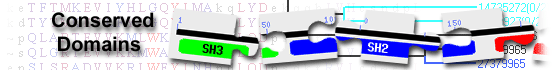


trinucleotide repeat-containing gene 6A protein isoform X5 [Mus musculus]
Protein Classification

TNRC6-PABC_bdg and RRM_TNRC6A domain-containing protein( domain architecture ID 11186870)
protein containing domains Ago_hook, M_domain, TNRC6-PABC_bdg, and RRM_TNRC6A
List of domain hits
| Name | Accession | Description | Interval | E-value | |||||
| TNRC6-PABC_bdg | pfam16608 | TNRC6-PABC binding domain; TNRC6-PABC_bdg is a natively unstructured region on the higher ... |
1476-1737 | 4.03e-101 | |||||
TNRC6-PABC binding domain; TNRC6-PABC_bdg is a natively unstructured region on the higher eukaryote TNRC6 subset of GW182 proteins that carries the binding motif for the interaction with Polyadenylate-binding protein 1, PABC. TNRC6 are trinucleotide repeat-containing gene 6 proteins required for miRNA-mediated gene silencing that are localized to the P bodies (processing bodies). P bodies are cytoplasmic mRNP aggregates that are involved in general mRNA translation repression and decay, including nonsense-mediated decay. Thus GW182 proteins are essential for microRNA-mediated translational repression and deadenylation in animal cells being a major component of miRISCs. The interaction motif that binds to PABC is ShNWPPEFHPGVPWKGLQ. This region lies between a Q-rich region and the RRM, or RNA-recognition motif, pfam13893. : Pssm-ID: 465195 Cd Length: 290 Bit Score: 326.56 E-value: 4.03e-101
|
|||||||||
| RRM_TNRC6A | cd12711 | RNA recognition motif (RRM) found in vertebrate GW182 autoantigen; This subgroup corresponds ... |
1745-1836 | 3.59e-55 | |||||
RNA recognition motif (RRM) found in vertebrate GW182 autoantigen; This subgroup corresponds to the RRM of the GW182 autoantigen, also termed trinucleotide repeat-containing gene 6A protein (TNRC6A), or CAG repeat protein 26, or EMSY interactor protein, or protein GW1, or glycine-tryptophan protein of 182 kDa, a phosphorylated cytoplasmic autoantigen involved in stabilizing and/or regulating translation and/or storing several different mRNAs. GW182 is characterized by multiple glycine/tryptophan (G/W) repeats and is a critical component of GW bodies (GWBs, also called mammalian processing bodies, or P bodies). The mRNAs associated with GW182 are presumed to reside within GWBs. GW182 has been shown to bind multiple Ago-miRNA complexes, and thus plays a key role in miRNA-mediated translational repression and mRNA degradation. In the absence of Ago2, GW182 may induce translational silencing effect. GW182 is composed of an N-terminal G/W-rich region containing an Ago hook responsible for Ago protein-binding; a ubiquitin-associated (UBA) domain and a glutamine (Q)-rich region in the middle region; a middle G/W-rich region, a RNA recognition motif (RRM), also termed RBD (RNA binding domain) or RNP (ribonucleoprotein domain), and a C-terminal G/W-rich region, at the C-terminus. A bipartite C-terminal region including the middle and C-terminal G/W-rich regions is referred to as silencing domain that triggers silencing of bound transcripts by inhibiting protein expression and promoting mRNA decay via deadenylation. : Pssm-ID: 410110 Cd Length: 92 Bit Score: 186.82 E-value: 3.59e-55
|
|||||||||
| Ago_hook super family | cl44598 | Argonaute hook; This region has been called the argonaute hook. It has been shown to bind to ... |
1069-1196 | 9.59e-12 | |||||
Argonaute hook; This region has been called the argonaute hook. It has been shown to bind to the Piwi domain pfam02171 of Argnonaute proteins. The actual alignment was detected with superfamily member pfam10427: Pssm-ID: 463088 [Multi-domain] Cd Length: 148 Bit Score: 64.68 E-value: 9.59e-12
|
|||||||||
| M_domain super family | cl15179 | M domain of GW182; |
1289-1451 | 1.71e-07 | |||||
M domain of GW182; The actual alignment was detected with superfamily member pfam12938: Pssm-ID: 432890 [Multi-domain] Cd Length: 243 Bit Score: 54.55 E-value: 1.71e-07
|
|||||||||
| ser_rich_anae_1 super family | cl41472 | serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 ... |
596-864 | 6.15e-05 | |||||
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 amino acids), which a highly serine-rich central region that averages over 300 aa in length. Species encoding members of this family of proteins tend to be anaerobic bacteria, including Gram-positive bacteria of the human gut microbiome and Chloroflexi from marine sediments. The actual alignment was detected with superfamily member NF033849: Pssm-ID: 468206 [Multi-domain] Cd Length: 1122 Bit Score: 48.08 E-value: 6.15e-05
|
|||||||||
| ser_rich_anae_1 super family | cl41472 | serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 ... |
399-687 | 7.30e-03 | |||||
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 amino acids), which a highly serine-rich central region that averages over 300 aa in length. Species encoding members of this family of proteins tend to be anaerobic bacteria, including Gram-positive bacteria of the human gut microbiome and Chloroflexi from marine sediments. The actual alignment was detected with superfamily member NF033849: Pssm-ID: 468206 [Multi-domain] Cd Length: 1122 Bit Score: 41.53 E-value: 7.30e-03
|
|||||||||
| Name | Accession | Description | Interval | E-value | |||||
| TNRC6-PABC_bdg | pfam16608 | TNRC6-PABC binding domain; TNRC6-PABC_bdg is a natively unstructured region on the higher ... |
1476-1737 | 4.03e-101 | |||||
TNRC6-PABC binding domain; TNRC6-PABC_bdg is a natively unstructured region on the higher eukaryote TNRC6 subset of GW182 proteins that carries the binding motif for the interaction with Polyadenylate-binding protein 1, PABC. TNRC6 are trinucleotide repeat-containing gene 6 proteins required for miRNA-mediated gene silencing that are localized to the P bodies (processing bodies). P bodies are cytoplasmic mRNP aggregates that are involved in general mRNA translation repression and decay, including nonsense-mediated decay. Thus GW182 proteins are essential for microRNA-mediated translational repression and deadenylation in animal cells being a major component of miRISCs. The interaction motif that binds to PABC is ShNWPPEFHPGVPWKGLQ. This region lies between a Q-rich region and the RRM, or RNA-recognition motif, pfam13893. Pssm-ID: 465195 Cd Length: 290 Bit Score: 326.56 E-value: 4.03e-101
|
|||||||||
| RRM_TNRC6A | cd12711 | RNA recognition motif (RRM) found in vertebrate GW182 autoantigen; This subgroup corresponds ... |
1745-1836 | 3.59e-55 | |||||
RNA recognition motif (RRM) found in vertebrate GW182 autoantigen; This subgroup corresponds to the RRM of the GW182 autoantigen, also termed trinucleotide repeat-containing gene 6A protein (TNRC6A), or CAG repeat protein 26, or EMSY interactor protein, or protein GW1, or glycine-tryptophan protein of 182 kDa, a phosphorylated cytoplasmic autoantigen involved in stabilizing and/or regulating translation and/or storing several different mRNAs. GW182 is characterized by multiple glycine/tryptophan (G/W) repeats and is a critical component of GW bodies (GWBs, also called mammalian processing bodies, or P bodies). The mRNAs associated with GW182 are presumed to reside within GWBs. GW182 has been shown to bind multiple Ago-miRNA complexes, and thus plays a key role in miRNA-mediated translational repression and mRNA degradation. In the absence of Ago2, GW182 may induce translational silencing effect. GW182 is composed of an N-terminal G/W-rich region containing an Ago hook responsible for Ago protein-binding; a ubiquitin-associated (UBA) domain and a glutamine (Q)-rich region in the middle region; a middle G/W-rich region, a RNA recognition motif (RRM), also termed RBD (RNA binding domain) or RNP (ribonucleoprotein domain), and a C-terminal G/W-rich region, at the C-terminus. A bipartite C-terminal region including the middle and C-terminal G/W-rich regions is referred to as silencing domain that triggers silencing of bound transcripts by inhibiting protein expression and promoting mRNA decay via deadenylation. Pssm-ID: 410110 Cd Length: 92 Bit Score: 186.82 E-value: 3.59e-55
|
|||||||||
| Ago_hook | pfam10427 | Argonaute hook; This region has been called the argonaute hook. It has been shown to bind to ... |
1069-1196 | 9.59e-12 | |||||
Argonaute hook; This region has been called the argonaute hook. It has been shown to bind to the Piwi domain pfam02171 of Argnonaute proteins. Pssm-ID: 463088 [Multi-domain] Cd Length: 148 Bit Score: 64.68 E-value: 9.59e-12
|
|||||||||
| M_domain | pfam12938 | M domain of GW182; |
1289-1451 | 1.71e-07 | |||||
M domain of GW182; Pssm-ID: 432890 [Multi-domain] Cd Length: 243 Bit Score: 54.55 E-value: 1.71e-07
|
|||||||||
| ser_rich_anae_1 | NF033849 | serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 ... |
596-864 | 6.15e-05 | |||||
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 amino acids), which a highly serine-rich central region that averages over 300 aa in length. Species encoding members of this family of proteins tend to be anaerobic bacteria, including Gram-positive bacteria of the human gut microbiome and Chloroflexi from marine sediments. Pssm-ID: 468206 [Multi-domain] Cd Length: 1122 Bit Score: 48.08 E-value: 6.15e-05
|
|||||||||
| ser_rich_anae_1 | NF033849 | serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 ... |
399-687 | 7.30e-03 | |||||
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 amino acids), which a highly serine-rich central region that averages over 300 aa in length. Species encoding members of this family of proteins tend to be anaerobic bacteria, including Gram-positive bacteria of the human gut microbiome and Chloroflexi from marine sediments. Pssm-ID: 468206 [Multi-domain] Cd Length: 1122 Bit Score: 41.53 E-value: 7.30e-03
|
|||||||||
| Name | Accession | Description | Interval | E-value | |||||
| TNRC6-PABC_bdg | pfam16608 | TNRC6-PABC binding domain; TNRC6-PABC_bdg is a natively unstructured region on the higher ... |
1476-1737 | 4.03e-101 | |||||
TNRC6-PABC binding domain; TNRC6-PABC_bdg is a natively unstructured region on the higher eukaryote TNRC6 subset of GW182 proteins that carries the binding motif for the interaction with Polyadenylate-binding protein 1, PABC. TNRC6 are trinucleotide repeat-containing gene 6 proteins required for miRNA-mediated gene silencing that are localized to the P bodies (processing bodies). P bodies are cytoplasmic mRNP aggregates that are involved in general mRNA translation repression and decay, including nonsense-mediated decay. Thus GW182 proteins are essential for microRNA-mediated translational repression and deadenylation in animal cells being a major component of miRISCs. The interaction motif that binds to PABC is ShNWPPEFHPGVPWKGLQ. This region lies between a Q-rich region and the RRM, or RNA-recognition motif, pfam13893. Pssm-ID: 465195 Cd Length: 290 Bit Score: 326.56 E-value: 4.03e-101
|
|||||||||
| RRM_TNRC6A | cd12711 | RNA recognition motif (RRM) found in vertebrate GW182 autoantigen; This subgroup corresponds ... |
1745-1836 | 3.59e-55 | |||||
RNA recognition motif (RRM) found in vertebrate GW182 autoantigen; This subgroup corresponds to the RRM of the GW182 autoantigen, also termed trinucleotide repeat-containing gene 6A protein (TNRC6A), or CAG repeat protein 26, or EMSY interactor protein, or protein GW1, or glycine-tryptophan protein of 182 kDa, a phosphorylated cytoplasmic autoantigen involved in stabilizing and/or regulating translation and/or storing several different mRNAs. GW182 is characterized by multiple glycine/tryptophan (G/W) repeats and is a critical component of GW bodies (GWBs, also called mammalian processing bodies, or P bodies). The mRNAs associated with GW182 are presumed to reside within GWBs. GW182 has been shown to bind multiple Ago-miRNA complexes, and thus plays a key role in miRNA-mediated translational repression and mRNA degradation. In the absence of Ago2, GW182 may induce translational silencing effect. GW182 is composed of an N-terminal G/W-rich region containing an Ago hook responsible for Ago protein-binding; a ubiquitin-associated (UBA) domain and a glutamine (Q)-rich region in the middle region; a middle G/W-rich region, a RNA recognition motif (RRM), also termed RBD (RNA binding domain) or RNP (ribonucleoprotein domain), and a C-terminal G/W-rich region, at the C-terminus. A bipartite C-terminal region including the middle and C-terminal G/W-rich regions is referred to as silencing domain that triggers silencing of bound transcripts by inhibiting protein expression and promoting mRNA decay via deadenylation. Pssm-ID: 410110 Cd Length: 92 Bit Score: 186.82 E-value: 3.59e-55
|
|||||||||
| RRM_TNRC6C | cd12713 | RNA recognition motif (RRM) found in vertebrate trinucleotide repeat-containing gene 6C ... |
1748-1832 | 1.08e-48 | |||||
RNA recognition motif (RRM) found in vertebrate trinucleotide repeat-containing gene 6C protein (TNRC6C); This subgroup corresponds to the RRM of TNRC6C, one of three GW182 paralogs in mammalian genomes. It is enriched in P-bodies and important for efficient miRNA-mediated repression. TNRC6C is composed of an N-terminal glycine/tryptophan (G/W)-rich region containing an Ago hook responsible for Ago protein-binding; a ubiquitin-associated (UBA) domain and a glutamine (Q)-rich region in the middle region; a middle G/W-rich region, a RNA recognition motif (RRM), also termed RBD (RNA binding domain) or RNP (ribonucleoprotein domain), and a C-terminal G/W-rich region, at the C-terminus. A bipartite C-terminal region including the middle and C-terminal G/W-rich regions is referred as silencing domain that triggers silencing of bound transcripts by inhibiting protein expression and promoting mRNA decay via deadenylation. The C-terminal half containing the RRM domain functions as a key effector domain mediating protein synthesis repression by TNRC6C. Pssm-ID: 410112 [Multi-domain] Cd Length: 88 Bit Score: 167.96 E-value: 1.08e-48
|
|||||||||
| RRM_TNRC6B | cd12712 | RNA recognition motif (RRM) found in vertebrate trinucleotide repeat-containing gene 6B ... |
1752-1832 | 2.33e-47 | |||||
RNA recognition motif (RRM) found in vertebrate trinucleotide repeat-containing gene 6B protein (TNRC6B); This subgroup corresponds to the RRM of TNRC6B, one of three GW182 paralogs in mammalian genomes. It is involved in miRNA-mediated mRNA degradation. TNRC6B is composed of an N-terminal glycine/tryptophan (G/W)-rich region; a ubiquitin-associated (UBA) domain and a glutamine (Q)-rich region in the middle region; a middle G/W-rich region, a RNA recognition motif (RRM), also termed RBD (RNA binding domain) or RNP (ribonucleoprotein domain), and a C-terminal G/W-rich region, at the C-terminus. TNRC6B directly interacts with Argonaute (Ago) proteins through its N-terminal glycine/tryptophan (G/W)-rich region that is called Ago protein-binding domain. TNRC6B is enriched in P-bodies and its Q-rich domain is responsible for P-body localization. A bipartite C-terminal region including the middle and C-terminal G/W-rich regions is referred as silencing domain that triggers silencing of bound transcripts by inhibiting protein expression and promoting mRNA decay via deadenylation. The C-terminal half of TNRC6B comprising an RRM domain exerts a strong translation inhibition potential, which does not require either association with Agos or localization to P-bodies. Pssm-ID: 410111 Cd Length: 83 Bit Score: 164.08 E-value: 2.33e-47
|
|||||||||
| RRM_GW182_like | cd12435 | RNA recognition motif (RRM) found in the GW182 family proteins; This subfamily corresponds to ... |
1750-1820 | 3.39e-47 | |||||
RNA recognition motif (RRM) found in the GW182 family proteins; This subfamily corresponds to the RRM of the GW182 family which includes three paralogs of TNRC6 (GW182-related) proteins comprising GW182/TNGW1, TNRC6B (containing three isoforms) and TNRC6C in mammal, a single Drosophila ortholog (dGW182, also called Gawky) and two Caenorhabditis elegans orthologs AIN-1 and AIN-2, which contain multiple miRNA-binding sites and have important functions in miRNA-mediated translational repression, as well as mRNA degradation in Metazoa. The GW182 family proteins directly interact with Argonaute (Ago) proteins, and thus function as downstream effectors in the miRNA pathway, responsible for inhibition of translation and acceleration of mRNA decay. Members in this family are characterized by an abnormally high content of glycine/tryptophan (G/W) repeats, one or more glutamine (Q)-rich motifs, and a C-terminal RNA recognition motif (RRM), also termed RBD (RNA binding domain) or RNP (ribonucleoprotein domain). The only exception is the worm protein that does not contain a recognizable RRM domain. The GW182 family proteins are recruited to miRNA targets through an interaction between their N-terminal domain and an Argonaute protein. Then they promote translational repression and/or degradation of miRNA targets through their C-terminal silencing domain. Pssm-ID: 409869 [Multi-domain] Cd Length: 71 Bit Score: 162.99 E-value: 3.39e-47
|
|||||||||
| Ago_hook | pfam10427 | Argonaute hook; This region has been called the argonaute hook. It has been shown to bind to ... |
1069-1196 | 9.59e-12 | |||||
Argonaute hook; This region has been called the argonaute hook. It has been shown to bind to the Piwi domain pfam02171 of Argnonaute proteins. Pssm-ID: 463088 [Multi-domain] Cd Length: 148 Bit Score: 64.68 E-value: 9.59e-12
|
|||||||||
| M_domain | pfam12938 | M domain of GW182; |
1289-1451 | 1.71e-07 | |||||
M domain of GW182; Pssm-ID: 432890 [Multi-domain] Cd Length: 243 Bit Score: 54.55 E-value: 1.71e-07
|
|||||||||
| ser_rich_anae_1 | NF033849 | serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 ... |
596-864 | 6.15e-05 | |||||
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 amino acids), which a highly serine-rich central region that averages over 300 aa in length. Species encoding members of this family of proteins tend to be anaerobic bacteria, including Gram-positive bacteria of the human gut microbiome and Chloroflexi from marine sediments. Pssm-ID: 468206 [Multi-domain] Cd Length: 1122 Bit Score: 48.08 E-value: 6.15e-05
|
|||||||||
| RRM_SF | cd00590 | RNA recognition motif (RRM) superfamily; RRM, also known as RBD (RNA binding domain) or RNP ... |
1753-1816 | 2.77e-04 | |||||
RNA recognition motif (RRM) superfamily; RRM, also known as RBD (RNA binding domain) or RNP (ribonucleoprotein domain), is a highly abundant domain in eukaryotes found in proteins involved in post-transcriptional gene expression processes including mRNA and rRNA processing, RNA export, and RNA stability. This domain is 90 amino acids in length and consists of a four-stranded beta-sheet packed against two alpha-helices. RRM usually interacts with ssRNA, but is also known to interact with ssDNA as well as proteins. RRM binds a variable number of nucleotides, ranging from two to eight. The active site includes three aromatic side-chains located within the conserved RNP1 and RNP2 motifs of the domain. The RRM domain is found in a variety heterogeneous nuclear ribonucleoproteins (hnRNPs), proteins implicated in regulation of alternative splicing, and protein components of small nuclear ribonucleoproteins (snRNPs). Pssm-ID: 409669 [Multi-domain] Cd Length: 72 Bit Score: 41.11 E-value: 2.77e-04
|
|||||||||
| ser_rich_anae_1 | NF033849 | serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 ... |
399-687 | 7.30e-03 | |||||
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 amino acids), which a highly serine-rich central region that averages over 300 aa in length. Species encoding members of this family of proteins tend to be anaerobic bacteria, including Gram-positive bacteria of the human gut microbiome and Chloroflexi from marine sediments. Pssm-ID: 468206 [Multi-domain] Cd Length: 1122 Bit Score: 41.53 E-value: 7.30e-03
|
|||||||||
| Blast search parameters | ||||
|
