY----NSQLVSLQ---------------------TQPE 159
|
170 180
....*....|....*....|
gi 10337581 313 QVQSLITNVESQLAEIRSDL 332
Cdd:PRK11281 160 RAQAALYANSQRLQQIRNLL 179
|
|
| CusB_dom_1 |
pfam00529 |
Cation efflux system protein CusB domain 1; The cation efflux system protein CusB from E. coli ... |
174-334 |
9.61e-03 |
|
Cation efflux system protein CusB domain 1; The cation efflux system protein CusB from E. coli can be divided into four different domains, the first three domains of the protein are mostly beta-strands and the fourth forms an all alpha-helical domain. This entry represents the first beta-domain (domain 1) of CusB and it is formed by the N and C-terminal ends of the polypeptide (residues 89-102 and 324-385). CusB is part of the copper-transporting efflux system CusCFBA. This domain can also be found in other membrane-fusion proteins, such as HlyD, MdtN, MdtE and AaeA. HlyD is a component of the prototypical alpha-haemolysin (HlyA) bacterial type I secretion system, along with the other components HlyB and TolC. HlyD is anchored in the cytoplasmic membrane by a single transmembrane domain and has a large periplasmic domain within the carboxy-terminal 100 amino acids, HlyB and HlyD form a stable complex that binds the recombinant protein bearing a C-terminal HlyA signal sequence and ATP in the cytoplasm. HlyD, HlyB and TolC combine to form the three-component ABC transporter complex that forms a trans-membrane channel or pore through which HlyA can be transferred directly to the extracellular medium. Cutinase has been shown to be transported effectively through this pore.
Pssm-ID: 425733 [Multi-domain] Cd Length: 322 Bit Score: 37.79 E-value: 9.61e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 174 SDLEAQMESLKEELLSLKQNH---EQEVNTLRCQLGDRLNVEVDAAPAVDLNQVLNETRNQYEALVETNRREVeqwfaTQ 250
Cdd:pfam00529 54 TDYQAALDSAEAQLAKAQAQVarlQAELDRLQALESELAISRQDYDGATAQLRAAQAAVKAAQAQLAQAQIDL-----AR 128
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 10337581 251 TEELNKQVVSSSEQLQSYQAEIIELRRTVNALEIELQAqhnLRYSLENTLTESEARYSSQLSQVQSLITNVESQLAEIRS 330
Cdd:pfam00529 129 RRVLAPIGGISRESLVTAGALVAQAQANLLATVAQLDQ---IYVQITQSAAENQAEVRSELSGAQLQIAEAEAELKLAKL 205
|
....
gi 10337581 331 DLER 334
Cdd:pfam00529 206 DLER 209
|
|
| |