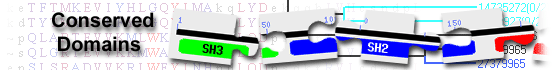|
Name |
Accession |
Description |
Interval |
E-value |
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
213-490 |
8.08e-11 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 65.08 E-value: 8.08e-11
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 213 CEQDVSRMRRQLDETNDELAQiarerdiLAHDNDNLQEQFAKAKQENQALSKKLNDTHNELNDIKQKVQDTNLEVNKLKN 292
Cdd:TIGR02168 682 LEEKIEELEEKIAELEKALAE-------LRKELEELEEELEQLRKELEELSRQISALRKDLARLEAEVEQLEERIAQLSK 754
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 293 ILKSEESENRQMMEQLRKANEDAENWENKARQSEADNNTLKLELITAEAEGNRLKEKVDSLNREVEQHLNAERSYKSQIS 372
Cdd:TIGR02168 755 ELTELEAEIEELEERLEEAEEELAEAEAEIEELEAQIEQLKEELKALREALDELRAELTLLNEEAANLRERLESLERRIA 834
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 373 TLHKSVVKMEEELQKVQFEKVSALADLSSTRELCIKldsskelLNRQLVAKDQEIEMRENELDSAHSEIELLRSQMANER 452
Cdd:TIGR02168 835 ATERRLEDLEEQIEELSEDIESLAAEIEELEELIEE-------LESELEALLNERASLEEALALLRSELEELSEELRELE 907
|
250 260 270
....*....|....*....|....*....|....*...
gi 1150561150 453 ISMQNLEALLVANRDKEYQSQIALQEKESEIQLLKEHL 490
Cdd:TIGR02168 908 SKRSELRRELEELREKLAQLELRLEGLEVRIDNLQERL 945
|
|
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
221-488 |
1.46e-10 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 64.19 E-value: 1.46e-10
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 221 RRQLDETNDELAQIARERDILAHDNDNLQEQFAKAKQENQALSKKLNDTHNELNDIKQkvqdtnlEVNKLKNILKSEESE 300
Cdd:COG1196 238 EAELEELEAELEELEAELEELEAELAELEAELEELRLELEELELELEEAQAEEYELLA-------ELARLEQDIARLEER 310
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 301 NRQMMEQLRKANEDAENWENKARQSEADNNTLKLELITAEAEGNRLKEKVDSLNREVEQHLNAERSYKSQISTLHKSVVK 380
Cdd:COG1196 311 RRELEERLEELEEELAELEEELEELEEELEELEEELEEAEEELEEAEAELAEAEEALLEAEAELAEAEEELEELAEELLE 390
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 381 MEEELQKVQFEKVSALADLSSTRELCIKLDSSKELLNRQLVAKDQEIEMRENELDSAHSEIELLRSQMANERISMQNLEA 460
Cdd:COG1196 391 ALRAAAELAAQLEELEEAEEALLERLERLEEELEELEEALAELEEEEEEEEEALEEAAEEEAELEEEEEALLELLAELLE 470
|
250 260
....*....|....*....|....*...
gi 1150561150 461 LLVANRDKEYQSQIALQEKESEIQLLKE 488
Cdd:COG1196 471 EAALLEAALAELLEELAEAAARLLLLLE 498
|
|
| CCDC158 |
pfam15921 |
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. ... |
140-548 |
9.84e-10 |
|
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. The function is not known.
Pssm-ID: 464943 [Multi-domain] Cd Length: 1112 Bit Score: 61.67 E-value: 9.84e-10
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 140 LEQRIEELECTVHNLDDERMEQMSNMTLMKETISTVEKEMKSLARKAMDTESELGRQKAENNSlrQCTEALIVCEQDVSR 219
Cdd:pfam15921 269 IEQLISEHEVEITGLTEKASSARSQANSIQSQLEIIQEQARNQNSMYMRQLSDLESTVSQLRS--ELREAKRMYEDKIEE 346
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 220 MRRQLDETNDELAQIARERDILAHDNDNLQEQFAK------AKQENQALSKKLN------DTHNEL--NDIKQKVQDTNL 285
Cdd:pfam15921 347 LEKQLVLANSELTEARTERDQFSQESGNLDDQLQKlladlhKREKELSLEKEQNkrlwdrDTGNSItiDHLRRELDDRNM 426
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 286 EVNKLKNILKSEESENRQMMEQ----LRKANEDAENWENKARQSEADNNTLK--LELITAEAEGNRLKEK-VDSLNREVE 358
Cdd:pfam15921 427 EVQRLEALLKAMKSECQGQMERqmaaIQGKNESLEKVSSLTAQLESTKEMLRkvVEELTAKKMTLESSERtVSDLTASLQ 506
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 359 QHLNAERSYKSQISTLHKSVVKMEEELQKVQFEK---VSALADLSSTRELCIKLDSSKELLNRQLVAKDQEIEMRENELD 435
Cdd:pfam15921 507 EKERAIEATNAEITKLRSRVDLKLQELQHLKNEGdhlRNVQTECEALKLQMAEKDKVIEILRQQIENMTQLVGQHGRTAG 586
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 436 SAHSEIELLRSQMANERISMQNLEALlvanRDKEYQSQIALQEKESEIQLLKEHLCLAENKMAIQSRDVAQ--------- 506
Cdd:pfam15921 587 AMQVEKAQLEKEINDRRLELQEFKIL----KDKKDAKIRELEARVSDLELEKVKLVNAGSERLRAVKDIKQerdqllnev 662
|
410 420 430 440
....*....|....*....|....*....|....*....|....
gi 1150561150 507 --FRNVVTQLEADLDITKRQLGTERFERERAVQELRRQNYSSNA 548
Cdd:pfam15921 663 ktSRNELNSLSEDYEVLKRNFRNKSEEMETTTNKLKMQLKSAQS 706
|
|
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
102-371 |
1.54e-09 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 61.11 E-value: 1.54e-09
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 102 ETERDVAFTDLRRMTTERDSLRERLKIAQ---ETAFNEKAHLEQRIEELECTVHNLDDERMEQMSNMTLMKETISTVEKE 178
Cdd:COG1196 224 ELEAELLLLKLRELEAELEELEAELEELEaelEELEAELAELEAELEELRLELEELELELEEAQAEEYELLAELARLEQD 303
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 179 MKSLARKAMDTESELGRQKAENNSLRQ----CTEALIVCEQDVSRMRRQLDETNDELAQIARERDILAHDNDNLQEQFAK 254
Cdd:COG1196 304 IARLEERRRELEERLEELEEELAELEEeleeLEEELEELEEELEEAEEELEEAEAELAEAEEALLEAEAELAEAEEELEE 383
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 255 AKQENQALSKKLNDTHNELNDIKQKVQDTNLEVNKLKNILKSEESENRQMMEQLRKANEDAENWENKARQSEADNNTLKL 334
Cdd:COG1196 384 LAEELLEALRAAAELAAQLEELEEAEEALLERLERLEEELEELEEALAELEEEEEEEEEALEEAAEEEAELEEEEEALLE 463
|
250 260 270
....*....|....*....|....*....|....*..
gi 1150561150 335 ELITAEAEGNRLKEKVDSLNREVEQHLNAERSYKSQI 371
Cdd:COG1196 464 LLAELLEEAALLEAALAELLEELAEAAARLLLLLEAE 500
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
246-543 |
1.78e-09 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 60.84 E-value: 1.78e-09
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 246 DNLQEQFAKAKQENQALSKKLNDTHNELNDIKQKVQDtnlevnklkniLKSEESENRQmmeQLRKANEDAENWENKARQS 325
Cdd:TIGR02168 680 EELEEKIEELEEKIAELEKALAELRKELEELEEELEQ-----------LRKELEELSR---QISALRKDLARLEAEVEQL 745
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 326 EADNNTLKLELITAEAEGNRLKEKVDSLNREVEQHlnaersyKSQISTLHKSVVKMEEELQKVQFEKVSALADLSSTREL 405
Cdd:TIGR02168 746 EERIAQLSKELTELEAEIEELEERLEEAEEELAEA-------EAEIEELEAQIEQLKEELKALREALDELRAELTLLNEE 818
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 406 CIKLDSSKELLNRQLVAKDQEIEMRENELDSAHSEIELLRSQMANERISMQNLEAllvanrdkeyqsqiALQEKESEIQL 485
Cdd:TIGR02168 819 AANLRERLESLERRIAATERRLEDLEEQIEELSEDIESLAAEIEELEELIEELES--------------ELEALLNERAS 884
|
250 260 270 280 290
....*....|....*....|....*....|....*....|....*....|....*...
gi 1150561150 486 LKEHLCLAENKMAIQSRDVAQFRNVVTQLEADLDITKRQLGTERFERERAVQELRRQN 543
Cdd:TIGR02168 885 LEEALALLRSELEELSEELRELESKRSELRRELEELREKLAQLELRLEGLEVRIDNLQ 942
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
102-386 |
2.61e-09 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 60.46 E-value: 2.61e-09
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 102 ETERDVAFTDLRRMTTERDSLR---ERLKIAQETAFNEKAHLEQRIEELECTVHNLDDERMEQMSNMTLMKETISTVEKE 178
Cdd:TIGR02168 697 EKALAELRKELEELEEELEQLRkelEELSRQISALRKDLARLEAEVEQLEERIAQLSKELTELEAEIEELEERLEEAEEE 776
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 179 MKSLARKAMDTESELGRQKAENNSLRQCTEALivcEQDVSRMRRQLDETNDELAQIARERDILAHDNDNLQEQFAKAKQE 258
Cdd:TIGR02168 777 LAEAEAEIEELEAQIEQLKEELKALREALDEL---RAELTLLNEEAANLRERLESLERRIAATERRLEDLEEQIEELSED 853
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 259 NQALSKKLNDTHNELNDIKQKVQDTNLEVNKLKNILKSEESENRQMMEQLRKANEDAENWENKARQSEADNNTLKLELIT 338
Cdd:TIGR02168 854 IESLAAEIEELEELIEELESELEALLNERASLEEALALLRSELEELSEELRELESKRSELRRELEELREKLAQLELRLEG 933
|
250 260 270 280
....*....|....*....|....*....|....*....|....*....
gi 1150561150 339 AEAEGNRLKEKV-DSLNREVEQHLNAERSYKSQISTLHKSVVKMEEELQ 386
Cdd:TIGR02168 934 LEVRIDNLQERLsEEYSLTLEEAEALENKIEDDEEEARRRLKRLENKIK 982
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
169-459 |
5.65e-09 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 59.30 E-value: 5.65e-09
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 169 KETISTVEKEMKSLARKAMDTESELGRQKAENNSLrqctealivcEQDVSRMRRQLDETNDELAQIARERDILAHDNDNL 248
Cdd:TIGR02168 245 QEELKEAEEELEELTAELQELEEKLEELRLEVSEL----------EEEIEELQKELYALANEISRLEQQKQILRERLANL 314
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 249 QEQFAKAKQENQALSKKLNDTHNELNDIKQKVQDTNLEVNKLKNILKSEESENRQMMEQLRKANEDAENWENKARQSEAD 328
Cdd:TIGR02168 315 ERQLEELEAQLEELESKLDELAEELAELEEKLEELKEELESLEAELEELEAELEELESRLEELEEQLETLRSKVAQLELQ 394
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 329 NNTLKLELITAEAEGNRLKEKVDSLNREVEQHlnaersyksqistlhksvvkmEEELQKVQFEKVSalADLSSTRELCIK 408
Cdd:TIGR02168 395 IASLNNEIERLEARLERLEDRRERLQQEIEEL---------------------LKKLEEAELKELQ--AELEELEEELEE 451
|
250 260 270 280 290
....*....|....*....|....*....|....*....|....*....|.
gi 1150561150 409 LDSSKELLNRQLVAKDQEIEMRENELDSAHSEIELLRSQMANERISMQNLE 459
Cdd:TIGR02168 452 LQEELERLEEALEELREELEEAEQALDAAERELAQLQARLDSLERLQENLE 502
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
221-540 |
9.62e-09 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 58.53 E-value: 9.62e-09
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 221 RRQLDETNDELAQIArerDILAHDN---DNLQEQfAKAKQENQALSKKLNDTHNELndIKQKVQDTNLEVNKLKNILKSE 297
Cdd:TIGR02168 178 ERKLERTRENLDRLE---DILNELErqlKSLERQ-AEKAERYKELKAELRELELAL--LVLRLEELREELEELQEELKEA 251
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 298 ESENRQMMEQLRKANEDAENWENKARQSEADNNTLKLELITAEAEGNRLKEKVDSLNREVEQHLNAERSYKSQISTLHKS 377
Cdd:TIGR02168 252 EEELEELTAELQELEEKLEELRLEVSELEEEIEELQKELYALANEISRLEQQKQILRERLANLERQLEELEAQLEELESK 331
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 378 VVKMEEELQKVQFEKVSALADLSSTRELCIKLDSSKELLNRQLVAKDQEIEMRENELDSAHSEIELLRSQMANERISMQN 457
Cdd:TIGR02168 332 LDELAEELAELEEKLEELKEELESLEAELEELEAELEELESRLEELEEQLETLRSKVAQLELQIASLNNEIERLEARLER 411
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 458 LEallvANRDKEYQSQIALQEKESEIQLLKEHLCLAENKMAIQSRdVAQFRNVVTQLEAdLDITKRQLGTERFERERAVQ 537
Cdd:TIGR02168 412 LE----DRRERLQQEIEELLKKLEEAELKELQAELEELEEELEEL-QEELERLEEALEE-LREELEEAEQALDAAERELA 485
|
...
gi 1150561150 538 ELR 540
Cdd:TIGR02168 486 QLQ 488
|
|
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
307-542 |
1.04e-08 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 58.41 E-value: 1.04e-08
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 307 QLRKANEDAENWENKARQSEADNNTLKLELITAEAEGNRLKEKVDSLNREVEQHLNAERSYKSQISTLHKSVVKMEEELQ 386
Cdd:COG1196 233 KLRELEAELEELEAELEELEAELEELEAELAELEAELEELRLELEELELELEEAQAEEYELLAELARLEQDIARLEERRR 312
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 387 kvqfekvSALADLSSTRELCIKLDSSKELLNRQLVAKDQEIEMRENELDSAHSEIELLRSQMANERISMQNLEALLVANR 466
Cdd:COG1196 313 -------ELEERLEELEEELAELEEELEELEEELEELEEELEEAEEELEEAEAELAEAEEALLEAEAELAEAEEELEELA 385
|
170 180 190 200 210 220 230
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*.
gi 1150561150 467 DKEYQSQIALQEKESEIQLLKEHLCLAENKMAIQSRDVAQFRNVVTQLEADLDITKRQLGTERFERERAVQELRRQ 542
Cdd:COG1196 386 EELLEALRAAAELAAQLEELEEAEEALLERLERLEEELEELEEALAELEEEEEEEEEALEEAAEEEAELEEEEEAL 461
|
|
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
26-543 |
1.58e-08 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 57.64 E-value: 1.58e-08
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 26 LKTTTRDREELKCMLEKYERHLAEIQGNVKVLKSERDKIFLLYEQAQEEITRLRREmmksckspKSTTAHAILRRVETER 105
Cdd:COG1196 241 LEELEAELEELEAELEELEAELAELEAELEELRLELEELELELEEAQAEEYELLAE--------LARLEQDIARLEERRR 312
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 106 DVAfTDLRRMTTERDSLRERLKIAQEtafnEKAHLEQRIEELECTVHNLDDERMEQMSNMTLMKETISTVEKEMKSLARK 185
Cdd:COG1196 313 ELE-ERLEELEEELAELEEELEELEE----ELEELEEELEEAEEELEEAEAELAEAEEALLEAEAELAEAEEELEELAEE 387
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 186 AMDTESELGRQKAENNSLRQCTEALivcEQDVSRMRRQLDETNDELAQIARERDILAHDNDNLQEQFAKAKQENQALSKK 265
Cdd:COG1196 388 LLEALRAAAELAAQLEELEEAEEAL---LERLERLEEELEELEEALAELEEEEEEEEEALEEAAEEEAELEEEEEALLEL 464
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 266 LNDTHNELNDIKQKVQDTNLEVNKLKNILKSEESENRQMMEQLRKANEdAENWENKARQSEADNNTLKLELITAEAEGNR 345
Cdd:COG1196 465 LAELLEEAALLEAALAELLEELAEAAARLLLLLEAEADYEGFLEGVKA-ALLLAGLRGLAGAVAVLIGVEAAYEAALEAA 543
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 346 LKEKVDSLNREVEQHLNAERSYKSQistlhksvvkmeEELQKVQFEKVSALADLSSTRELCIKLDSSKELLNRQLVAKDQ 425
Cdd:COG1196 544 LAAALQNIVVEDDEVAAAAIEYLKA------------AKAGRATFLPLDKIRARAALAAALARGAIGAAVDLVASDLREA 611
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 426 EIEMRENELDSAHSEIELLRSQMANERISMQNLEALLVAnRDKEYQSQIALQEKESEIQLLKEHLCLAENKMAIQSRDVA 505
Cdd:COG1196 612 DARYYVLGDTLLGRTLVAARLEAALRRAVTLAGRLREVT-LEGEGGSAGGSLTGGSRRELLAALLEAEAELEELAERLAE 690
|
490 500 510
....*....|....*....|....*....|....*...
gi 1150561150 506 QFRNVVTQLEADLDITKRQLGTERFERERAVQELRRQN 543
Cdd:COG1196 691 EELELEEALLAEEEEERELAEAEEERLEEELEEEALEE 728
|
|
| CCDC158 |
pfam15921 |
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. ... |
24-572 |
2.31e-08 |
|
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. The function is not known.
Pssm-ID: 464943 [Multi-domain] Cd Length: 1112 Bit Score: 57.44 E-value: 2.31e-08
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 24 ELLKTTTRDREELKCMLEKYERHLAEIQGNVKVLKSERDKIFLLYEQAQEEITRLRREMMKSCKSPKSTTAHAILRRVET 103
Cdd:pfam15921 321 DLESTVSQLRSELREAKRMYEDKIEELEKQLVLANSELTEARTERDQFSQESGNLDDQLQKLLADLHKREKELSLEKEQN 400
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 104 ER--------DVAFTDLRRMTTERDSLRERLKIAQETAFNE-KAHLEQRIEELECTvhnldDERMEQMSNMTL-MKETIS 173
Cdd:pfam15921 401 KRlwdrdtgnSITIDHLRRELDDRNMEVQRLEALLKAMKSEcQGQMERQMAAIQGK-----NESLEKVSSLTAqLESTKE 475
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 174 TVEKEMKSLARKAMDTESELGRQKAENNSLRQCTEALIVCEQDVSRMRRQLDETNDELAQIARERDILAH---DNDNLQE 250
Cdd:pfam15921 476 MLRKVVEELTAKKMTLESSERTVSDLTASLQEKERAIEATNAEITKLRSRVDLKLQELQHLKNEGDHLRNvqtECEALKL 555
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 251 QFAKAKQENQALSKKLNDTHNELNDIKQKVQDTNLEVNKLKnilksEESENRQMMEQLRKANEDAEnwENKARQSEADNN 330
Cdd:pfam15921 556 QMAEKDKVIEILRQQIENMTQLVGQHGRTAGAMQVEKAQLE-----KEINDRRLELQEFKILKDKK--DAKIRELEARVS 628
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 331 TLKLELITAEAEGNRLKEKVDSLNREVEQHLNAERSYKSQISTLHK--SVVK---------MEEELQKVQFEKVSALADL 399
Cdd:pfam15921 629 DLELEKVKLVNAGSERLRAVKDIKQERDQLLNEVKTSRNELNSLSEdyEVLKrnfrnkseeMETTTNKLKMQLKSAQSEL 708
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 400 SSTRELCIKLDSSKELLNRQLVAKDQEIEMRENELDSAHSEIELLRSQMANerismqnleallvANRDKEYqsqiaLQEK 479
Cdd:pfam15921 709 EQTRNTLKSMEGSDGHAMKVAMGMQKQITAKRGQIDALQSKIQFLEEAMTN-------------ANKEKHF-----LKEE 770
|
490 500 510 520 530 540 550 560
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 480 ESEIQLLKEHLCLAENKMA----IQSRDVAQFRNVVTQLEADLDITKRQLG-----TERFERERA---------VQELRR 541
Cdd:pfam15921 771 KNKLSQELSTVATEKNKMAgeleVLRSQERRLKEKVANMEVALDKASLQFAecqdiIQRQEQESVrlklqhtldVKELQG 850
|
570 580 590
....*....|....*....|....*....|..
gi 1150561150 542 QNYSSNayhmsSTMKPN-TKCHSPERAHHRSP 572
Cdd:pfam15921 851 PGYTSN-----SSMKPRlLQPASFTRTHSNVP 877
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
98-398 |
3.81e-08 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 56.61 E-value: 3.81e-08
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 98 LRRVETERDVAF---TDLRRMTTERDSLRERLKIAQETAFNEKAHLEQRIEELECTVHNLDDERMEQMSNMTLMKETIST 174
Cdd:TIGR02169 697 LRRIENRLDELSqelSDASRKIGEIEKEIEQLEQEEEKLKERLEELEEDLSSLEQEIENVKSELKELEARIEELEEDLHK 776
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 175 VEKEMKSLarKAMDTESELGRQKAENNSLrqctealivcEQDVSRMRRQLDETNDELAQIARERDILAHDNDNLQEQfak 254
Cdd:TIGR02169 777 LEEALNDL--EARLSHSRIPEIQAELSKL----------EEEVSRIEARLREIEQKLNRLTLEKEYLEKEIQELQEQ--- 841
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 255 akqenqalskkLNDTHNELNDIKQKVQDTNLEVNKLKNILKSEESENRQMMEQLRKANEDAENWENKARQSEADNNTLKL 334
Cdd:TIGR02169 842 -----------RIDLKEQIKSIEKEIENLNGKKEELEEELEELEAALRDLESRLGDLKKERDELEAQLRELERKIEELEA 910
|
250 260 270 280 290 300
....*....|....*....|....*....|....*....|....*....|....*....|....
gi 1150561150 335 ELITAEAEGNRLKEKVDSLNREVEQHLNAERSYKSqISTLHKSVVKMEEELQKVQfEKVSALAD 398
Cdd:TIGR02169 911 QIEKKRKRLSELKAKLEALEEELSEIEDPKGEDEE-IPEEELSLEDVQAELQRVE-EEIRALEP 972
|
|
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
285-542 |
1.09e-06 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 51.86 E-value: 1.09e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 285 LEVNKLKNILKSEESENRQMMEQLRKANEDAENWENKARQSEADNNTLKLELITAEAEGNRLKEKVDSLNREVEQHLNAE 364
Cdd:COG1196 225 LEAELLLLKLRELEAELEELEAELEELEAELEELEAELAELEAELEELRLELEELELELEEAQAEEYELLAELARLEQDI 304
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 365 RSYKSQISTLHKSVVKMEEELQKVQFEKVSALADLSSTRELCIKLDSSKELL-------NRQLVAKDQEIEMRENELDSA 437
Cdd:COG1196 305 ARLEERRRELEERLEELEEELAELEEELEELEEELEELEEELEEAEEELEEAeaelaeaEEALLEAEAELAEAEEELEEL 384
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 438 HSEIELLRSQMANERISMQNLEALLVAN---RDKEYQSQIALQEKESEIQLLKEHLCLAENKMAIQSRDVAQFRNVVTQL 514
Cdd:COG1196 385 AEELLEALRAAAELAAQLEELEEAEEALlerLERLEEELEELEEALAELEEEEEEEEEALEEAAEEEAELEEEEEALLEL 464
|
250 260
....*....|....*....|....*...
gi 1150561150 515 EADLDITKRQLGTERFERERAVQELRRQ 542
Cdd:COG1196 465 LAELLEEAALLEAALAELLEELAEAAAR 492
|
|
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
305-542 |
4.06e-06 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 49.94 E-value: 4.06e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 305 MEQLRKANEDAENW-ENKARQSEADNNTLKLELITAEAEGNRLKEKVDSLNREVEQHLNAERSYKSQISTLHKSVVKMEE 383
Cdd:COG1196 202 LEPLERQAEKAERYrELKEELKELEAELLLLKLRELEAELEELEAELEELEAELEELEAELAELEAELEELRLELEELEL 281
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 384 ELQKVQFEKVSALADLSSTRELCIKLDSSKELLNRQLVAKDQEIEMRENELDSAHSEIELLRSQMANERISMQNLEALLV 463
Cdd:COG1196 282 ELEEAQAEEYELLAELARLEQDIARLEERRRELEERLEELEEELAELEEELEELEEELEELEEELEEAEEELEEAEAELA 361
|
170 180 190 200 210 220 230
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....
gi 1150561150 464 ANRDKEYQSQIALQEKESEIQLLKEHLCLAENKMAIQSRDVAQFRNVVTQLEADLDITKRQLGTERFERERAVQELRRQ 542
Cdd:COG1196 362 EAEEALLEAEAELAEAEEELEELAEELLEALRAAAELAAQLEELEEAEEALLERLERLEEELEELEEALAELEEEEEEE 440
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
98-447 |
6.48e-06 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 49.30 E-value: 6.48e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 98 LRRVETERDVAFTDLRRMTTERDSL---RERLKIAQETAFNEKAHleqRIEELECTVHNLDDERMEQMSNMTLMKETIST 174
Cdd:TIGR02169 186 IERLDLIIDEKRQQLERLRREREKAeryQALLKEKREYEGYELLK---EKEALERQKEAIERQLASLEEELEKLTEEISE 262
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 175 VEKEMKSLARKaMDTESELGRQKAENNSLRQCTEALIVcEQDVSRMRRQLDETNDELAQIARERDILAHDNDNLQEqfak 254
Cdd:TIGR02169 263 LEKRLEEIEQL-LEELNKKIKDLGEEEQLRVKEKIGEL-EAEIASLERSIAEKERELEDAEERLAKLEAEIDKLLA---- 336
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 255 akqenqalskklndthnELNDIKQKVQDTNLEVNKLKNILKSEESEnrqmMEQLRkanedaenweNKARQSEADNNTLKL 334
Cdd:TIGR02169 337 -----------------EIEELEREIEEERKRRDKLTEEYAELKEE----LEDLR----------AELEEVDKEFAETRD 385
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 335 ELITAEAEGNRLKEKVDSLNREVEQHLNAERSYKSQISTLHKSVVKMEEELQKVQFEKVSALADLSSTRELCIKLDSSKE 414
Cdd:TIGR02169 386 ELKDYREKLEKLKREINELKRELDRLQEELQRLSEELADLNAAIAGIEAKINELEEEKEDKALEIKKQEWKLEQLAADLS 465
|
330 340 350
....*....|....*....|....*....|...
gi 1150561150 415 LLNRQLVAKDQEIEMRENELDSAHSEIELLRSQ 447
Cdd:TIGR02169 466 KYEQELYDLKEEYDRVEKELSKLQRELAEAEAQ 498
|
|
| PRK02224 |
PRK02224 |
DNA double-strand break repair Rad50 ATPase; |
90-459 |
1.38e-05 |
|
DNA double-strand break repair Rad50 ATPase;
Pssm-ID: 179385 [Multi-domain] Cd Length: 880 Bit Score: 48.11 E-value: 1.38e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 90 KSTTAHAILRRVETERDVAFTDLRRMTTERDSLRERLKIAQETaFNEKAHLEQRIEELECTVHNLDDERMEQMSNMTLMK 169
Cdd:PRK02224 200 EEKDLHERLNGLESELAELDEEIERYEEQREQARETRDEADEV-LEEHEERREELETLEAEIEDLRETIAETEREREELA 278
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 170 ETISTVEKEMKSLARKAMDTESELGRQKAENNSLRQCTEALivcEQDVSRMRRQLDETNDELAQIARERDILAHDNDNLQ 249
Cdd:PRK02224 279 EEVRDLRERLEELEEERDDLLAEAGLDDADAEAVEARREEL---EDRDEELRDRLEECRVAAQAHNEEAESLREDADDLE 355
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 250 EQFAKAKQENQALSKKLNDTHNELNDIKQKVQDTNLEVNKLKNILKSEESEnrqmMEQLRKANEDAENWENKARQSEADN 329
Cdd:PRK02224 356 ERAEELREEAAELESELEEAREAVEDRREEIEELEEEIEELRERFGDAPVD----LGNAEDFLEELREERDELREREAEL 431
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 330 NTLKLELITAEAEGNRLKE--KVDSLNREVEQ--HLNAERSYKSQISTLHKSVVKMEEELQKVQfEKVSALADLSSTREL 405
Cdd:PRK02224 432 EATLRTARERVEEAEALLEagKCPECGQPVEGspHVETIEEDRERVEELEAELEDLEEEVEEVE-ERLERAEDLVEAEDR 510
|
330 340 350 360 370
....*....|....*....|....*....|....*....|....*....|....
gi 1150561150 406 CIKLDSSKELLNRQLVAKDQEIEMRENELDSAHSEIELLRSQMANERISMQNLE 459
Cdd:PRK02224 511 IERLEERREDLEELIAERRETIEEKRERAEELRERAAELEAEAEEKREAAAEAE 564
|
|
| PRK03918 |
PRK03918 |
DNA double-strand break repair ATPase Rad50; |
40-534 |
1.44e-05 |
|
DNA double-strand break repair ATPase Rad50;
Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 48.14 E-value: 1.44e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 40 LEKYERHLAEIQGNVKVLKSERDKIFLLYEQAQEEITRLRREMMKSCKSPKSTTAHaiLRRVETERDVAFTDLRRMTTER 119
Cdd:PRK03918 160 YENAYKNLGEVIKEIKRRIERLEKFIKRTENIEELIKEKEKELEEVLREINEISSE--LPELREELEKLEKEVKELEELK 237
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 120 DSLRErLKIAQETAFNEKAHLEQRIEELECTVHNLDDERMEQMSNMTLMKEtISTVEKEMKSLARKAMDTESELGRQKAE 199
Cdd:PRK03918 238 EEIEE-LEKELESLEGSKRKLEEKIRELEERIEELKKEIEELEEKVKELKE-LKEKAEEYIKLSEFYEEYLDELREIEKR 315
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 200 NNSLRQCTEALIVCEQDVSRMRRQLDETNDELAQIARERDILAHDNDNLQEQFAKAKQENQALSKKLNDTHNELNDIKQK 279
Cdd:PRK03918 316 LSRLEEEINGIEERIKELEEKEERLEELKKKLKELEKRLEELEERHELYEEAKAKKEELERLKKRLTGLTPEKLEKELEE 395
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 280 VQDTNLEVNKLKNILKSEESENRQMMEQLRKANE----------------DAENWENKARQSEADNNTLKLELITAEAEG 343
Cdd:PRK03918 396 LEKAKEEIEEEISKITARIGELKKEIKELKKAIEelkkakgkcpvcgrelTEEHRKELLEEYTAELKRIEKELKEIEEKE 475
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 344 NRLKEKVdslnREVEQHLNAERSYKSQISTLhKSVVKMEEELQKVQFEKVSALA-DLSSTRELCIKLDSSKELLNRQLVA 422
Cdd:PRK03918 476 RKLRKEL----RELEKVLKKESELIKLKELA-EQLKELEEKLKKYNLEELEKKAeEYEKLKEKLIKLKGEIKSLKKELEK 550
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 423 KD---QEIEMRENELDSAHSEIELLRSQMANERISMQNLEALLVANRDKEYQSQIALQEKESEIQLLKEHLCLAENKMAI 499
Cdd:PRK03918 551 LEelkKKLAELEKKLDELEEELAELLKELEELGFESVEELEERLKELEPFYNEYLELKDAEKELEREEKELKKLEEELDK 630
|
490 500 510
....*....|....*....|....*....|....*
gi 1150561150 500 QSRDVAQFRNVVTQLEADLDITKRQLGTERFERER 534
Cdd:PRK03918 631 AFEELAETEKRLEELRKELEELEKKYSEEEYEELR 665
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
35-368 |
1.47e-05 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 48.13 E-value: 1.47e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 35 ELKCMLEKYERHLAEIQgnVKVLKSERDKIFLLYEQAQEEITRLRREMmksckspksttahailrrveTERDVAFTDLRR 114
Cdd:TIGR02168 217 ELKAELRELELALLVLR--LEELREELEELQEELKEAEEELEELTAEL--------------------QELEEKLEELRL 274
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 115 MTTERDSLRERLKIAQETAFNEKAHLEQRIEELECTVHNLDDERMEqmsnmtlMKETISTVEKEMKSLARKAMDTESELG 194
Cdd:TIGR02168 275 EVSELEEEIEELQKELYALANEISRLEQQKQILRERLANLERQLEE-------LEAQLEELESKLDELAEELAELEEKLE 347
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 195 RQKAENNSLRqctEALIVCEQDVSRMRRQLDETNDELAQIARERDILAHDNDNLQEQFAKAKQENQALSKKLNDTHNELN 274
Cdd:TIGR02168 348 ELKEELESLE---AELEELEAELEELESRLEELEEQLETLRSKVAQLELQIASLNNEIERLEARLERLEDRRERLQQEIE 424
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 275 DIKQKVQDTNLEVnklkniLKSEESENRQMMEQLRKANEDAENWENKARQSEAdnnTLKLELITAEAEGNRLKEKVDSLN 354
Cdd:TIGR02168 425 ELLKKLEEAELKE------LQAELEELEEELEELQEELERLEEALEELREELE---EAEQALDAAERELAQLQARLDSLE 495
|
330
....*....|....
gi 1150561150 355 REVEQHLNAERSYK 368
Cdd:TIGR02168 496 RLQENLEGFSEGVK 509
|
|
| CwlO1 |
COG3883 |
Uncharacterized N-terminal coiled-coil domain of peptidoglycan hydrolase CwlO [Function ... |
214-384 |
1.49e-05 |
|
Uncharacterized N-terminal coiled-coil domain of peptidoglycan hydrolase CwlO [Function unknown];
Pssm-ID: 443091 [Multi-domain] Cd Length: 379 Bit Score: 47.52 E-value: 1.49e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 214 EQDVSRMRRQLDETNDELAQIARERDILAHDNDNLQEQFAKAKQENQALSKKLNDTHNELNDIKQKVQDTNLEVNKLKNI 293
Cdd:COG3883 29 QAELEAAQAELDALQAELEELNEEYNELQAELEALQAEIDKLQAEIAEAEAEIEERREELGERARALYRSGGSVSYLDVL 108
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 294 LKSEE---------------SENRQMMEQLRKANEDAENWENKARQSEADNNTLKLELITAEAEGNRLKEK----VDSLN 354
Cdd:COG3883 109 LGSESfsdfldrlsalskiaDADADLLEELKADKAELEAKKAELEAKLAELEALKAELEAAKAELEAQQAEqealLAQLS 188
|
170 180 190
....*....|....*....|....*....|
gi 1150561150 355 REVEQHLNAERSYKSQISTLHKSVVKMEEE 384
Cdd:COG3883 189 AEEAAAEAQLAELEAELAAAEAAAAAAAAA 218
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
203-519 |
3.07e-05 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 46.98 E-value: 3.07e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 203 LRQCTEALIVCEQDVSRMRRQLDETNDELAQIARER-------DILAHDNDNLQEQFAKAKQEN----QALSKKLNDTHN 271
Cdd:TIGR02169 172 KEKALEELEEVEENIERLDLIIDEKRQQLERLRRERekaeryqALLKEKREYEGYELLKEKEALerqkEAIERQLASLEE 251
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 272 ELNDIKQKVQDTNLEVNKLKNILKSE--------ESENRQMMEQLRKANEDAENWENKARQSEADNNTLKLELITAEAEG 343
Cdd:TIGR02169 252 ELEKLTEEISELEKRLEEIEQLLEELnkkikdlgEEEQLRVKEKIGELEAEIASLERSIAEKERELEDAEERLAKLEAEI 331
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 344 NRLKEKVDSLNREVEQHLNAERSYKSQISTLHKSVVKMEEELQKVQFEKVSALADLSSTRELCIKLDSSKELLNRQLVAK 423
Cdd:TIGR02169 332 DKLLAEIEELEREIEEERKRRDKLTEEYAELKEELEDLRAELEEVDKEFAETRDELKDYREKLEKLKREINELKRELDRL 411
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 424 DQEIEMRENELDSAHSEIELLRSQMAN---------ERIS-----MQNLEALLVANRDKEYQSQIALQEKESEIQLLKEH 489
Cdd:TIGR02169 412 QEELQRLSEELADLNAAIAGIEAKINEleeekedkaLEIKkqewkLEQLAADLSKYEQELYDLKEEYDRVEKELSKLQRE 491
|
330 340 350
....*....|....*....|....*....|
gi 1150561150 490 LCLAENKMAIQSRDVAQFRNVVTQLEADLD 519
Cdd:TIGR02169 492 LAEAEAQARASEERVRGGRAVEEVLKASIQ 521
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
24-292 |
5.99e-05 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 46.20 E-value: 5.99e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 24 ELLKTTTRDREELKCMLEKYERHLAEIQGNVKVLKSERDKIFLLYEQAQEEITRLRREMMKSCKSPKS-----TTAHAIL 98
Cdd:TIGR02168 246 EELKEAEEELEELTAELQELEEKLEELRLEVSELEEEIEELQKELYALANEISRLEQQKQILRERLANlerqlEELEAQL 325
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 99 RRVETERDVAFTDLRRMTTERDSLRERLKIAQEtafnEKAHLEQRIEELECTVHNLDDERMEQMSNMTLMKETISTVEKE 178
Cdd:TIGR02168 326 EELESKLDELAEELAELEEKLEELKEELESLEA----ELEELEAELEELESRLEELEEQLETLRSKVAQLELQIASLNNE 401
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 179 MKSLARKAMDTESELGRQKAENNSLRQCTEalivcEQDVSRMRRQLDETNDELAQIARERDILAHDNDNLQEQFAKAKQE 258
Cdd:TIGR02168 402 IERLEARLERLEDRRERLQQEIEELLKKLE-----EAELKELQAELEELEEELEELQEELERLEEALEELREELEEAEQA 476
|
250 260 270
....*....|....*....|....*....|....*..
gi 1150561150 259 NQALSKKLNDTHNE---LNDIKQKVQDTNLEVNKLKN 292
Cdd:TIGR02168 477 LDAAERELAQLQARldsLERLQENLEGFSEGVKALLK 513
|
|
| EnvC |
COG4942 |
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
170-389 |
7.24e-05 |
|
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 45.53 E-value: 7.24e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 170 ETISTVEKEMKSLARKAMDTESELGRQKAENNSLRQCTEALivcEQDVSRMRRQLDETNDELAQiarerdilahdndnLQ 249
Cdd:COG4942 20 DAAAEAEAELEQLQQEIAELEKELAALKKEEKALLKQLAAL---ERRIAALARRIRALEQELAA--------------LE 82
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 250 EQFAKAKQENQALSKKLNDTHNELNDIKQKVQdTNLEVNKLKNILKSEESE------------NRQMMEQLRKANEDAEN 317
Cdd:COG4942 83 AELAELEKEIAELRAELEAQKEELAELLRALY-RLGRQPPLALLLSPEDFLdavrrlqylkylAPARREQAEELRADLAE 161
|
170 180 190 200 210 220 230
....*....|....*....|....*....|....*....|....*....|....*....|....*....|..
gi 1150561150 318 WENKARQSEADNNTLKLELITAEAEGNRLKEKVDSLNREVEQHLNAERSYKSQISTLHKSVVKMEEELQKVQ 389
Cdd:COG4942 162 LAALRAELEAERAELEALLAELEEERAALEALKAERQKLLARLEKELAELAAELAELQQEAEELEALIARLE 233
|
|
| COG4913 |
COG4913 |
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; |
24-255 |
7.93e-05 |
|
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown];
Pssm-ID: 443941 [Multi-domain] Cd Length: 1089 Bit Score: 45.68 E-value: 7.93e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 24 ELLKTTTRDREELKCMLEKYERHlAEIQGNVKVLKSERDKI-----FLLYEQAQEEITRLRREmmksckspksttahaiL 98
Cdd:COG4913 242 EALEDAREQIELLEPIRELAERY-AAARERLAELEYLRAALrlwfaQRRLELLEAELEELRAE----------------L 304
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 99 RRVETERDVAFTDLRRMTTERDSLRERLkiaQETAFNEKAHLEQRIEELECTVHNLDDERMEQMSNMTLMKETISTVEKE 178
Cdd:COG4913 305 ARLEAELERLEARLDALREELDELEAQI---RGNGGDRLEQLEREIERLERELEERERRRARLEALLAALGLPLPASAEE 381
|
170 180 190 200 210 220 230
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*..
gi 1150561150 179 MKSLARKAMDTESELGRQKAENNSLRqcTEAlivcEQDVSRMRRQLDETNDELAQIARERDILAHDNDNLQEQFAKA 255
Cdd:COG4913 382 FAALRAEAAALLEALEEELEALEEAL--AEA----EAALRDLRRELRELEAEIASLERRKSNIPARLLALRDALAEA 452
|
|
| PRK02224 |
PRK02224 |
DNA double-strand break repair Rad50 ATPase; |
23-450 |
8.31e-05 |
|
DNA double-strand break repair Rad50 ATPase;
Pssm-ID: 179385 [Multi-domain] Cd Length: 880 Bit Score: 45.80 E-value: 8.31e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 23 VELLKTTTRDREELKCMLEKYErhlaEIQGNVKVLKSERDKIFLLYEQAQEEITRLRREMMKSckspKSTTAHAilrrvE 102
Cdd:PRK02224 205 HERLNGLESELAELDEEIERYE----EQREQARETRDEADEVLEEHEERREELETLEAEIEDL----RETIAET-----E 271
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 103 TERDVAFTDLRRMTTERDSLRERLKIAQETAFNEKAH---LEQRIEELECTVHNLDDERMEQmsnmtlmKETISTVEKEM 179
Cdd:PRK02224 272 REREELAEEVRDLRERLEELEEERDDLLAEAGLDDADaeaVEARREELEDRDEELRDRLEEC-------RVAAQAHNEEA 344
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 180 KSLARKAMDTESELGRQKAENNSLrqctealivcEQDVSRMRRQLDETNDELAQIARERDILAHDNDNLQEQFAKAKQEN 259
Cdd:PRK02224 345 ESLREDADDLEERAEELREEAAEL----------ESELEEAREAVEDRREEIEELEEEIEELRERFGDAPVDLGNAEDFL 414
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 260 QALSKKLNDTHNELNDIKQKVQDTNLEVNKLKNILKS----------EESENRQMMEQLRKANED--AENWENKARQSEA 327
Cdd:PRK02224 415 EELREERDELREREAELEATLRTARERVEEAEALLEAgkcpecgqpvEGSPHVETIEEDRERVEEleAELEDLEEEVEEV 494
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 328 DNNTLKLE-LITAEAEGNRLKEKVDSLNREVEQHLNAERSYKSQISTLHKSVVKMEEELQKVQFEKVSALADLSSTRELC 406
Cdd:PRK02224 495 EERLERAEdLVEAEDRIERLEERREDLEELIAERRETIEEKRERAEELRERAAELEAEAEEKREAAAEAEEEAEEAREEV 574
|
410 420 430 440
....*....|....*....|....*....|....*....|....
gi 1150561150 407 IKLDSSKELLNRQLVAKDQeIEMRENELDSAHSEIELLRSQMAN 450
Cdd:PRK02224 575 AELNSKLAELKERIESLER-IRTLLAAIADAEDEIERLREKREA 617
|
|
| CwlO1 |
COG3883 |
Uncharacterized N-terminal coiled-coil domain of peptidoglycan hydrolase CwlO [Function ... |
223-426 |
9.64e-05 |
|
Uncharacterized N-terminal coiled-coil domain of peptidoglycan hydrolase CwlO [Function unknown];
Pssm-ID: 443091 [Multi-domain] Cd Length: 379 Bit Score: 44.82 E-value: 9.64e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 223 QLDETNDELAQIARERDILAHDNDNLQEQFAKAKQENQALSKKLNDTHNELNDIKQKVQDTNLEVNKLKNILKS------ 296
Cdd:COG3883 17 QIQAKQKELSELQAELEAAQAELDALQAELEELNEEYNELQAELEALQAEIDKLQAEIAEAEAEIEERREELGEraraly 96
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 297 EESENRQMMEQLRKANEDAE---NWENKARQSEADNNTLKlELITAEAEGNRLKEKVDSLNREVEQHL----NAERSYKS 369
Cdd:COG3883 97 RSGGSVSYLDVLLGSESFSDfldRLSALSKIADADADLLE-ELKADKAELEAKKAELEAKLAELEALKaeleAAKAELEA 175
|
170 180 190 200 210
....*....|....*....|....*....|....*....|....*....|....*..
gi 1150561150 370 QISTLHKSVVKMEEELQKVQFEKVSALADLSSTRELCIKLDSSKELLNRQLVAKDQE 426
Cdd:COG3883 176 QQAEQEALLAQLSAEEAAAEAQLAELEAELAAAEAAAAAAAAAAAAAAAAAAAAAAA 232
|
|
| PRK09039 |
PRK09039 |
peptidoglycan -binding protein; |
347-475 |
2.46e-04 |
|
peptidoglycan -binding protein;
Pssm-ID: 181619 [Multi-domain] Cd Length: 343 Bit Score: 43.42 E-value: 2.46e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 347 KEKV-DSLNREVEQ---HLNAERSYKSQistlhksvvkMEEELQKVQFEKVSALADLSSTRELCIKLDSSKELLNRQLVA 422
Cdd:PRK09039 51 KDSAlDRLNSQIAEladLLSLERQGNQD----------LQDSVANLRASLSAAEAERSRLQALLAELAGAGAAAEGRAGE 120
|
90 100 110 120 130
....*....|....*....|....*....|....*....|....*....|....*
gi 1150561150 423 KDQEIEMRENELDSAHSEIELLRSQMANERISMQNLEALLVA--NRDKEYQSQIA 475
Cdd:PRK09039 121 LAQELDSEKQVSARALAQVELLNQQIAALRRQLAALEAALDAseKRDRESQAKIA 175
|
|
| EnvC |
COG4942 |
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
242-468 |
2.60e-04 |
|
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 43.60 E-value: 2.60e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 242 AHDNDNLQEQFAKAKQENQALSKKLNDTHNELNDIKQKVQDTNLEVNKLKNILKSEESENRQMMEQLRKANEDAENWENK 321
Cdd:COG4942 19 ADAAAEAEAELEQLQQEIAELEKELAALKKEEKALLKQLAALERRIAALARRIRALEQELAALEAELAELEKEIAELRAE 98
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 322 ARQSEADnntLKLELITAEAEGNRLKEKVDSLNREVEQHLNAERSYKSQISTLHKSVVKMEEELQKVQFEKVSALADLSS 401
Cdd:COG4942 99 LEAQKEE---LAELLRALYRLGRQPPLALLLSPEDFLDAVRRLQYLKYLAPARREQAEELRADLAELAALRAELEAERAE 175
|
170 180 190 200 210 220
....*....|....*....|....*....|....*....|....*....|....*....|....*..
gi 1150561150 402 TRELCIKLDSSKELLNRQLVAKDQEIEMRENELDSAHSEIELLRSQMANERISMQNLEALLVANRDK 468
Cdd:COG4942 176 LEALLAELEEERAALEALKAERQKLLARLEKELAELAAELAELQQEAEELEALIARLEAEAAAAAER 242
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
26-366 |
2.71e-04 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 43.90 E-value: 2.71e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 26 LKTTTRDREELKCMLEKYERHLAEIQGNVKVLKSERDKIFLLYEQAQEEITRLRREMMKSCKspksttahailrrveter 105
Cdd:TIGR02169 232 KEALERQKEAIERQLASLEEELEKLTEEISELEKRLEEIEQLLEELNKKIKDLGEEEQLRVK------------------ 293
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 106 dvafTDLRRMTTERDSLRERLkiaqetafnekAHLEQRIEELECTVHNLDDERMEQMSNMTLMKETISTVEKEMKSLark 185
Cdd:TIGR02169 294 ----EKIGELEAEIASLERSI-----------AEKERELEDAEERLAKLEAEIDKLLAEIEELEREIEEERKRRDKL--- 355
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 186 amdtESELGRQKAENNSLRQCTEALivcEQDVSRMRRQLDETNDELAQIARERDILAHDNDNLQEqfakakqENQALSKK 265
Cdd:TIGR02169 356 ----TEEYAELKEELEDLRAELEEV---DKEFAETRDELKDYREKLEKLKREINELKRELDRLQE-------ELQRLSEE 421
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 266 LNDTHNELNDIKQKVQDTNLEVNKLKNILKSEESENRQMMEQLRKANEDAENWENKARQSEADNNTLKLELITAEAEGNR 345
Cdd:TIGR02169 422 LADLNAAIAGIEAKINELEEEKEDKALEIKKQEWKLEQLAADLSKYEQELYDLKEEYDRVEKELSKLQRELAEAEAQARA 501
|
330 340
....*....|....*....|.
gi 1150561150 346 LKEKVDSlNREVEQHLNAERS 366
Cdd:TIGR02169 502 SEERVRG-GRAVEEVLKASIQ 521
|
|
| EnvC |
COG4942 |
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
299-534 |
3.71e-04 |
|
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 43.21 E-value: 3.71e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 299 SENRQMMEQLRKANEDAENWENKARQSEADnntLKLELITAEAEGNRLKEKVDSLNREVEQHLNAERSYKSQISTLHKSV 378
Cdd:COG4942 23 AEAEAELEQLQQEIAELEKELAALKKEEKA---LLKQLAALERRIAALARRIRALEQELAALEAELAELEKEIAELRAEL 99
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 379 VKMEEELQKVqfekVSALADLSSTRELCIKLDS-SKELLNRQLVAKDQEIEMRENELDSAHSEIELLRSQMANERISMQN 457
Cdd:COG4942 100 EAQKEELAEL----LRALYRLGRQPPLALLLSPeDFLDAVRRLQYLKYLAPARREQAEELRADLAELAALRAELEAERAE 175
|
170 180 190 200 210 220 230
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*..
gi 1150561150 458 LEALLVANRDKEYQSQIALQEKESEIQLLKEHLCLAENKMAIQSRDVAQFRNVVTQLEADLDITKRQLGTERFERER 534
Cdd:COG4942 176 LEALLAELEEERAALEALKAERQKLLARLEKELAELAAELAELQQEAEELEALIARLEAEAAAAAERTPAAGFAALK 252
|
|
| CCDC158 |
pfam15921 |
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. ... |
110-537 |
6.75e-04 |
|
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. The function is not known.
Pssm-ID: 464943 [Multi-domain] Cd Length: 1112 Bit Score: 42.80 E-value: 6.75e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 110 TDLRRMTTERDSL---RERLKIAQETAFNEKAHLEQRIEELECTVHNLDDERMEQMSNMTLMKETISTVEKEMKSLarkA 186
Cdd:pfam15921 117 TKLQEMQMERDAMadiRRRESQSQEDLRNQLQNTVHELEAAKCLKEDMLEDSNTQIEQLRKMMLSHEGVLQEIRSI---L 193
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 187 MDTESELGRQKAENNSLRqcTEALIVCEQDVSRMRRQLDEtndelaqiarERDILAHDNDNLQEQFAKAKQENQALSKKL 266
Cdd:pfam15921 194 VDFEEASGKKIYEHDSMS--TMHFRSLGSAISKILRELDT----------EISYLKGRIFPVEDQLEALKSESQNKIELL 261
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 267 NDTHNElnDIKQKVQDTNLEVNKLKNILKSEESENRQMMEQLRKANEDAENWENKARQSEADNNTLKLELITAEAEGNRL 346
Cdd:pfam15921 262 LQQHQD--RIEQLISEHEVEITGLTEKASSARSQANSIQSQLEIIQEQARNQNSMYMRQLSDLESTVSQLRSELREAKRM 339
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 347 KE-KVDSLNREV---EQHLNAERSYKSQIStlhKSVVKMEEELQKVqfekvsaLADL-SSTRELCIKLDSSKELLNRqlv 421
Cdd:pfam15921 340 YEdKIEELEKQLvlaNSELTEARTERDQFS---QESGNLDDQLQKL-------LADLhKREKELSLEKEQNKRLWDR--- 406
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 422 akdqeiemrenelDSAHS-EIELLRSQMANERISMQNLEALLVANRdKEYQSQiaLQEKESEIQLLKEHLCLAENKMAIQ 500
Cdd:pfam15921 407 -------------DTGNSiTIDHLRRELDDRNMEVQRLEALLKAMK-SECQGQ--MERQMAAIQGKNESLEKVSSLTAQL 470
|
410 420 430 440
....*....|....*....|....*....|....*....|...
gi 1150561150 501 SRDVAQFRNVVTQLEAD---LDITKR---QLGTERFERERAVQ 537
Cdd:pfam15921 471 ESTKEMLRKVVEELTAKkmtLESSERtvsDLTASLQEKERAIE 513
|
|
| EnvC |
COG4942 |
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
260-462 |
7.03e-04 |
|
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 42.06 E-value: 7.03e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 260 QALSKKLNDTHNELNDIKQKVQDTNLEVNKLKNILKSEESENRQMMEQLRKANEDAENWENKARQSEADNNTLKLELITA 339
Cdd:COG4942 16 AAQADAAAEAEAELEQLQQEIAELEKELAALKKEEKALLKQLAALERRIAALARRIRALEQELAALEAELAELEKEIAEL 95
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 340 EAEGNRLKEKVDSLNREVEQH---------LNAERSYKSQ-----ISTLHKSVVKMEEELQKVQFEKVSALADLSSTREl 405
Cdd:COG4942 96 RAELEAQKEELAELLRALYRLgrqpplallLSPEDFLDAVrrlqyLKYLAPARREQAEELRADLAELAALRAELEAERA- 174
|
170 180 190 200 210
....*....|....*....|....*....|....*....|....*....|....*..
gi 1150561150 406 ciKLDSSKELLNRQLVAKDQEIEMRENELDSAHSEIELLRSQMANERISMQNLEALL 462
Cdd:COG4942 175 --ELEALLAELEEERAALEALKAERQKLLARLEKELAELAAELAELQQEAEELEALI 229
|
|
| SMC_N |
pfam02463 |
RecF/RecN/SMC N terminal domain; This domain is found at the N terminus of SMC proteins. The ... |
112-455 |
7.09e-04 |
|
RecF/RecN/SMC N terminal domain; This domain is found at the N terminus of SMC proteins. The SMC (structural maintenance of chromosomes) superfamily proteins have ATP-binding domains at the N- and C-termini, and two extended coiled-coil domains separated by a hinge in the middle. The eukaryotic SMC proteins form two kind of heterodimers: the SMC1/SMC3 and the SMC2/SMC4 types. These heterodimers constitute an essential part of higher order complexes, which are involved in chromatin and DNA dynamics. This family also includes the RecF and RecN proteins that are involved in DNA metabolism and recombination.
Pssm-ID: 426784 [Multi-domain] Cd Length: 1161 Bit Score: 42.65 E-value: 7.09e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 112 LRRMTTERDSLRERLKIAQETAFNEKAHLEQRIEELECTVHNLDDERMEQ-MSNMTLMKETISTVEKEMKSLARKAMDTE 190
Cdd:pfam02463 175 LKKLIEETENLAELIIDLEELKLQELKLKEQAKKALEYYQLKEKLELEEEyLLYLDYLKLNEERIDLLQELLRDEQEEIE 254
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 191 SELGRQKAENNSLRQCTEALIVCEQDVSRMRRQLDETNDELAQIARERDILAHDNDNLQEQFAKAKQENQALSKKLNDth 270
Cdd:pfam02463 255 SSKQEIEKEEEKLAQVLKENKEEEKEKKLQEEELKLLAKEEEELKSELLKLERRKVDDEEKLKESEKEKKKAEKELKK-- 332
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 271 nelndiKQKVQDTNLEVNKLKNILKSEESENRQMMEQLRKANEDAENWENKARQSEADNNTLKLELITAEAEGNRLKEKV 350
Cdd:pfam02463 333 ------EKEEIEELEKELKELEIKREAEEEEEEELEKLQEKLEQLEEELLAKKKLESERLSSAAKLKEEELELKSEEEKE 406
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 351 DSLNREVEQHLNAERSYKSQISTLHKSVVKMEEELQKVQFEKVSALADLSSTRELCIKLDSSKELLNRQLVAKDQEIEMR 430
Cdd:pfam02463 407 AQLLLELARQLEDLLKEEKKEELEILEEEEESIELKQGKLTEEKEELEKQELKLLKDELELKKSEDLLKETQLVKLQEQL 486
|
330 340
....*....|....*....|....*
gi 1150561150 431 ENELDSAHSEIELLRSQMANERISM 455
Cdd:pfam02463 487 ELLLSRQKLEERSQKESKARSGLKV 511
|
|
| Mplasa_alph_rch |
TIGR04523 |
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of ... |
134-455 |
7.77e-04 |
|
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of Mycoplasma species. Members average 750 amino acids in length, including signal peptide. Sequences are predicted (Jpred 3) to be almost entirely alpha-helical. These sequences show strong periodicity (consistent with long alpha helical structures) and low complexity rich in D,E,N,Q, and K. Genes encoding these proteins are often found in tandem. The function is unknown.
Pssm-ID: 275316 [Multi-domain] Cd Length: 745 Bit Score: 42.31 E-value: 7.77e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 134 FNEKAHLEQRIEELECTVHNLDDERMEQMSNMTLMKETISTVEKEMKSLARKAMDTESELGRQKAEN------NSLRQCT 207
Cdd:TIGR04523 241 INEKTTEISNTQTQLNQLKDEQNKIKKQLSEKQKELEQNNKKIKELEKQLNQLKSEISDLNNQKEQDwnkelkSELKNQE 320
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 208 EALIVCEQDVSRMRRQLDETNDELAQIARERDILAHDNDNLQEQFAKAKQENQALSKklndthnELNDIKQKVQDTNLEV 287
Cdd:TIGR04523 321 KKLEEIQNQISQNNKIISQLNEQISQLKKELTNSESENSEKQRELEEKQNEIEKLKK-------ENQSYKQEIKNLESQI 393
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 288 NKLKNILKSEESENRQMMEQLRKANEDAEnwenkarQSEADNNTLKLELITAEAEGNRLKEKVDSLNREVEQHLNAERSY 367
Cdd:TIGR04523 394 NDLESKIQNQEKLNQQKDEQIKKLQQEKE-------LLEKEIERLKETIIKNNSEIKDLTNQDSVKELIIKNLDNTRESL 466
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 368 KSQISTLHKSVVKMEEELQKVQFEKVSALADLSSTRELCIKLDSSKELLNRQLvakdQEIEMRENELDSAHSEIELLRSQ 447
Cdd:TIGR04523 467 ETQLKVLSRSINKIKQNLEQKQKELKSKEKELKKLNEEKKELEEKVKDLTKKI----SSLKEKIEKLESEKKEKESKISD 542
|
....*...
gi 1150561150 448 MANERISM 455
Cdd:TIGR04523 543 LEDELNKD 550
|
|
| COG4372 |
COG4372 |
Uncharacterized protein, contains DUF3084 domain [Function unknown]; |
191-540 |
1.08e-03 |
|
Uncharacterized protein, contains DUF3084 domain [Function unknown];
Pssm-ID: 443500 [Multi-domain] Cd Length: 370 Bit Score: 41.81 E-value: 1.08e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 191 SELGRQKAENNSLRQCTEALIvceqdvSRMRRQLDETNDELAQIARERDILAHDNDNLQEQFAKAKQENQALSKKLNDTH 270
Cdd:COG4372 6 EKVGKARLSLFGLRPKTGILI------AALSEQLRKALFELDKLQEELEQLREELEQAREELEQLEEELEQARSELEQLE 79
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 271 NELNDIKQKVQDTNLEVNKLKNILKSEESENRQMMEQLRKANEDAENWENKARQSEADNNTLKLELITAEAEGNRLKEKV 350
Cdd:COG4372 80 EELEELNEQLQAAQAELAQAQEELESLQEEAEELQEELEELQKERQDLEQQRKQLEAQIAELQSEIAEREEELKELEEQL 159
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 351 DSLNREVEQHLNAERSYKSQisTLHKSVVKMEEELQKVQFEKVSALADLSSTRELCIKLDSSKELLNRQLVAKDQEIEMR 430
Cdd:COG4372 160 ESLQEELAALEQELQALSEA--EAEQALDELLKEANRNAEKEEELAEAEKLIESLPRELAEELLEAKDSLEAKLGLALSA 237
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 431 ENELDSAHSEIELLRSQMANERISMQNLEALLVANRDKEYQSQIALQEKESEIQLLKEHLCLAENKMAIQSRDVAQFRNV 510
Cdd:COG4372 238 LLDALELEEDKEELLEEVILKEIEELELAILVEKDTEEEELEIAALELEALEEAALELKLLALLLNLAALSLIGALEDAL 317
|
330 340 350
....*....|....*....|....*....|
gi 1150561150 511 VTQLEADLDITKRQLGTERFERERAVQELR 540
Cdd:COG4372 318 LAALLELAKKLELALAILLAELADLLQLLL 347
|
|
| MAD |
pfam05557 |
Mitotic checkpoint protein; This family consists of several eukaryotic mitotic checkpoint ... |
112-459 |
1.10e-03 |
|
Mitotic checkpoint protein; This family consists of several eukaryotic mitotic checkpoint (Mitotic arrest deficient or MAD) proteins. The mitotic spindle checkpoint monitors proper attachment of the bipolar spindle to the kinetochores of aligned sister chromatids and causes a cell cycle arrest in prometaphase when failures occur. Multiple components of the mitotic spindle checkpoint have been identified in yeast and higher eukaryotes. In S.cerevisiae, the existence of a Mad1-dependent complex containing Mad2, Mad3, Bub3 and Cdc20 has been demonstrated.
Pssm-ID: 461677 [Multi-domain] Cd Length: 660 Bit Score: 42.04 E-value: 1.10e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 112 LRRMTTERDSLRERLKIAQETAFNekahLEQRIEELECTVHNLDD--ERMEQMSNMTLMKETISTVEKEMKSLARKAMDT 189
Cdd:pfam05557 127 LQSTNSELEELQERLDLLKAKASE----AEQLRQNLEKQQSSLAEaeQRIKELEFEIQSQEQDSEIVKNSKSELARIPEL 202
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 190 ESELGRQKAENNSLRQCTEALIVCEQDVSRMRRQLDETNDELAQIARerdiLAHDNDNLQEQFAKAKQENQALSKKLN-- 267
Cdd:pfam05557 203 EKELERLREHNKHLNENIENKLLLKEEVEDLKRKLEREEKYREEAAT----LELEKEKLEQELQSWVKLAQDTGLNLRsp 278
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 268 -DTHNELNDIKQKVQDTNLEVNKLKNILKSEESENRQMMEQLRKANEDAENWENKARQSEADNNTLKLELITAEAEGNRL 346
Cdd:pfam05557 279 eDLSRRIEQLQQREIVLKEENSSLTSSARQLEKARRELEQELAQYLKKIEDLNKKLKRHKALVRRLQRRVLLLTKERDGY 358
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 347 KEKVDSLNREVEQHlNAERSYKSQISTLHKSVVKMEEELQKVQFEKVSALADLSSTRELCIKLDSSKELLNRQLVAKDQE 426
Cdd:pfam05557 359 RAILESYDKELTMS-NYSPQLLERIEEAEDMTQKMQAHNEEMEAQLSVAEEELGGYKQQAQTLERELQALRQQESLADPS 437
|
330 340 350
....*....|....*....|....*....|...
gi 1150561150 427 IEmrENELDSAHSEIELLRSQmaNERISMQNLE 459
Cdd:pfam05557 438 YS--KEEVDSLRRKLETLELE--RQRLREQKNE 466
|
|
| PRK03918 |
PRK03918 |
DNA double-strand break repair ATPase Rad50; |
23-462 |
1.10e-03 |
|
DNA double-strand break repair ATPase Rad50;
Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 41.97 E-value: 1.10e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 23 VELLKTTTRDREELKCMLEKYERHLAEIQGNVKVLKSERDKIFLLYEQAQEEITRLRREMMKSCKSPKSTTAHAILRRVE 102
Cdd:PRK03918 223 LEKLEKEVKELEELKEEIEELEKELESLEGSKRKLEEKIRELEERIEELKKEIEELEEKVKELKELKEKAEEYIKLSEFY 302
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 103 TERDVAFTD----LRRMTTERDSLRERLKIAQETA------FNEKAHLEQRIEELEcTVHNLDDERMEQMSNMTLMK--- 169
Cdd:PRK03918 303 EEYLDELREiekrLSRLEEEINGIEERIKELEEKEerleelKKKLKELEKRLEELE-ERHELYEEAKAKKEELERLKkrl 381
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 170 --ETISTVEKEMKSLARKAMDTESELGRQKAENNSLRQctealivceqdvsrMRRQLDETNDELAQIARE-----RDILA 242
Cdd:PRK03918 382 tgLTPEKLEKELEELEKAKEEIEEEISKITARIGELKK--------------EIKELKKAIEELKKAKGKcpvcgRELTE 447
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 243 HDNDNLQEQFakakqenqalSKKLNDTHNELNDIKQKVQDTNLEVNKLKNILKSEE--SENRQMMEQLRKANE-----DA 315
Cdd:PRK03918 448 EHRKELLEEY----------TAELKRIEKELKEIEEKERKLRKELRELEKVLKKESelIKLKELAEQLKELEEklkkyNL 517
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 316 ENWENKARQSEadnnTLKLELITAEAEGNRLKEKVDSLNreveqhlnaerSYKSQISTLHKSVVKMEEELQKVqfEKVSA 395
Cdd:PRK03918 518 EELEKKAEEYE----KLKEKLIKLKGEIKSLKKELEKLE-----------ELKKKLAELEKKLDELEEELAEL--LKELE 580
|
410 420 430 440 450 460
....*....|....*....|....*....|....*....|....*....|....*....|....*....
gi 1150561150 396 LADLSSTRELCIKLDSSKELLNRQLVAKD--QEIEMRENELDSAHSEIELLRSQMANERISMQNLEALL 462
Cdd:PRK03918 581 ELGFESVEELEERLKELEPFYNEYLELKDaeKELEREEKELKKLEEELDKAFEELAETEKRLEELRKEL 649
|
|
| COG4913 |
COG4913 |
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; |
222-450 |
1.17e-03 |
|
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown];
Pssm-ID: 443941 [Multi-domain] Cd Length: 1089 Bit Score: 41.82 E-value: 1.17e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 222 RQLDETNDELAQIARERDILAHDNDnLQEQFAKAKQEnqalskklndtHNELNDIKQKVQdtnLEVNKLKNILKSEESEN 301
Cdd:COG4913 235 DDLERAHEALEDAREQIELLEPIRE-LAERYAAARER-----------LAELEYLRAALR---LWFAQRRLELLEAELEE 299
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 302 RQmmEQLRKANEDAEnwENKARQSEADNNTLKLELITAEAEGNR---LKEKVDSLNREVEQHLNAERSYKSQISTLHKSV 378
Cdd:COG4913 300 LR--AELARLEAELE--RLEARLDALREELDELEAQIRGNGGDRleqLEREIERLERELEERERRRARLEALLAALGLPL 375
|
170 180 190 200 210 220 230
....*....|....*....|....*....|....*....|....*....|....*....|....*....|..
gi 1150561150 379 VKMEEELQKVQFEKVSALADLSSTRElcikldsskELLNRQLVAKDQEIEMREnELDSAHSEIELLRSQMAN 450
Cdd:COG4913 376 PASAEEFAALRAEAAALLEALEEELE---------ALEEALAEAEAALRDLRR-ELRELEAEIASLERRKSN 437
|
|
| DUF3584 |
pfam12128 |
Protein of unknown function (DUF3584); This protein is found in bacteria and eukaryotes. ... |
57-361 |
1.35e-03 |
|
Protein of unknown function (DUF3584); This protein is found in bacteria and eukaryotes. Proteins in this family are typically between 943 to 1234 amino acids in length. This family contains a P-loop motif suggesting it is a nucleotide binding protein. It may be involved in replication.
Pssm-ID: 432349 [Multi-domain] Cd Length: 1191 Bit Score: 41.75 E-value: 1.35e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 57 LKSERDKIFLLYEQAQEEITRLRREMmkSCKSPKSTTAHAILRRVETERDVAFTDLRRMTTERDSLRERLKIAQETafnE 136
Cdd:pfam12128 602 LRERLDKAEEALQSAREKQAAAEEQL--VQANGELEKASREETFARTALKNARLDLRRLFDEKQSEKDKKNKALAE---R 676
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 137 KAHLEQRIEELECTVHNLDDE--------RMEQMSNMTLMKETISTVEKEMKslARKAMDTESELGRQKAENNSLRQCTE 208
Cdd:pfam12128 677 KDSANERLNSLEAQLKQLDKKhqawleeqKEQKREARTEKQAYWQVVEGALD--AQLALLKAAIAARRSGAKAELKALET 754
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 209 -------ALIVCEQDVSRMRRQLDETNDELAQIARERDILAHDNDNLQEQFAkakQENQALSKKLNDTHNELNDIKQ--- 278
Cdd:pfam12128 755 wykrdlaSLGVDPDVIAKLKREIRTLERKIERIAVRRQEVLRYFDWYQETWL---QRRPRLATQLSNIERAISELQQqla 831
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 279 -KVQDTNLEVNKLKNILKSEESENRQMMEQLRKAneDAENWENKARQSEADNNTLKLELITAEAEGNRLKEKVDSLNREV 357
Cdd:pfam12128 832 rLIADTKLRRAKLEMERKASEKQQVRLSENLRGL--RCEMSKLATLKEDANSEQAQGSIGERLAQLEDLKLKRDYLSESV 909
|
....
gi 1150561150 358 EQHL 361
Cdd:pfam12128 910 KKYV 913
|
|
| EnvC |
COG4942 |
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
135-342 |
1.49e-03 |
|
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 41.29 E-value: 1.49e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 135 NEKAHLEQRIEELECTVHNLDDERMEQMSNMTLMKETISTVEKEMKSLARKAMDTESELGRQKAENNSLRQCTEALivcE 214
Cdd:COG4942 20 DAAAEAEAELEQLQQEIAELEKELAALKKEEKALLKQLAALERRIAALARRIRALEQELAALEAELAELEKEIAEL---R 96
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 215 QDVSRMRRQLDE------------------TNDELAQIARERDILAHDNDNLQEQFAKAKQENQALSKKLNDTHNELNDI 276
Cdd:COG4942 97 AELEAQKEELAEllralyrlgrqpplalllSPEDFLDAVRRLQYLKYLAPARREQAEELRADLAELAALRAELEAERAEL 176
|
170 180 190 200 210 220
....*....|....*....|....*....|....*....|....*....|....*....|....*.
gi 1150561150 277 KQKVQdtnlEVNKLKNILKSEESENRQMMEQLRKANEDAENWENKARQSEADNNTLKLELITAEAE 342
Cdd:COG4942 177 EALLA----ELEEERAALEALKAERQKLLARLEKELAELAAELAELQQEAEELEALIARLEAEAAA 238
|
|
| EnvC |
COG4942 |
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
368-542 |
2.24e-03 |
|
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 40.52 E-value: 2.24e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 368 KSQISTLHKSVVKMEEELQKVQFEKVSALADLSSTRELCIKLDSSKELLNRQLVAKDQEIEMRENELDSAHSEIELLRSQ 447
Cdd:COG4942 26 EAELEQLQQEIAELEKELAALKKEEKALLKQLAALERRIAALARRIRALEQELAALEAELAELEKEIAELRAELEAQKEE 105
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 448 MAN-----ERISMQNLEALLV-------ANRDKEYQSQIALQEKESEIQLLKEHLCLAENKMAIQSRdvaqfRNVVTQLE 515
Cdd:COG4942 106 LAEllralYRLGRQPPLALLLspedfldAVRRLQYLKYLAPARREQAEELRADLAELAALRAELEAE-----RAELEALL 180
|
170 180
....*....|....*....|....*..
gi 1150561150 516 ADLDITKRQLGTERFERERAVQELRRQ 542
Cdd:COG4942 181 AELEEERAALEALKAERQKLLARLEKE 207
|
|
| Surf_Exclu_PgrA |
TIGR04320 |
SEC10/PgrA surface exclusion domain; This model describes a conserved domain found in surface ... |
244-317 |
2.55e-03 |
|
SEC10/PgrA surface exclusion domain; This model describes a conserved domain found in surface proteins of a number of Firmutes. Many members have LPXTG C-terminal anchoring motifs and a substantial number have the KxYKxGKxW putative sorting signal at the N-terminus. The tetracycline resistance plasmid pCF10 in Enterococcus faecalis promotes conjugal plasmid transfer in response to sex pheromones, but PgrA/Sec10 encoded by that plasmid, a member of this family, specifically inhibits the ability of cells to receive homologous plasmids. The phenomenon is called surface exclusion.
Pssm-ID: 275124 [Multi-domain] Cd Length: 356 Bit Score: 40.48 E-value: 2.55e-03
10 20 30 40 50 60 70
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*
gi 1150561150 244 DNDNLQEQFAKAKQENQALSKKLNDTHNELNDIK-QKVQDTNLEVNKLKNILKSEESENRQMMEQLRKANEDAEN 317
Cdd:TIGR04320 276 ALNTAQAALTSAQTAYAAAQAALATAQKELANAQaQALQTAQNNLATAQAALANAEARLAKAKEALANLNADLAK 350
|
|
| PRK01156 |
PRK01156 |
chromosome segregation protein; Provisional |
135-404 |
2.67e-03 |
|
chromosome segregation protein; Provisional
Pssm-ID: 100796 [Multi-domain] Cd Length: 895 Bit Score: 40.66 E-value: 2.67e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 135 NEKAHLEQRIEELECTVHNLDDERMEQMSNMT-LMKETISTVEKE---MKSLARKAMDTESELGRQKAENNSLRQCTEAl 210
Cdd:PRK01156 476 EKKSRLEEKIREIEIEVKDIDEKIVDLKKRKEyLESEEINKSINEynkIESARADLEDIKIKINELKDKHDKYEEIKNR- 554
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 211 iVCEQDVSRMRRQLDETNDELAQIArerdilAHDNDNLQEQFAKAKQENQALSKKLNDTHNELNDIK----QKVQDTNLE 286
Cdd:PRK01156 555 -YKSLKLEDLDSKRTSWLNALAVIS------LIDIETNRSRSNEIKKQLNDLESRLQEIEIGFPDDKsyidKSIREIENE 627
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 287 VNKLKNiLKSEESENRQMMEQLRKANEDAENWENKARQSEADNNTLKLELITAEAEGNRLKEKVDSLNREVEQHLNAERS 366
Cdd:PRK01156 628 ANNLNN-KYNEIQENKILIEKLRGKIDNYKKQIAEIDSIIPDLKEITSRINDIEDNLKKSRKALDDAKANRARLESTIEI 706
|
250 260 270
....*....|....*....|....*....|....*...
gi 1150561150 367 YKSQISTLHKSVVKMEEELQKVQfEKVSALADLSSTRE 404
Cdd:PRK01156 707 LRTRINELSDRINDINETLESMK-KIKKAIGDLKRLRE 743
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
33-293 |
2.75e-03 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 40.81 E-value: 2.75e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 33 REELKCMLEKYERHLAEIQGNVKVLKSErdkifllYEQAQEEITRLRREmmksckspkSTTAHAILRRVETERDVAFTDL 112
Cdd:TIGR02168 763 IEELEERLEEAEEELAEAEAEIEELEAQ-------IEQLKEELKALREA---------LDELRAELTLLNEEAANLRERL 826
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 113 RRMTTERDSLRERLKiaqetafnekaHLEQRIEELECTVHNLDDERMEQMSNMTLMKETISTVEKEMKSLARKAMDTESE 192
Cdd:TIGR02168 827 ESLERRIAATERRLE-----------DLEEQIEELSEDIESLAAEIEELEELIEELESELEALLNERASLEEALALLRSE 895
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 193 LGRQKAENNSLrqctealivcEQDVSRMRRQLDETNDELAQIARERDILAHDNDNLQEQFA-KAKQENQALSKKLNDTHN 271
Cdd:TIGR02168 896 LEELSEELREL----------ESKRSELRRELEELREKLAQLELRLEGLEVRIDNLQERLSeEYSLTLEEAEALENKIED 965
|
250 260
....*....|....*....|..
gi 1150561150 272 ELNDIKQKVQDTNLEVNKLKNI 293
Cdd:TIGR02168 966 DEEEARRRLKRLENKIKELGPV 987
|
|
| PRK01156 |
PRK01156 |
chromosome segregation protein; Provisional |
223-483 |
3.37e-03 |
|
chromosome segregation protein; Provisional
Pssm-ID: 100796 [Multi-domain] Cd Length: 895 Bit Score: 40.66 E-value: 3.37e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 223 QLDETNDELAQIARERDILAHDNDNLQEQFAKAKQENQALSKKLNDTHNELNDIKQKVQDTNLEVNKLKNILKSEESENR 302
Cdd:PRK01156 163 SLERNYDKLKDVIDMLRAEISNIDYLEEKLKSSNLELENIKKQIADDEKSHSITLKEIERLSIEYNNAMDDYNNLKSALN 242
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 303 QMMEQLRKANEdaenWENKARQSEADNNTLKLELITAEAEGNRLKEKVDSLNREVEQHLNAERSYKSQISTLHKSVVKME 382
Cdd:PRK01156 243 ELSSLEDMKNR----YESEIKTAESDLSMELEKNNYYKELEERHMKIINDPVYKNRNYINDYFKYKNDIENKKQILSNID 318
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 383 EELQKVQfEKVSALADLSSTRELCIKLDSSKELLNRQLvakdQEIEMRENELDSAHSEIELLRSQMANERISMQNLEALL 462
Cdd:PRK01156 319 AEINKYH-AIIKKLSVLQKDYNDYIKKKSRYDDLNNQI----LELEGYEMDYNSYLKSIESLKKKIEEYSKNIERMSAFI 393
|
250 260
....*....|....*....|.
gi 1150561150 463 VANRDKEYQSQIALQEKESEI 483
Cdd:PRK01156 394 SEILKIQEIDPDAIKKELNEI 414
|
|
| SCP-1 |
pfam05483 |
Synaptonemal complex protein 1 (SCP-1); Synaptonemal complex protein 1 (SCP-1) is the major ... |
140-540 |
4.40e-03 |
|
Synaptonemal complex protein 1 (SCP-1); Synaptonemal complex protein 1 (SCP-1) is the major component of the transverse filaments of the synaptonemal complex. Synaptonemal complexes are structures that are formed between homologous chromosomes during meiotic prophase.
Pssm-ID: 114219 [Multi-domain] Cd Length: 787 Bit Score: 40.09 E-value: 4.40e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 140 LEQRIEELE--CTVHNLDDERMEQMSNMTLMKETISTVEKEMKSLARKAMDTESEL-GRQKAENNSLRQCTEALIVCEQD 216
Cdd:pfam05483 386 LQKKSSELEemTKFKNNKEVELEELKKILAEDEKLLDEKKQFEKIAEELKGKEQELiFLLQAREKEIHDLEIQLTAIKTS 465
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 217 VSRMRRQLDETNDELAQIARERDILAHDNDNLQEQFAKAKQENQALSKKLNDTHNELNDIKQKVQDTNLEVNKLK----N 292
Cdd:pfam05483 466 EEHYLKEVEDLKTELEKEKLKNIELTAHCDKLLLENKELTQEASDMTLELKKHQEDIINCKKQEERMLKQIENLEekemN 545
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 293 ILKSEESENRQMMEQLRKANEDAENWENKARQSEADNNTLKLELITAEAEGNRLKEKVDSLNREVEQHLNAERSYKSQIS 372
Cdd:pfam05483 546 LRDELESVREEFIQKGDEVKCKLDKSEENARSIEYEVLKKEKQMKILENKCNNLKKQIENKNKNIEELHQENKALKKKGS 625
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 373 TLHKSVVKMEEELQKVQFEKVSALADLSSTRELCIKLDSSKELLNRQLVAKDQEIEMRENELDSAHSEIELLRSQMANER 452
Cdd:pfam05483 626 AENKQLNAYEIKVNKLELELASAKQKFEEIIDNYQKEIEDKKISEEKLLEEVEKAKAIADEAVKLQKEIDKRCQHKIAEM 705
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 453 ISMQnleallvanRDKEYQSQIALQEKESEIQLLKehlclaeNKMAIQSRDVAQFRNVVTQLEADLDITKRQLGTERFER 532
Cdd:pfam05483 706 VALM---------EKHKHQYDKIIEERDSELGLYK-------NKEQEQSSAKAALEIELSNIKAELLSLKKQLEIEKEEK 769
|
....*...
gi 1150561150 533 ERAVQELR 540
Cdd:pfam05483 770 EKLKMEAK 777
|
|
| GumC |
COG3206 |
Exopolysaccharide export protein/domain GumC/Wzc1 [Cell wall/membrane/envelope biogenesis]; |
169-362 |
5.67e-03 |
|
Exopolysaccharide export protein/domain GumC/Wzc1 [Cell wall/membrane/envelope biogenesis];
Pssm-ID: 442439 [Multi-domain] Cd Length: 687 Bit Score: 39.61 E-value: 5.67e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 169 KETISTVEKEMKSLARKAMDTESELGRQKAENNSLRQCTEALIVcEQDVSRMRRQLDETNDELAQIARERDILAHDNDNL 248
Cdd:COG3206 174 RKALEFLEEQLPELRKELEEAEAALEEFRQKNGLVDLSEEAKLL-LQQLSELESQLAEARAELAEAEARLAALRAQLGSG 252
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 249 QEQFAKAKQ--ENQALSKKLNDTHNELNDIKQKVQDTNLEV----NKLKNILKSEESENRQMMEQLRKANEDAENWENKA 322
Cdd:COG3206 253 PDALPELLQspVIQQLRAQLAELEAELAELSARYTPNHPDVialrAQIAALRAQLQQEAQRILASLEAELEALQAREASL 332
|
170 180 190 200
....*....|....*....|....*....|....*....|
gi 1150561150 323 RQSEADNNTLKLELITAEAEGNRLKEKVDSLNREVEQHLN 362
Cdd:COG3206 333 QAQLAQLEARLAELPELEAELRRLEREVEVARELYESLLQ 372
|
|
| PspC_subgroup_1 |
NF033838 |
pneumococcal surface protein PspC, choline-binding form; The pneumococcal surface protein PspC, ... |
33-384 |
5.82e-03 |
|
pneumococcal surface protein PspC, choline-binding form; The pneumococcal surface protein PspC, as described in Streptococcus pneumoniae, is a repetitive and highly variable protein, recognized by a conserved N-terminal domain and also by genomic location. This form, subgroup 1, has variable numbers of a choline-binding repeat in the C-terminal region, and is also known as choline-binding protein A. The other form, subgroup 2, is anchored covalently after cleavage by sortase at a C-terminal LPXTG site.
Pssm-ID: 468201 [Multi-domain] Cd Length: 684 Bit Score: 39.61 E-value: 5.82e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 33 REELKCMLEKYERHLAEIQGNVKVLKSERDKIFLLyeqaqeEITRLRREMMKSCKSPKSTTAHAILRRVETERDVAFTDL 112
Cdd:NF033838 57 KEHAKEVESHLEKILSEIQKSLDKRKHTQNVALNK------KLSDIKTEYLYELNVLKEKSEAELTSKTKKELDAAFEQF 130
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 113 RRMTTERDS----LRERLKIAQETAFNEKAH------------LEQRIEELECTVHNLDDERMEQMSNMTLMKETISTVE 176
Cdd:NF033838 131 KKDTLEPGKkvaeATKKVEEAEKKAKDQKEEdrrnyptntyktLELEIAESDVEVKKAELELVKEEAKEPRDEEKIKQAK 210
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 177 KEMKSLARKAMDTES-ELGRQKAENNSLRQCTEALIVCEQDVSRMRRQldetnDELAQIARERDilahdndnLQEQFAKA 255
Cdd:NF033838 211 AKVESKKAEATRLEKiKTDREKAEEEAKRRADAKLKEAVEKNVATSEQ-----DKPKRRAKRGV--------LGEPATPD 277
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 1150561150 256 KQENQALSKKLNDTHNELNDI----KQKVQDTNLEVNKLKNILKSEESENRQMMEQLRKANEDAENWENKARQSEAdnnt 331
Cdd:NF033838 278 KKENDAKSSDSSVGEETLPSPslkpEKKVAEAEKKVEEAKKKAKDQKEEDRRNYPTNTYKTLELEIAESDVKVKEA---- 353
|
330 340 350 360 370
....*....|....*....|....*....|....*....|....*....|...
gi 1150561150 332 lKLELITAEAEGNRLKEKVDSLNREVEQHLnAERSYKSQISTLHKsvvKMEEE 384
Cdd:NF033838 354 -ELELVKEEAKEPRNEEKIKQAKAKVESKK-AEATRLEKIKTDRK---KAEEE 401
|
|
| |