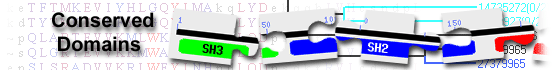Myosin phosphatase-RhoA Interacting Protein Pleckstrin homology (PH) domain; M-RIP is proposed ...
429-530
5.44e-47
Myosin phosphatase-RhoA Interacting Protein Pleckstrin homology (PH) domain; M-RIP is proposed to play a role in myosin phosphatase regulation by RhoA. M-RIP contains 2 PH domains followed by a Rho binding domain (Rho-BD), and a C-terminal myosin binding subunit (MBS) binding domain (MBS-BD). The amino terminus of M-RIP with its adjacent PH domains and polyproline motifs mediates binding to both actin and Galpha. M-RIP brings RhoA and MBS into close proximity where M-RIP can target RhoA to the myosin phosphatase complex to regulate the myosin phosphorylation state. M-RIP does this via its C-terminal coiled-coil domain which interacts with the MBS leucine zipper domain of myosin phosphatase, while its Rho-BD, directly binds RhoA in a nucleotide-independent manner. PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
:
Pssm-ID: 270094 Cd Length: 104 Bit Score: 164.04 E-value: 5.44e-47
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ...
1680-2282
2.46e-06
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
The actual alignment was detected with superfamily member TIGR02168:
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 53.14 E-value: 2.46e-06
Myosin phosphatase-RhoA Interacting Protein Pleckstrin homology (PH) domain; M-RIP is proposed ...
429-530
5.44e-47
Myosin phosphatase-RhoA Interacting Protein Pleckstrin homology (PH) domain; M-RIP is proposed to play a role in myosin phosphatase regulation by RhoA. M-RIP contains 2 PH domains followed by a Rho binding domain (Rho-BD), and a C-terminal myosin binding subunit (MBS) binding domain (MBS-BD). The amino terminus of M-RIP with its adjacent PH domains and polyproline motifs mediates binding to both actin and Galpha. M-RIP brings RhoA and MBS into close proximity where M-RIP can target RhoA to the myosin phosphatase complex to regulate the myosin phosphorylation state. M-RIP does this via its C-terminal coiled-coil domain which interacts with the MBS leucine zipper domain of myosin phosphatase, while its Rho-BD, directly binds RhoA in a nucleotide-independent manner. PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 270094 Cd Length: 104 Bit Score: 164.04 E-value: 5.44e-47
Pleckstrin homology domain; Domain commonly found in eukaryotic signalling proteins. The ...
429-521
3.73e-16
Pleckstrin homology domain; Domain commonly found in eukaryotic signalling proteins. The domain family possesses multiple functions including the abilities to bind inositol phosphates, and various proteins. PH domains have been found to possess inserted domains (such as in PLC gamma, syntrophins) and to be inserted within other domains. Mutations in Brutons tyrosine kinase (Btk) within its PH domain cause X-linked agammaglobulinaemia (XLA) in patients. Point mutations cluster into the positively charged end of the molecule around the predicted binding site for phosphatidylinositol lipids.
Pssm-ID: 214574 [Multi-domain] Cd Length: 102 Bit Score: 76.05 E-value: 3.73e-16
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ...
706-987
6.42e-11
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 68.16 E-value: 6.42e-11
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and ...
666-1161
5.50e-08
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and four light chains it is a fundamental contractile protein found in all eukaryote cell types. This family consists of the coiled-coil myosin heavy chain tail region. The coiled-coil is composed of the tail from two molecules of myosin. These can then assemble into the macromolecular thick filament. The coiled-coil region provides the structural backbone the thick filament.
Pssm-ID: 460256 [Multi-domain] Cd Length: 1081 Bit Score: 58.65 E-value: 5.50e-08
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ...
1986-2178
7.30e-08
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 58.14 E-value: 7.30e-08
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ...
1680-2282
2.46e-06
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 53.14 E-value: 2.46e-06
DNA Topoisomerase I (eukaryota); DNA Topoisomerase I (eukaryota), DNA topoisomerase V, Vaccina ...
1971-2067
7.56e-03
DNA Topoisomerase I (eukaryota); DNA Topoisomerase I (eukaryota), DNA topoisomerase V, Vaccina virus topoisomerase, Variola virus topoisomerase, Shope fibroma virus topoisomeras
Pssm-ID: 214661 [Multi-domain] Cd Length: 391 Bit Score: 41.18 E-value: 7.56e-03
Myosin phosphatase-RhoA Interacting Protein Pleckstrin homology (PH) domain; M-RIP is proposed ...
429-530
5.44e-47
Myosin phosphatase-RhoA Interacting Protein Pleckstrin homology (PH) domain; M-RIP is proposed to play a role in myosin phosphatase regulation by RhoA. M-RIP contains 2 PH domains followed by a Rho binding domain (Rho-BD), and a C-terminal myosin binding subunit (MBS) binding domain (MBS-BD). The amino terminus of M-RIP with its adjacent PH domains and polyproline motifs mediates binding to both actin and Galpha. M-RIP brings RhoA and MBS into close proximity where M-RIP can target RhoA to the myosin phosphatase complex to regulate the myosin phosphorylation state. M-RIP does this via its C-terminal coiled-coil domain which interacts with the MBS leucine zipper domain of myosin phosphatase, while its Rho-BD, directly binds RhoA in a nucleotide-independent manner. PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 270094 Cd Length: 104 Bit Score: 164.04 E-value: 5.44e-47
Pleckstrin homology domain; Domain commonly found in eukaryotic signalling proteins. The ...
429-521
3.73e-16
Pleckstrin homology domain; Domain commonly found in eukaryotic signalling proteins. The domain family possesses multiple functions including the abilities to bind inositol phosphates, and various proteins. PH domains have been found to possess inserted domains (such as in PLC gamma, syntrophins) and to be inserted within other domains. Mutations in Brutons tyrosine kinase (Btk) within its PH domain cause X-linked agammaglobulinaemia (XLA) in patients. Point mutations cluster into the positively charged end of the molecule around the predicted binding site for phosphatidylinositol lipids.
Pssm-ID: 214574 [Multi-domain] Cd Length: 102 Bit Score: 76.05 E-value: 3.73e-16
Pleckstrin homology (PH) domain; PH domains have diverse functions, but in general are ...
429-517
2.63e-12
Pleckstrin homology (PH) domain; PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 275388 [Multi-domain] Cd Length: 92 Bit Score: 64.87 E-value: 2.63e-12
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ...
706-987
6.42e-11
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 68.16 E-value: 6.42e-11
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ...
772-1167
3.88e-10
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 65.46 E-value: 3.88e-10
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ...
837-1135
1.43e-09
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 63.92 E-value: 1.43e-09
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ...
817-1125
1.45e-09
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 63.92 E-value: 1.45e-09
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ...
772-1133
7.72e-09
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 61.24 E-value: 7.72e-09
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ...
856-1160
1.10e-08
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 60.85 E-value: 1.10e-08
Myosin X Pleckstrin homology (PH) domain, repeat 2; MyoX, a MyTH-FERM myosin, is a molecular ...
429-529
3.64e-08
Myosin X Pleckstrin homology (PH) domain, repeat 2; MyoX, a MyTH-FERM myosin, is a molecular motor that has crucial functions in the transport and/or tethering of integrins in the actin-based extensions known as filopodia, microtubule binding, and in netrin-mediated axon guidance. It functions as a dimer. MyoX walks on bundles of actin, rather than single filaments, unlike the other unconventional myosins. MyoX is present in organisms ranging from humans to choanoflagellates, but not in Drosophila and Caenorhabditis elegans.MyoX consists of a N-terminal motor/head region, a neck made of 3 IQ motifs, and a tail consisting of a coiled-coil domain, a PEST region, 3 PH domains, a myosin tail homology 4 (MyTH4), and a FERM domain at its very C-terminus. The first PH domain in the MyoX tail is a split-PH domain, interupted by the second PH domain such that PH 1a and PH 1b flanks PH 2. The third PH domain (PH 3) follows the PH 1b domain. This cd contains the second PH repeat. PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 270108 Cd Length: 103 Bit Score: 53.24 E-value: 3.64e-08
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and ...
666-1161
5.50e-08
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and four light chains it is a fundamental contractile protein found in all eukaryote cell types. This family consists of the coiled-coil myosin heavy chain tail region. The coiled-coil is composed of the tail from two molecules of myosin. These can then assemble into the macromolecular thick filament. The coiled-coil region provides the structural backbone the thick filament.
Pssm-ID: 460256 [Multi-domain] Cd Length: 1081 Bit Score: 58.65 E-value: 5.50e-08
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ...
1986-2178
7.30e-08
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 58.14 E-value: 7.30e-08
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ...
1801-2162
1.48e-07
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 57.00 E-value: 1.48e-07
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ...
1992-2286
1.64e-07
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 57.00 E-value: 1.64e-07
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ...
673-918
2.26e-07
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 56.61 E-value: 2.26e-07
Arabidopsis thaliana Pleckstrin homolog (PH) 1 (AtPH1) PH domain; AtPH1 is expressed in all ...
429-525
2.69e-07
Arabidopsis thaliana Pleckstrin homolog (PH) 1 (AtPH1) PH domain; AtPH1 is expressed in all plant tissue and is proposed to be the plant homolog of human pleckstrin. Pleckstrin consists of two PH domains separated by a linker region, while AtPH has a single PH domain with a short N-terminal extension. AtPH1 binds PtdIns3P specifically and is thought to be an adaptor molecule since it has no obvious catalytic functions. PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 270095 Cd Length: 106 Bit Score: 50.78 E-value: 2.69e-07
Autophagy-related protein 26/Sterol 3-beta-glucosyltransferase Pleckstrin homology (PH) domain, ...
428-521
2.78e-07
Autophagy-related protein 26/Sterol 3-beta-glucosyltransferase Pleckstrin homology (PH) domain, repeat 1; ATG26 (also called UGT51/UDP-glycosyltransferase 51), a member of the glycosyltransferase 28 family, resulting in the biosynthesis of sterol glucoside. ATG26 in decane metabolism and autophagy. There are 32 known autophagy-related (ATG) proteins, 17 are components of the core autophagic machinery essential for all autophagy-related pathways and 15 are the additional components required only for certain pathways or species. The core autophagic machinery includes 1) the ATG9 cycling system (ATG1, ATG2, ATG9, ATG13, ATG18, and ATG27), 2) the phosphatidylinositol 3-kinase complex (ATG6/VPS30, ATG14, VPS15, and ATG34), and 3) the ubiquitin-like protein system (ATG3, ATG4, ATG5, ATG7, ATG8, ATG10, ATG12, and ATG16). Less is known about how the core machinery is adapted or modulated with additional components to accommodate the nonselective sequestration of bulk cytosol (autophagosome formation) or selective sequestration of specific cargos (Cvt vesicle, pexophagosome, or bacteria-containing autophagosome formation). The pexophagosome-specific additions include the ATG30-ATG11-ATG17 receptor-adaptors complex, the coiled-coil protein ATG25, and the sterol glucosyltransferase ATG26. ATG26 is necessary for the degradation of medium peroxisomes. It contains 2 GRAM domains and a single PH domain. PH domains are only found in eukaryotes. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. PH domains also have diverse functions. They are often involved in targeting proteins to the plasma membrane, but few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 275402 Cd Length: 116 Bit Score: 51.08 E-value: 2.78e-07
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ...
1868-2165
3.44e-07
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 55.84 E-value: 3.44e-07
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ...
818-1158
4.47e-07
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 55.46 E-value: 4.47e-07
Connector enhancer of KSR (Kinase suppressor of ras) (CNK) pleckstrin homology (PH) domain; ...
431-475
4.96e-07
Connector enhancer of KSR (Kinase suppressor of ras) (CNK) pleckstrin homology (PH) domain; CNK family members function as protein scaffolds, regulating the activity and the subcellular localization of RAS activated RAF. There is a single CNK protein present in Drosophila and Caenorhabditis elegans in contrast to mammals which have 3 CNK proteins (CNK1, CNK2, and CNK3). All of the CNK members contain a sterile a motif (SAM), a conserved region in CNK (CRIC) domain, and a PSD-95/DLG-1/ZO-1 (PDZ) domain, and, with the exception of CNK3, a PH domain. A CNK2 splice variant CNK2A also has a PDZ domain-binding motif at its C terminus and Drosophila CNK (D-CNK) also has a domain known as the Raf-interacting region (RIR) that mediates binding of the Drosophila Raf kinase. This cd contains CNKs from mammals, chickens, amphibians, fish, and crustacea. PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 269962 Cd Length: 114 Bit Score: 50.48 E-value: 4.96e-07
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ...
1909-2235
5.08e-07
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 55.45 E-value: 5.08e-07
ArfGAP with RhoGAP domain, ankyrin repeat and PH domain Pleckstrin homology (PH) domain, ...
429-522
5.51e-07
ArfGAP with RhoGAP domain, ankyrin repeat and PH domain Pleckstrin homology (PH) domain, repeat 1; ARAP proteins (also called centaurin delta) are phosphatidylinositol 3,4,5-trisphosphate-dependent GTPase-activating proteins that modulate actin cytoskeleton remodeling by regulating ARF and RHO family members. They bind phosphatidylinositol 3,4,5-trisphosphate (PtdIns(3,4,5)P3) and phosphatidylinositol 3,4-bisphosphate (PtdIns(3,4,5)P2) binding. There are 3 mammalian ARAP proteins: ARAP1, ARAP2, and ARAP3. All ARAP proteins contain a N-terminal SAM (sterile alpha motif) domain, 5 PH domains, an ArfGAP domain, 2 ankyrin domain, A RhoGap domain, and a Ras-associating domain. This hierarchy contains the first PH domain in ARAP. PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 270073 Cd Length: 94 Bit Score: 49.69 E-value: 5.51e-07
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of ...
718-1135
7.86e-07
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of Mycoplasma species. Members average 750 amino acids in length, including signal peptide. Sequences are predicted (Jpred 3) to be almost entirely alpha-helical. These sequences show strong periodicity (consistent with long alpha helical structures) and low complexity rich in D,E,N,Q, and K. Genes encoding these proteins are often found in tandem. The function is unknown.
Pssm-ID: 275316 [Multi-domain] Cd Length: 745 Bit Score: 54.64 E-value: 7.86e-07
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of ...
797-1127
1.01e-06
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of Mycoplasma species. Members average 750 amino acids in length, including signal peptide. Sequences are predicted (Jpred 3) to be almost entirely alpha-helical. These sequences show strong periodicity (consistent with long alpha helical structures) and low complexity rich in D,E,N,Q, and K. Genes encoding these proteins are often found in tandem. The function is unknown.
Pssm-ID: 275316 [Multi-domain] Cd Length: 745 Bit Score: 54.26 E-value: 1.01e-06
Phosphoinositol 3-phosphate binding proteins 1, 2, and 3 pleckstrin homology (PH) domain; PEPP1 (also called PLEKHA4/PH domain-containing family A member 4 and RHOXF1/Rhox homeobox family member 1), and related homologs PEPP2 (also called PLEKHA5/PH domain-containing family A member 5) and PEPP3 (also called PLEKHA6/PH domain-containing family A member 6), have PH domains that interact specifically with PtdIns(3,4)P3. Other proteins that bind PtdIns(3,4)P3 specifically are: TAPP1 (tandem PH-domain-containing protein-1) and TAPP2], PtdIns3P AtPH1, and Ptd- Ins(3,5)P2 (centaurin-beta2). All of these proteins contain at least 5 of the 6 conserved amino acids that make up the putative phosphatidylinositol 3,4,5- trisphosphate-binding motif (PPBM) located at their N-terminus. PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 270068 Cd Length: 104 Bit Score: 49.19 E-value: 1.15e-06
RecF/RecN/SMC N terminal domain; This domain is found at the N terminus of SMC proteins. The ...
833-1134
1.24e-06
RecF/RecN/SMC N terminal domain; This domain is found at the N terminus of SMC proteins. The SMC (structural maintenance of chromosomes) superfamily proteins have ATP-binding domains at the N- and C-termini, and two extended coiled-coil domains separated by a hinge in the middle. The eukaryotic SMC proteins form two kind of heterodimers: the SMC1/SMC3 and the SMC2/SMC4 types. These heterodimers constitute an essential part of higher order complexes, which are involved in chromatin and DNA dynamics. This family also includes the RecF and RecN proteins that are involved in DNA metabolism and recombination.
Pssm-ID: 426784 [Multi-domain] Cd Length: 1161 Bit Score: 54.21 E-value: 1.24e-06
ArfGAP with dual PH domains Pleckstrin homology (PH) domain, repeat 2; ADAP (also called ...
427-517
2.15e-06
ArfGAP with dual PH domains Pleckstrin homology (PH) domain, repeat 2; ADAP (also called centaurin alpha) is a phophatidlyinositide binding protein consisting of an N-terminal ArfGAP domain and two PH domains. In response to growth factor activation, PI3K phosphorylates phosphatidylinositol 4,5-bisphosphate to phosphatidylinositol 3,4,5-trisphosphate. Centaurin alpha 1 is recruited to the plasma membrane following growth factor stimulation by specific binding of its PH domain to phosphatidylinositol 3,4,5-trisphosphate. Centaurin alpha 2 is constitutively bound to the plasma membrane since it binds phosphatidylinositol 4,5-bisphosphate and phosphatidylinositol 3,4,5-trisphosphate with equal affinity. This cd contains the second PH domain repeat. PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 241282 Cd Length: 105 Bit Score: 48.35 E-value: 2.15e-06
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ...
1680-2282
2.46e-06
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 53.14 E-value: 2.46e-06
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ...
703-1032
3.71e-06
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 52.38 E-value: 3.71e-06
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ...
2013-2322
6.42e-06
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 51.61 E-value: 6.42e-06
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of ...
779-1135
6.61e-06
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of Mycoplasma species. Members average 750 amino acids in length, including signal peptide. Sequences are predicted (Jpred 3) to be almost entirely alpha-helical. These sequences show strong periodicity (consistent with long alpha helical structures) and low complexity rich in D,E,N,Q, and K. Genes encoding these proteins are often found in tandem. The function is unknown.
Pssm-ID: 275316 [Multi-domain] Cd Length: 745 Bit Score: 51.56 E-value: 6.61e-06
Dual Adaptor for Phosphotyrosine and 3-Phosphoinositides Pleckstrin homology (PH) domain; ...
426-517
6.74e-06
Dual Adaptor for Phosphotyrosine and 3-Phosphoinositides Pleckstrin homology (PH) domain; DAPP1 (also known as PHISH/3' phosphoinositide-interacting SH2 domain-containing protein or Bam32) plays a role in B-cell activation and has potential roles in T-cell and mast cell function. DAPP1 promotes B cell receptor (BCR) induced activation of Rho GTPases Rac1 and Cdc42, which feed into mitogen-activated protein kinases (MAPK) activation pathways and affect cytoskeletal rearrangement. DAPP1can also regulate BCR-induced activation of extracellular signal-regulated kinase (ERK), and c-jun NH2-terminal kinase (JNK). DAPP1 contains an N-terminal SH2 domain and a C-terminal pleckstrin homology (PH) domain with a single tyrosine phosphorylation site located centrally. DAPP1 binds strongly to both PtdIns(3,4,5)P3 and PtdIns(3,4)P2. The PH domain is essential for plasma membrane recruitment of PI3K upon cell activation. PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 269977 [Multi-domain] Cd Length: 96 Bit Score: 46.55 E-value: 6.74e-06
Calcium binding and coiled-coil domain (CALCOCO1) like; Proteins found in this family are ...
717-964
7.37e-06
Calcium binding and coiled-coil domain (CALCOCO1) like; Proteins found in this family are similar to the coiled-coil transcriptional coactivator protein coexpressed by Mus musculus (CoCoA/CALCOCO1). This protein binds to a highly conserved N-terminal domain of p160 coactivators, such as GRIP1, and thus enhances transcriptional activation by a number of nuclear receptors. CALCOCO1 has a central coiled-coil region with three leucine zipper motifs, which is required for its interaction with GRIP1 and may regulate the autonomous transcriptional activation activity of the C-terminal region.
Pssm-ID: 462303 [Multi-domain] Cd Length: 488 Bit Score: 51.05 E-value: 7.37e-06
TBC1 domain family member 2A pleckstrin homology (PH) domain; TBC1D2A (also called PARIS-1 ...
442-520
7.54e-06
TBC1 domain family member 2A pleckstrin homology (PH) domain; TBC1D2A (also called PARIS-1/Prostate antigen recognized and identified by SEREX 1 and ARMUS) contains a PH domain and a TBC-type GTPase catalytic domain. TBC1D2A integrates signaling between Arf6, Rac1, and Rab7 during junction disassembly. Activated Rac1 recruits TBC1D2A to locally inactivate Rab7 via its C-terminal TBC/RabGAP domain and facilitate E-cadherin degradation in lysosomes. The TBC1D2A PH domain mediates localization at cell-cell contacts and coprecipitates with cadherin complexes. PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 269966 Cd Length: 102 Bit Score: 46.55 E-value: 7.54e-06
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of ...
778-1134
1.10e-05
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of Mycoplasma species. Members average 750 amino acids in length, including signal peptide. Sequences are predicted (Jpred 3) to be almost entirely alpha-helical. These sequences show strong periodicity (consistent with long alpha helical structures) and low complexity rich in D,E,N,Q, and K. Genes encoding these proteins are often found in tandem. The function is unknown.
Pssm-ID: 275316 [Multi-domain] Cd Length: 745 Bit Score: 50.79 E-value: 1.10e-05
Pleckstrin homology (PH) domain containing, family H (with MyTH4 domain) members 1 and 2 ...
429-517
1.45e-05
Pleckstrin homology (PH) domain containing, family H (with MyTH4 domain) members 1 and 2 (PLEKHH1) PH domain, repeat 1; PLEKHH1 and PLEKHH2 (also called PLEKHH1L) are thought to function in phospholipid binding and signal transduction. There are 3 Human PLEKHH genes: PLEKHH1, PLEKHH2, and PLEKHH3. There are many isoforms, the longest of which contain a FERM domain, a MyTH4 domain, two PH domains, a peroximal domain, a vacuolar domain, and a coiled coil stretch. The FERM domain has a cloverleaf tripart structure (FERM_N, FERM_M, FERM_C/N, alpha-, and C-lobe/A-lobe, B-lobe, C-lobe/F1, F2, F3). The C-lobe/F3 within the FERM domain is part of the PH domain family. PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 241436 Cd Length: 96 Bit Score: 45.75 E-value: 1.45e-05
Switch-associated protein-70 Pleckstrin homology (PH) domain; SWAP-70 (also called ...
429-517
2.93e-05
Switch-associated protein-70 Pleckstrin homology (PH) domain; SWAP-70 (also called Differentially expressed in FDCP 6/DEF-6 or IRF4-binding protein) functions in cellular signal transduction pathways (in conjunction with Rac), regulates cell motility through actin rearrangement, and contributes to the transformation and invasion activity of mouse embryo fibroblasts. Metazoan SWAP-70 is found in B lymphocytes, mast cells, and in a variety of organs. Metazoan SWAP-70 contains an N-terminal EF-hand motif, a centrally located PH domain, and a C-terminal coiled-coil domain. The PH domain of Metazoan SWAP-70 contains a phosphoinositide-binding site and a nuclear localization signal (NLS), which localize SWAP-70 to the plasma membrane and nucleus, respectively. The NLS is a sequence of four Lys residues located at the N-terminus of the C-terminal a-helix; this is a unique characteristic of the Metazoan SWAP-70 PH domain. The SWAP-70 PH domain binds PtdIns(3,4,5)P3 and PtdIns(4,5)P2 embedded in lipid bilayer vesicles. There are additional plant SWAP70 proteins, but these are not included in this hierarchy. Rice SWAP70 (OsSWAP70) exhibits GEF activity toward the its Rho GTPase, OsRac1, and regulates chitin-induced production of reactive oxygen species and defense gene expression in rice. Arabidopsis SWAP70 (AtSWAP70) plays a role in both PAMP- and effector-triggered immunity. Plant SWAP70 contains both DH and PH domains, but their arrangement is the reverse of that in typical DH-PH-type Rho GEFs, wherein the DH domain is flanked by a C-terminal PH domain. PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 270092 Cd Length: 110 Bit Score: 45.36 E-value: 2.93e-05
Yeast oxysterol binding protein homologs 1 and 2 Pleckstrin homology (PH) domain; Yeast Osh1p ...
430-521
3.02e-05
Yeast oxysterol binding protein homologs 1 and 2 Pleckstrin homology (PH) domain; Yeast Osh1p is proposed to function in postsynthetic sterol regulation, piecemeal microautophagy of the nucleus, and cell polarity establishment. Yeast Osh2p is proposed to function in sterol metabolism and cell polarity establishment. Both Osh1p and Osh2p contain 3 N-terminal ankyrin repeats, a PH domain, a FFAT motif (two phenylalanines in an acidic tract), and a C-terminal OSBP-related domain. OSBP andOsh1p PH domains specifically localize to the Golgi apparatus in a PtdIns4P-dependent manner. Oxysterol binding proteins are a multigene family that is conserved in yeast, flies, worms, mammals and plants. In general OSBPs and ORPs have been found to be involved in the transport and metabolism of cholesterol and related lipids in eukaryotes. They all contain a C-terminal oxysterol binding domain, and most contain an N-terminal PH domain. OSBP PH domains bind to membrane phosphoinositides and thus likely play an important role in intracellular targeting. They are members of the oxysterol binding protein (OSBP) family which includes OSBP, OSBP-related proteins (ORP), Goodpasture antigen binding protein (GPBP), and Four phosphate adaptor protein 1 (FAPP1). They have a wide range of purported functions including sterol transport, cell cycle control, pollen development and vessicle transport from Golgi recognize both PI lipids and ARF proteins. PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 241446 Cd Length: 103 Bit Score: 44.99 E-value: 3.02e-05
exonuclease SbcC; All proteins in this family for which functions are known are part of an ...
683-1149
3.48e-05
exonuclease SbcC; All proteins in this family for which functions are known are part of an exonuclease complex with sbcD homologs. This complex is involved in the initiation of recombination to regulate the levels of palindromic sequences in DNA. This family is based on the phylogenomic analysis of JA Eisen (1999, Ph.D. Thesis, Stanford University). [DNA metabolism, DNA replication, recombination, and repair]
Pssm-ID: 129705 [Multi-domain] Cd Length: 1042 Bit Score: 49.20 E-value: 3.48e-05
Grb2-associated binding protein family Pleckstrin homology (PH) domain; Gab proteins are ...
431-517
4.10e-05
Grb2-associated binding protein family Pleckstrin homology (PH) domain; Gab proteins are scaffolding adaptor proteins, which possess N-terminal PH domains and a C-terminus with proline-rich regions and multiple phosphorylation sites. Following activation of growth factor receptors, Gab proteins are tyrosine phosphorylated and activate PI3K, which generates 3-phosphoinositide lipids. By binding to these lipids via the PH domain, Gab proteins remain in proximity to the receptor, leading to further signaling. While not all Gab proteins depend on the PH domain for recruitment, it is required for Gab activity. There are 3 families: Gab1, Gab2, and Gab3. PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 270133 Cd Length: 112 Bit Score: 44.71 E-value: 4.10e-05
Alpha helical coiled-coil rod protein (HCR); This family consists of several mammalian alpha ...
677-1132
6.16e-05
Alpha helical coiled-coil rod protein (HCR); This family consists of several mammalian alpha helical coiled-coil rod HCR proteins. The function of HCR is unknown but it has been implicated in psoriasis in humans and is thought to affect keratinocyte proliferation.
Pssm-ID: 284517 [Multi-domain] Cd Length: 749 Bit Score: 48.21 E-value: 6.16e-05
Synaptonemal complex protein 1 (SCP-1); Synaptonemal complex protein 1 (SCP-1) is the major ...
1787-2271
6.84e-05
Synaptonemal complex protein 1 (SCP-1); Synaptonemal complex protein 1 (SCP-1) is the major component of the transverse filaments of the synaptonemal complex. Synaptonemal complexes are structures that are formed between homologous chromosomes during meiotic prophase.
Pssm-ID: 114219 [Multi-domain] Cd Length: 787 Bit Score: 48.18 E-value: 6.84e-05
Evectin Pleckstrin homology (PH) domain; There are 2 members of the evectin family (also ...
428-480
7.00e-05
Evectin Pleckstrin homology (PH) domain; There are 2 members of the evectin family (also called pleckstrin homology domain containing, family B): evt-1 (also called PLEKHB1) and evt-2 (also called PLEKHB2). evt-1 is specific to the nervous system, where it is expressed in photoreceptors and myelinating glia. evt-2 is widely expressed in both neural and nonneural tissues. Evectins possess a single N-terminal PH domain and a C-terminal hydrophobic region. evt-1 is thought to function as a mediator of post-Golgi trafficking in cells that produce large membrane-rich organelles. It is a candidate gene for the inherited human retinopathy autosomal dominant familial exudative vitreoretinopathy and a susceptibility gene for multiple sclerosis. evt-2 is essential for retrograde endosomal membrane transport from the plasma membrane (PM) to the Golgi. Two membrane trafficking pathways pass through recycling endosomes: a recycling pathway and a retrograde pathway that links the PM to the Golgi/ER. Its PH domain that is unique in that it specifically recognizes phosphatidylserine (PS), but not polyphosphoinositides. PS is an anionic phospholipid class in eukaryotic biomembranes, is highly enriched in the PM, and plays key roles in various physiological processes such as the coagulation cascade, recruitment and activation of signaling molecules, and clearance of apoptotic cells. PH domains are only found in eukaryotes. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 270085 Cd Length: 108 Bit Score: 44.22 E-value: 7.00e-05
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ...
895-1143
8.14e-05
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 48.13 E-value: 8.14e-05
rad50; All proteins in this family for which functions are known are involvedin recombination, ...
688-1137
9.50e-05
rad50; All proteins in this family for which functions are known are involvedin recombination, recombinational repair, and/or non-homologous end joining.They are components of an exonuclease complex with MRE11 homologs. This family is distantly related to the SbcC family of bacterial proteins.This family is based on the phylogenomic analysis of JA Eisen (1999, Ph.D. Thesis, Stanford University).
Pssm-ID: 129694 [Multi-domain] Cd Length: 1311 Bit Score: 48.12 E-value: 9.50e-05
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ...
1981-2246
1.00e-04
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 47.76 E-value: 1.00e-04
Protein of unknown function (DUF3584); This protein is found in bacteria and eukaryotes. ...
1869-2281
1.62e-04
Protein of unknown function (DUF3584); This protein is found in bacteria and eukaryotes. Proteins in this family are typically between 943 to 1234 amino acids in length. This family contains a P-loop motif suggesting it is a nucleotide binding protein. It may be involved in replication.
Pssm-ID: 432349 [Multi-domain] Cd Length: 1191 Bit Score: 47.14 E-value: 1.62e-04
Boi family Pleckstrin homology domain; Yeast Boi proteins Boi1 and Boi2 are functionally ...
430-519
2.15e-04
Boi family Pleckstrin homology domain; Yeast Boi proteins Boi1 and Boi2 are functionally redundant and important for cell growth with Boi mutants displaying defects in bud formation and in the maintenance of cell polarity.They appear to be linked to Rho-type GTPase, Cdc42 and Rho3. Boi1 and Boi2 display two-hybrid interactions with the GTP-bound ("active") form of Cdc42, while Rho3 can suppress of the lethality caused by deletion of Boi1 and Boi2. These findings suggest that Boi1 and Boi2 are targets of Cdc42 that promote cell growth in a manner that is regulated by Rho3. Boi proteins contain a N-terminal SH3 domain, followed by a SAM (sterile alpha motif) domain, a proline-rich region, which mediates binding to the second SH3 domain of Bem1, and C-terminal PH domain. The PH domain is essential for its function in cell growth and is important for localization to the bud, while the SH3 domain is needed for localization to the neck. PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 270126 Cd Length: 97 Bit Score: 42.36 E-value: 2.15e-04
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ...
674-976
2.64e-04
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 46.60 E-value: 2.64e-04
exonuclease SbcC; All proteins in this family for which functions are known are part of an ...
718-1139
2.80e-04
exonuclease SbcC; All proteins in this family for which functions are known are part of an exonuclease complex with sbcD homologs. This complex is involved in the initiation of recombination to regulate the levels of palindromic sequences in DNA. This family is based on the phylogenomic analysis of JA Eisen (1999, Ph.D. Thesis, Stanford University). [DNA metabolism, DNA replication, recombination, and repair]
Pssm-ID: 129705 [Multi-domain] Cd Length: 1042 Bit Score: 46.50 E-value: 2.80e-04
Synaptonemal complex protein 1 (SCP-1); Synaptonemal complex protein 1 (SCP-1) is the major ...
667-1092
3.33e-04
Synaptonemal complex protein 1 (SCP-1); Synaptonemal complex protein 1 (SCP-1) is the major component of the transverse filaments of the synaptonemal complex. Synaptonemal complexes are structures that are formed between homologous chromosomes during meiotic prophase.
Pssm-ID: 114219 [Multi-domain] Cd Length: 787 Bit Score: 45.87 E-value: 3.33e-04
General Receptor for Phosphoinositides-1-like Pleckstrin homology (PH) domain; GRP1/cytohesin3 ...
429-517
4.03e-04
General Receptor for Phosphoinositides-1-like Pleckstrin homology (PH) domain; GRP1/cytohesin3 and the related proteins ARNO (ARF nucleotide-binding site opener)/cytohesin-2 and cytohesin-1 are ARF exchange factors that contain a pleckstrin homology (PH) domain thought to target these proteins to cell membranes through binding polyphosphoinositides. The PH domains of all three proteins exhibit relatively high affinity for PtdIns(3,4,5)P3. Within the Grp1 family, diglycine (2G) and triglycine (3G) splice variants, differing only in the number of glycine residues in the PH domain, strongly influence the affinity and specificity for phosphoinositides. The 2G variants selectively bind PtdIns(3,4,5)P3 with high affinity,the 3G variants bind PtdIns(3,4,5)P3 with about 30-fold lower affinity and require the polybasic region for plasma membrane targeting. These ARF-GEFs share a common, tripartite structure consisting of an N-terminal coiled-coil domain, a central domain with homology to the yeast protein Sec7, a PH domain, and a C-terminal polybasic region. The Sec7 domain is autoinhibited by conserved elements proximal to the PH domain. GRP1 binds to the DNA binding domain of certain nuclear receptors (TRalpha, TRbeta, AR, ER, but not RXR), and can repress thyroid hormone receptor (TR)-mediated transactivation by decreasing TR-complex formation on thyroid hormone response elements. ARNO promotes sequential activation of Arf6, Cdc42 and Rac1 and insulin secretion. Cytohesin acts as a PI 3-kinase effector mediating biological responses including cell spreading and adhesion, chemotaxis, protein trafficking, and cytoskeletal rearrangements, only some of which appear to depend on their ability to activate ARFs. PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 269954 Cd Length: 119 Bit Score: 42.30 E-value: 4.03e-04
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ...
1776-2067
4.47e-04
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 45.82 E-value: 4.47e-04
Human Oxysterol binding protein and OSBP-related protein 4 Pleckstrin homology (PH) domain; ...
429-515
4.62e-04
Human Oxysterol binding protein and OSBP-related protein 4 Pleckstrin homology (PH) domain; Human OSBP is proposed to function is sterol-dependent regulation of ERK dephosphorylation and sphingomyelin synthesis as well as modulation of insulin signaling and hepatic lipogenesis. It contains a N-terminal PH domain, a FFAT motif (two phenylalanines in an acidic tract), and a C-terminal OSBP-related domain. OSBPs and Osh1p PH domains specifically localize to the Golgi apparatus in a PtdIns4P-dependent manner. ORP4 is proposed to function in Vimentin-dependent sterol transport and/or signaling. Human ORP4 has 2 forms, a long (ORP4L) and a short (ORP4S). ORP4L contains a N-terminal PH domain, a FFAT motif (two phenylalanines in an acidic tract), and a C-terminal OSBP-related domain. ORP4S is truncated and contains only an OSBP-related domain. Oxysterol binding proteins are a multigene family that is conserved in yeast, flies, worms, mammals and plants. They all contain a C-terminal oxysterol binding domain, and most contain an N-terminal PH domain. OSBP PH domains bind to membrane phosphoinositides and thus likely play an important role in intracellular targeting. They are members of the oxysterol binding protein (OSBP) family which includes OSBP, OSBP-related proteins (ORP), Goodpasture antigen binding protein (GPBP), and Four phosphate adaptor protein 1 (FAPP1). They have a wide range of purported functions including sterol transport, cell cycle control, pollen development and vessicle transport from Golgi recognize both PI lipids and ARF proteins. PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 270101 Cd Length: 99 Bit Score: 41.59 E-value: 4.62e-04
Grb2-associated binding protein family pleckstrin homology (PH) domain; The Gab subfamily ...
428-517
5.65e-04
Grb2-associated binding protein family pleckstrin homology (PH) domain; The Gab subfamily includes several Gab proteins, Drosophila DOS and C. elegans SOC-1. They are scaffolding adaptor proteins, which possess N-terminal PH domains and a C-terminus with proline-rich regions and multiple phosphorylation sites. Following activation of growth factor receptors, Gab proteins are tyrosine phosphorylated and activate PI3K, which generates 3-phosphoinositide lipids. By binding to these lipids via the PH domain, Gab proteins remain in proximity to the receptor, leading to further signaling. While not all Gab proteins depend on the PH domain for recruitment, it is required for Gab activity. Members here include insect, nematodes, and crustacean Gab2s. PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 241535 Cd Length: 115 Bit Score: 41.66 E-value: 5.65e-04
Bruton's tyrosine kinase pleckstrin homology (PH) domain; Btk is a member of the Tec family of ...
429-517
5.78e-04
Bruton's tyrosine kinase pleckstrin homology (PH) domain; Btk is a member of the Tec family of cytoplasmic protein tyrosine kinases that includes BMX, IL2-inducible T-cell kinase (Itk) and Tec. Btk plays a role in the maturation of B cells. Tec proteins general have an N-terminal PH domain, followed by a Tek homology (TH) domain, a SH3 domain, a SH2 domain and a kinase domain. The Btk PH domain binds phosphatidylinositol 3,4,5-trisphosphate and responds to signalling via phosphatidylinositol 3-kinase. The PH domain is also involved in membrane anchoring which is confirmed by the discovery of a mutation of a critical arginine residue in the BTK PH domain. This results in severe human immunodeficiency known as X-linked agammaglobulinemia (XLA) in humans and a related disorder is mice.PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 269944 [Multi-domain] Cd Length: 140 Bit Score: 42.22 E-value: 5.78e-04
RIM-binding protein of the cytomatrix active zone; This is a family of proteins that form part ...
774-1139
7.47e-04
RIM-binding protein of the cytomatrix active zone; This is a family of proteins that form part of the CAZ (cytomatrix at the active zone) complex which is involved in determining the site of synaptic vesicle fusion. The C-terminus is a PDZ-binding motif that binds directly to RIM (a small G protein Rab-3A effector). The family also contains four coiled-coil domains.
Pssm-ID: 431111 [Multi-domain] Cd Length: 766 Bit Score: 44.81 E-value: 7.47e-04
exonuclease SbcC; All proteins in this family for which functions are known are part of an ...
830-1105
8.98e-04
exonuclease SbcC; All proteins in this family for which functions are known are part of an exonuclease complex with sbcD homologs. This complex is involved in the initiation of recombination to regulate the levels of palindromic sequences in DNA. This family is based on the phylogenomic analysis of JA Eisen (1999, Ph.D. Thesis, Stanford University). [DNA metabolism, DNA replication, recombination, and repair]
Pssm-ID: 129705 [Multi-domain] Cd Length: 1042 Bit Score: 44.57 E-value: 8.98e-04
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and ...
1790-2177
1.39e-03
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and four light chains it is a fundamental contractile protein found in all eukaryote cell types. This family consists of the coiled-coil myosin heavy chain tail region. The coiled-coil is composed of the tail from two molecules of myosin. These can then assemble into the macromolecular thick filament. The coiled-coil region provides the structural backbone the thick filament.
Pssm-ID: 460256 [Multi-domain] Cd Length: 1081 Bit Score: 44.01 E-value: 1.39e-03
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ...
2050-2322
1.75e-03
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 43.90 E-value: 1.75e-03
Rho GTPase activating protein 25 and related proteins Pleckstrin homology (PH) domain; ...
429-519
1.77e-03
Rho GTPase activating protein 25 and related proteins Pleckstrin homology (PH) domain; RhoGAP25 (also called ArhGap25) like other RhoGaps are involved in cell polarity, cell morphology and cytoskeletal organization. They act as GTPase activators for the Rac-type GTPases by converting them to an inactive GDP-bound state and control actin remodeling by inactivating Rac downstream of Rho leading to suppress leading edge protrusion and promotes cell retraction to achieve cellular polarity and are able to suppress RAC1 and CDC42 activity in vitro. Overexpression of these proteins induces cell rounding with partial or complete disruption of actin stress fibers and formation of membrane ruffles, lamellipodia, and filopodia. This hierarchy contains RhoGAP22, RhoGAP24, and RhoGAP25. Members here contain an N-terminal PH domain followed by a RhoGAP domain and either a BAR or TATA Binding Protein (TBP) Associated Factor 4 (TAF4) domain. PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 270083 Cd Length: 114 Bit Score: 40.06 E-value: 1.77e-03
exonuclease SbcC; All proteins in this family for which functions are known are part of an ...
772-926
1.84e-03
exonuclease SbcC; All proteins in this family for which functions are known are part of an exonuclease complex with sbcD homologs. This complex is involved in the initiation of recombination to regulate the levels of palindromic sequences in DNA. This family is based on the phylogenomic analysis of JA Eisen (1999, Ph.D. Thesis, Stanford University). [DNA metabolism, DNA replication, recombination, and repair]
Pssm-ID: 129705 [Multi-domain] Cd Length: 1042 Bit Score: 43.80 E-value: 1.84e-03
RIM-binding protein of the cytomatrix active zone; This is a family of proteins that form part ...
2043-2186
1.98e-03
RIM-binding protein of the cytomatrix active zone; This is a family of proteins that form part of the CAZ (cytomatrix at the active zone) complex which is involved in determining the site of synaptic vesicle fusion. The C-terminus is a PDZ-binding motif that binds directly to RIM (a small G protein Rab-3A effector). The family also contains four coiled-coil domains.
Pssm-ID: 431111 [Multi-domain] Cd Length: 766 Bit Score: 43.66 E-value: 1.98e-03
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ...
1978-2242
2.29e-03
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 43.51 E-value: 2.29e-03
Apolipoprotein A1/A4/E domain; These proteins contain several 22 residue repeats which form a ...
1981-2157
3.01e-03
Apolipoprotein A1/A4/E domain; These proteins contain several 22 residue repeats which form a pair of alpha helices. This family includes: Apolipoprotein A-I. Apolipoprotein A-IV. Apolipoprotein E.
Pssm-ID: 460211 [Multi-domain] Cd Length: 175 Bit Score: 40.71 E-value: 3.01e-03
ArfGAP with coiled-coil, ankyrin repeat and PH domains Pleckstrin homology (PH) domain; ACAP ...
429-517
3.90e-03
ArfGAP with coiled-coil, ankyrin repeat and PH domains Pleckstrin homology (PH) domain; ACAP (also called centaurin beta) functions both as a Rab35 effector and as an Arf6-GTPase-activating protein (GAP) by which it controls actin remodeling and membrane trafficking. ACAP contain an NH2-terminal bin/amphiphysin/Rvs (BAR) domain, a phospholipid-binding domain, a PH domain, a GAP domain, and four ankyrin repeats. The AZAPs constitute a family of Arf GAPs that are characterized by an NH2-terminal pleckstrin homology (PH) domain and a central Arf GAP domain followed by two or more ankyrin repeats. On the basis of sequence and domain organization, the AZAP family is further subdivided into four subfamilies: 1) the ACAPs contain an NH2-terminal bin/amphiphysin/Rvs (BAR) domain (a phospholipid-binding domain that is thought to sense membrane curvature), a single PH domain followed by the GAP domain, and four ankyrin repeats; 2) the ASAPs also contain an NH2-terminal BAR domain, the tandem PH domain/GAP domain, three ankyrin repeats, two proline-rich regions, and a COOH-terminal Src homology 3 domain; 3) the AGAPs contain an NH2-terminal GTPase-like domain (GLD), a split PH domain, and the GAP domain followed by four ankyrin repeats; and 4) the ARAPs contain both an Arf GAP domain and a Rho GAP domain, as well as an NH2-terminal sterile-a motif (SAM), a proline-rich region, a GTPase-binding domain, and five PH domains. PMID 18003747 and 19055940 Centaurin can bind to phosphatidlyinositol (3,4,5)P3. PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 270070 Cd Length: 98 Bit Score: 38.74 E-value: 3.90e-03
Dedicator of cytokinesis-D subfamily Pleckstrin homology (PH) domain; DOCK-D subfamily (also called Zizimin subfamily) consists of Dock9/Zizimin1, Dock10/Zizimin3, and Dock11/Zizimin2. DOCK-D has a N-terminal DUF3398 domain, a PH-like domain, a Dock Homology Region 1, DHR1 (also called CZH1), a C2 domain, and a C-terminal DHR2 domain (also called CZH2). Zizimin1 is enriched in the brain, lung, and kidney; zizimin2 is found in B and T lymphocytes, and zizimin3 is enriched in brain, lung, spleen and thymus. Zizimin1 functions in autoinhibition and membrane targeting. Zizimin2 is an immune-related and age-regulated guanine nucleotide exchange factor, which facilitates filopodial formation through activation of Cdc42, which results in activation of cell migration. No function has been determined for Zizimin3 to date. The N-terminal half of zizimin1 binds to the GEF domain through three distinct areas, including CZH1, to inhibit the interaction with Cdc42. In addition its PH domain binds phosphoinositides and mediates zizimin1 membrane targeting. DOCK is a family of proteins involved in intracellular signalling networks. They act as guanine nucleotide exchange factors for small G proteins of the Rho family, such as Rac and Cdc42. There are 4 subfamilies of DOCK family proteins based on their sequence homology: A-D. PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 270087 Cd Length: 126 Bit Score: 39.62 E-value: 3.98e-03
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and ...
1797-2237
4.05e-03
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and four light chains it is a fundamental contractile protein found in all eukaryote cell types. This family consists of the coiled-coil myosin heavy chain tail region. The coiled-coil is composed of the tail from two molecules of myosin. These can then assemble into the macromolecular thick filament. The coiled-coil region provides the structural backbone the thick filament.
Pssm-ID: 460256 [Multi-domain] Cd Length: 1081 Bit Score: 42.47 E-value: 4.05e-03
Tandem PH-domain-containing protein 2 Pleckstrin homology (PH) domain; The binding of TAPP2 ...
429-517
4.49e-03
Tandem PH-domain-containing protein 2 Pleckstrin homology (PH) domain; The binding of TAPP2 (also called PLEKHA2) adaptors to PtdIns(3,4)P(2), but not PI(3,4, 5)P3, function as negative regulators of insulin and PI3K signalling pathways (i.e. TAPP/utrophin/syntrophin complex). TAPP2 contains two sequential PH domains in which the C-terminal PH domain specifically binds PtdIns(3,4)P2 with high affinity. The N-terminal PH domain does not interact with any phosphoinositide tested. They also contain a C-terminal PDZ-binding motif that interacts with several PDZ-binding proteins, including PTPN13 (known previously as PTPL1 or FAP-1) as well as the scaffolding proteins MUPP1 (multiple PDZ-domain-containing protein 1), syntrophin and utrophin. The members here are most sequence similar to TAPP2 proteins, but may not be actual TAPP2 proteins. PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 270075 Cd Length: 110 Bit Score: 38.93 E-value: 4.49e-03
Fungal proteins Pleckstrin homology (PH) domain, repeat 1; The functions of these fungal ...
428-517
5.06e-03
Fungal proteins Pleckstrin homology (PH) domain, repeat 1; The functions of these fungal proteins are unknown, but they all contain 2 PH domains. This cd represents the first PH repeat. PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 270110 Cd Length: 106 Bit Score: 38.76 E-value: 5.06e-03
KIFIA and KIFIB protein pleckstrin homology (PH) domain; The kinesin-3 family motors KIFIA ...
429-517
5.09e-03
KIFIA and KIFIB protein pleckstrin homology (PH) domain; The kinesin-3 family motors KIFIA (Caenorhabditis elegans homolog unc-104) and KIFIB transport synaptic vesicle precursors that contain synaptic vesicle proteins, such as synaptophysin, synaptotagmin and the small GTPase RAB3A, but they do not transport organelles that contain plasma membrane proteins. They have a N-terminal motor domain, followed by a coiled-coil domain, and a C-terminal PH domain. KIF1A adopts a monomeric form in vitro, but acts as a processive dimer in vivo. KIF1B has alternatively spliced isoforms distinguished by the presence or absence of insertion sequences in the conserved amino-terminal region of the protein; this results in their different motor activities. KIF1A and KIF1B bind to RAB3 proteins through the adaptor protein mitogen-activated protein kinase (MAPK) -activating death domain (MADD; also calledDENN), which was first identified as a RAB3 guanine nucleotide exchange factor (GEF). PH domains have diverse functions, but in general are involved in targeting proteins to the appropriate cellular location or in the interaction with a binding partner. They share little sequence conservation, but all have a common fold, which is electrostatically polarized. Less than 10% of PH domains bind phosphoinositide phosphates (PIPs) with high affinity and specificity. PH domains are distinguished from other PIP-binding domains by their specific high-affinity binding to PIPs with two vicinal phosphate groups: PtdIns(3,4)P2, PtdIns(4,5)P2 or PtdIns(3,4,5)P3 which results in targeting some PH domain proteins to the plasma membrane. A few display strong specificity in lipid binding. Any specificity is usually determined by loop regions or insertions in the N-terminus of the domain, which are not conserved across all PH domains. PH domains are found in cellular signaling proteins such as serine/threonine kinase, tyrosine kinases, regulators of G-proteins, endocytotic GTPases, adaptors, as well as cytoskeletal associated molecules and in lipid associated enzymes.
Pssm-ID: 269939 Cd Length: 103 Bit Score: 38.73 E-value: 5.09e-03
Domain of unknown function (DUF4618); This family of proteins is found in eukaryotes. Proteins ...
1976-2121
5.19e-03
Domain of unknown function (DUF4618); This family of proteins is found in eukaryotes. Proteins in this family are typically between 238 and 363 amino acids in length. There are two conserved sequence motifs: EYP and KCTPD.
Pssm-ID: 464704 [Multi-domain] Cd Length: 258 Bit Score: 41.09 E-value: 5.19e-03
exonuclease SbcC; All proteins in this family for which functions are known are part of an ...
1697-2282
5.89e-03
exonuclease SbcC; All proteins in this family for which functions are known are part of an exonuclease complex with sbcD homologs. This complex is involved in the initiation of recombination to regulate the levels of palindromic sequences in DNA. This family is based on the phylogenomic analysis of JA Eisen (1999, Ph.D. Thesis, Stanford University). [DNA metabolism, DNA replication, recombination, and repair]
Pssm-ID: 129705 [Multi-domain] Cd Length: 1042 Bit Score: 41.88 E-value: 5.89e-03
Mitochondrial inner membrane protein; Mitofilin controls mitochondrial cristae morphology. Mitofilin is enriched in the narrow space between the inner boundary and the outer membranes, where it forms a homotypic interaction and assembles into a large multimeric protein complex. The first 78 amino acids contain a typical amino-terminal-cleavable mitochondrial presequence rich in positive-charged and hydroxylated residues and a membrane anchor domain. In addition, it has three centrally located coiled coil domains.
Pssm-ID: 430783 [Multi-domain] Cd Length: 618 Bit Score: 41.67 E-value: 7.28e-03
DNA Topoisomerase I (eukaryota); DNA Topoisomerase I (eukaryota), DNA topoisomerase V, Vaccina ...
1971-2067
7.56e-03
DNA Topoisomerase I (eukaryota); DNA Topoisomerase I (eukaryota), DNA topoisomerase V, Vaccina virus topoisomerase, Variola virus topoisomerase, Shope fibroma virus topoisomeras
Pssm-ID: 214661 [Multi-domain] Cd Length: 391 Bit Score: 41.18 E-value: 7.56e-03
Golgin subfamily A member 5; Members of this family of proteins are involved in maintaining ...
2075-2188
8.21e-03
Golgin subfamily A member 5; Members of this family of proteins are involved in maintaining Golgi structure. They stimulate the formation of Golgi stacks and ribbons, and are involved in intra-Golgi retrograde transport. Two main interactions have been characterized: one with RAB1A that has been activated by GTP-binding and another with isoform CASP of CUTL1.
Pssm-ID: 462900 [Multi-domain] Cd Length: 305 Bit Score: 40.90 E-value: 8.21e-03
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of ...
718-1003
9.76e-03
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of Mycoplasma species. Members average 750 amino acids in length, including signal peptide. Sequences are predicted (Jpred 3) to be almost entirely alpha-helical. These sequences show strong periodicity (consistent with long alpha helical structures) and low complexity rich in D,E,N,Q, and K. Genes encoding these proteins are often found in tandem. The function is unknown.
Pssm-ID: 275316 [Multi-domain] Cd Length: 745 Bit Score: 41.16 E-value: 9.76e-03
Database: CDSEARCH/cdd Low complexity filter: no Composition Based Adjustment: yes E-value threshold: 0.01
References:
Wang J et al. (2023), "The conserved domain database in 2023", Nucleic Acids Res.51(D)384-8.
Lu S et al. (2020), "The conserved domain database in 2020", Nucleic Acids Res.48(D)265-8.
Marchler-Bauer A et al. (2017), "CDD/SPARCLE: functional classification of proteins via subfamily domain architectures.", Nucleic Acids Res.45(D)200-3.
of the residues that compose this conserved feature have been mapped to the query sequence.
Click on the triangle to view details about the feature, including a multiple sequence alignment
of your query sequence and the protein sequences used to curate the domain model,
where hash marks (#) above the aligned sequences show the location of the conserved feature residues.
The thumbnail image, if present, provides an approximate view of the feature's location in 3 dimensions.
Click on the triangle for interactive 3D structure viewing options.
Functional characterization of the conserved domain architecture found on the query.
Click here to see more details.
This image shows a graphical summary of conserved domains identified on the query sequence.
The Show Concise/Full Display button at the top of the page can be used to select the desired level of detail: only top scoring hits
(labeled illustration) or all hits
(labeled illustration).
Domains are color coded according to superfamilies
to which they have been assigned. Hits with scores that pass a domain-specific threshold
(specific hits) are drawn in bright colors.
Others (non-specific hits) and
superfamily placeholders are drawn in pastel colors.
if a domain or superfamily has been annotated with functional sites (conserved features),
they are mapped to the query sequence and indicated through sets of triangles
with the same color and shade of the domain or superfamily that provides the annotation. Mouse over the colored bars or triangles to see descriptions of the domains and features.
click on the bars or triangles to view your query sequence embedded in a multiple sequence alignment of the proteins used to develop the corresponding domain model.
The table lists conserved domains identified on the query sequence. Click on the plus sign (+) on the left to display full descriptions, alignments, and scores.
Click on the domain model's accession number to view the multiple sequence alignment of the proteins used to develop the corresponding domain model.
To view your query sequence embedded in that multiple sequence alignment, click on the colored bars in the Graphical Summary portion of the search results page,
or click on the triangles, if present, that represent functional sites (conserved features)
mapped to the query sequence.
Concise Display shows only the best scoring domain model, in each hit category listed below except non-specific hits, for each region on the query sequence.
(labeled illustration) Standard Display shows only the best scoring domain model from each source, in each hit category listed below for each region on the query sequence.
(labeled illustration) Full Display shows all domain models, in each hit category below, that meet or exceed the RPS-BLAST threshold for statistical significance.
(labeled illustration) Four types of hits can be shown, as available,
for each region on the query sequence:
specific hits meet or exceed a domain-specific e-value threshold
(illustrated example)
and represent a very high confidence that the query sequence belongs to the same protein family as the sequences use to create the domain model
non-specific hits
meet or exceed the RPS-BLAST threshold for statistical significance (default E-value cutoff of 0.01, or an E-value selected by user via the
advanced search options)
the domain superfamily to which the specific and non-specific hits belong
multi-domain models that were computationally detected and are likely to contain multiple single domains
Retrieve proteins that contain one or more of the domains present in the query sequence, using the Conserved Domain Architecture Retrieval Tool
(CDART).
Modify your query to search against a different database and/or use advanced search options